La compressione è un'importante tecnica informatica utilizzata da programmi, servizi e utenti per risparmiare spazio e migliorare la qualità del servizio. Ad esempio, se scarichi un gioco tramite una piattaforma di gioco, generalmente scarica una versione compressa in modo da poter risparmiare tempo e spazio. La decompressione avviene dopo il download del file o durante il processo di installazione.
Ma perché ti sto dicendo tutto questo? Bene, oggi esaminerò la compressione dei file Linux e ti mostrerò tutto ciò che devi sapere.
Capire la compressione
Prima di andare avanti e conoscere la compressione di Linux, cerchiamo di capire più cose sulla compressione.
La compressione è una tecnica per ridurre la dimensione del file su un determinato disco utilizzando diversi calcoli e algoritmi matematici. Lo scopo principale della compressione è risparmiare spazio. Ciò è possibile nel modo in cui i file vengono archiviati sui dischi rigidi. Gli algoritmi o i calcoli matematici trovano un modello e comprimono quella parte di esso in modo che possa generarlo con poca o nessuna perdita di dettaglio. In breve, il contenuto ripetuto apre la strada al funzionamento della compressione.
Ci sono due tipi di compressione che dovresti conoscere. Sono la compressione Lossy e Lossless.
Compressione senza perdite
È una tecnica di compressione che non perde informazioni e i dati effettivi possono essere recuperati dal file compresso. La compressione con perdita è utile per ridurre le dimensioni del file senza perdere la qualità del file originale.
Compressione con perdita
D'altra parte è una tecnica di compressione con perdita che comprime un file per risparmiare spazio, ma il file compresso non può essere utilizzato per recuperare il contenuto del file originale. In questo caso, le informazioni vanno perse.
Per capirlo, facciamo un esempio. Puoi prendere un'immagine grezza e quindi comprimere usando la modalità con perdita e senza perdita di dati. Nella compressione senza perdita di dati, la dimensione dell'immagine diminuirà leggermente e sarai in grado di conservare l'immagine originale se decomprimi l'immagine. Nella maggior parte dei casi, viene utilizzato un formato PNG per la compressione senza perdita di dati. Tuttavia, se si utilizza la compressione con perdita, si otterrà un output dell'immagine che non può essere ripristinato a quello originale. In questo caso, l'immagine risultante è in formato JPEG/JPG.
Gli algoritmi di compressione sono eccellenti a modo loro e forniscono valore all'utente. Gli algoritmi più recenti utilizzano un metodo adattivo in cui sono veloci e più accurati nella loro tecnica di compressione.
Diversi modi di comprimere i file su Linux
Per comprendere la compressione in Linux, dobbiamo prima creare un file per testare i metodi di compressione. Per fare ciò, possiamo generare casualmente un file usando la seguente procedura.
base64 /dev/urandom | head -c 3000000 > mynewfile.txt
Per conoscere la dimensione del file appena creato, puoi eseguire il comando seguente.
ls -l --block-size=MB
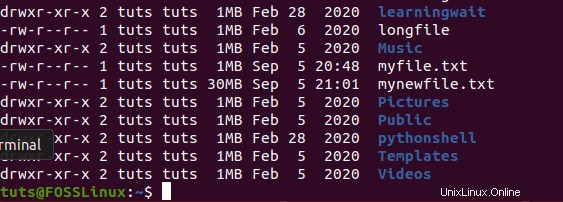
Puoi anche controllare la dimensione del file utilizzando Esplora file e controllando la dimensione del file nelle sue proprietà.
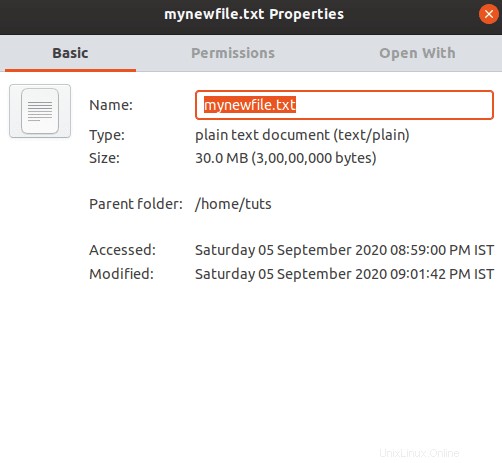
Creiamo più copie del file in modo da poterlo utilizzare per testare le tecniche di compressione.

La dimensione totale della cartella in cui sono archiviati i file è 150 MB.
Compressione zip
Una delle tecniche di compressione standard che troverai in Linux è la tecnica di compressione zip. Per eseguire il comando zip sui file che abbiamo, devi eseguire il seguente comando.
zip <output>.zip <input>
Quindi, per comprimere i cinque file che abbiamo nella cartella, dobbiamo eseguire il seguente comando.
zip testing1.zip *
Il comando richiederà del tempo per essere eseguito e lo vedrai accadere davanti ai tuoi occhi.
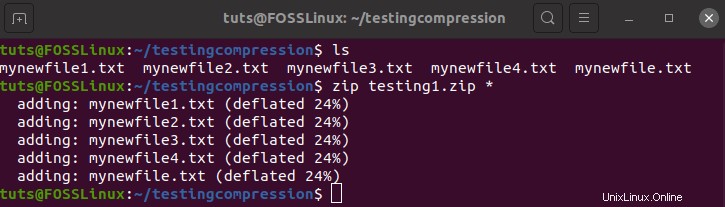
Come puoi vedere, ciascuno dei file è stato ridotto del 24%. Con un risparmio del 24%, la dimensione finale è di 114 MB. È abbastanza buono. Il risultato sarebbe stato diverso se avessimo utilizzato file sorgente aggiuntivi. Un'altra cosa che avresti notato è che utilizza la tecnica di compressione sgonfia.
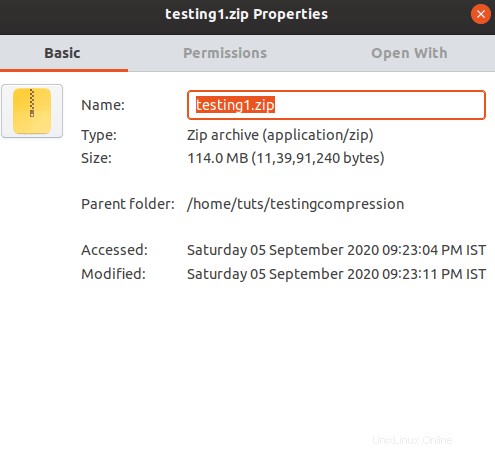
Per decomprimere il file, devi usare il seguente comando.
unzip
Come puoi vedere, puoi impostare una destinazione. Puoi anche decomprimere nella stessa cartella semplicemente usando il comando senza il parametro di destinazione.
Compressione Gzip
Ora che abbiamo eseguito la compressione zip, è giunto il momento della compressione GNU Zip o gzip. È anche un metodo popolare per comprimere i file su Linux. Jean-Loup Gailly e Mark Adler lo creano.
Inoltre, è migliore del metodo di compressione zip in quanto offre una compressione migliore. La sintassi per utilizzare la compressione Gzip è la seguente.
gzip <option> <input>
Per comprimere i file che abbiamo, dobbiamo usare il seguente comando.
gzip -v mynewfile1.txt
Questo comprimerà il file, "mynewfile1.txt", quindi lo chiamerà "mynewfile1.txt.gz".

La dimensione finale del file è 22,8 MB, che è una compressione piuttosto impressionante.
Puoi anche comprimere l'intera cartella usando il flag -r ricorsivo. La sintassi è la seguente:
gzip -r <folder_path>
Puoi anche personalizzare il livello di compressione per Gzip. Il valore del livello di compressione può essere impostato da 1 a 9. 1 sta per la compressione più veloce e meno, mentre nove sta per la compressione più lenta ma la migliore compressione.
gzip -v -9 mynewfile1.txt
Per decomprimere il file gzip, devi usare il seguente comando.
gzip -d <gzip_file>
Compressione Bzip2
L'ultimo tipo di compressione di cui parleremo è Bzip2. È uno strumento open source e gratuito. Utilizza l'algoritmo Burrows-Wheeler.
La tecnica di compressione è piuttosto vecchia poiché è stata introdotta per la prima volta nel 1996. Puoi usare Bzip2 nel tuo lavoro quotidiano. È veloce e funziona in modo simile a quello dello strumento gzip. La sintassi per la tecnica di compressione Bzip2 è la seguente:
bzip2 <option> <input>
Proviamo a comprimere il file usando bzip2.

Proprio come gzip, puoi anche impostare l'intensità della compressione da 1 a 9.
Per decomprimere il file, devi usare il seguente comando.
bzip2 -d <filename>
Archiviazione
C'è un altro termine importante che dobbiamo imparare qui.
L'archiviazione è il metodo per eseguire il backup dei dati in una posizione sicura utilizzando un formato compresso (generalmente). Nel server Linux, troverai l'estensione del file tar che significa che è un file archiviato. Il formato tar è eccellente quando si tratta di manipolare e indirizzare file diversi. Può mantenere intatti i metadati e le autorizzazioni e quindi viene utilizzato principalmente per scopi di archiviazione su sistemi Linux.
La sintassi del comando tar è la seguente.
tar <option> <output_file> <input>
Per estrarre, devi usare il seguente comando.
tar -xvf <archieved-file-name>
Conclusione
Questo ci porta alla fine della nostra guida alla compressione Linux. Come puoi vedere, ci sono molti modi per eseguire la compressione dei file. Inoltre, il processo di archiviazione ha il suo uso unico. Quindi, cosa ne pensi della compressione dei file Linux? Lo usi molto? Fatecelo sapere nei commenti qui sotto.