Se sei un utente o un appassionato di Linux da molto tempo, allora il termine swap o swap memory non dovrebbe essere una novità per te. Ma, sfortunatamente, molti utenti Linux tendono a confondere il concetto di memoria di scambio con lo swappiness. L'idea sbagliata più comune è che un valore di swappiness indichi la RAM massima utilizzabile prima dell'inizio del processo di scambio effettivo.
Per sfatare questo malinteso ampiamente riportato, dobbiamo scomporre sia la definizione di scambio che di scambio.
Riscattare lo scambio da idee sbagliate comuni
Da swappiness nasce il termine swapping. Affinché lo scambio avvenga, la RAM (Random Access Memory) deve disporre di alcuni dati di sistema. Quando questi dati vengono cancellati in una posizione del disco rigido dedicata come un file di scambio o una partizione di scambio, la RAM di sistema viene liberata dello spazio necessario. Questa liberazione della RAM di sistema costituisce la definizione di scambio.
Il tuo sistema operativo Linux contiene un'impostazione di configurazione del valore swappiness. L'esistenza di questo valore continua a generare molte idee sbagliate sulla funzionalità del sistema prevista. Il più comune è la sua associazione con la soglia di utilizzo della RAM. Dalla definizione di swapping, lo swappiness è frainteso come il valore massimo di memoria RAM che attiva l'inizio dello swapping.
Zone di divisione RAM
Per trovare chiarezza dall'idea sbagliata di swappiness discussa in precedenza, dobbiamo iniziare da dove è iniziata questa idea sbagliata. Innanzitutto, dobbiamo esaminare la memoria ad accesso casuale (RAM). La nostra interpretazione della RAM è molto diversa dalla percezione del sistema operativo Linux. Vediamo la RAM come una singola entità di memoria omogenea mentre Linux la interpreta come zone o regioni di memoria suddivise.
La disponibilità di queste zone sulla macchina dipende dall'architettura della macchina in uso. Ad esempio, potrebbe essere una macchina con architettura a 32 bit o una macchina con architettura a 64 bit. Per comprendere meglio questo concetto di zone divise, considera la seguente suddivisione e descrizioni delle zone del computer dell'architettura x86.
- Accesso diretto alla memoria (DMA) :qui, la regione di memoria allocabile o la capacità della zona è di soli 16 MB. Il suo nome è legato alla sua attuazione. I primi computer potevano comunicare con la memoria fisica di un computer solo attraverso l'approccio di accesso diretto alla memoria.
- Accesso diretto alla memoria 32 (DM A 32) :Indipendentemente da questa convenzione di denominazione assegnata, DMA32 è una zona di memoria applicabile solo a un'architettura Linux a 64 bit. In questo caso, la regione di memoria allocabile o la capacità della zona non supera i 4 GB. Pertanto, una macchina Linux alimentata a 32 bit può raggiungere solo 4 GB di RAM DMA. L'unica eccezione a questo caso è quando l'utente Linux decide di utilizzare il kernel PAE (Physical Address Extension).
- Normale :La proporzione di RAM della macchina superiore a 4 GB, secondo una stima, su un'architettura di computer a 64 bit, soddisfa la definizione metrica e i requisiti della memoria normale. D'altra parte, un'architettura di computer a 32 bit definisce la memoria normale tra 16 MB e 896 MB.
- Alto M loro :questa zona di memoria è evidente solo su un'architettura di computer basata su Linux a 32 bit. Si definisce come la capacità della RAM superiore a 896 MB per macchine piccole e superiore a 4 GB per macchine grandi o con caratteristiche e specifiche hardware performanti.
Valori RAM e PAGESIZE
L'allocazione della RAM del computer è determinata in pagine. L'allocazione di queste pagine è configurata su dimensioni fisse. Il kernel di sistema è il determinante di queste allocazioni a dimensione fissa. L'allocazione della pagina avviene al momento dell'avvio del sistema quando il kernel rileva l'architettura del tuo computer. Su un tale computer Linux, la dimensione tipica della pagina è di circa 4 Kbyte.
Per determinare la dimensione della pagina della tua macchina Linux, puoi utilizzare il comando "getconf" come mostrato di seguito:
$ getconf PAGESIZE
L'esecuzione del comando sopra sul tuo terminale dovrebbe darti un output come:
4096
Allegati zone e nodi
Le zone di memoria discusse hanno un collegamento diretto ai nodi di sistema. La CPU o l'Unità di elaborazione centrale si associa direttamente a questi nodi. Questa associazione nodo-CPU a cui fa riferimento il kernel di sistema durante l'allocazione della memoria è necessaria per un processo pianificato per l'esecuzione da parte della stessa CPU.
Questi livelli da nodo a CPU sono essenziali per l'installazione di tipi di memoria misti. I computer specializzati multi-CPU sono l'obiettivo principale di queste installazioni di memoria. Questa procedura ha esito positivo solo quando è in uso l'architettura di accesso alla memoria non uniforme.
Con tali requisiti di fascia alta, un computer Linux, in media, si assocerà a un nodo specifico. Il termine del sistema operativo per esso è il nodo zero. Questo nodo possiede tutte le zone di memoria disponibili. È possibile accedere a questi nodi e zone anche dal sistema operativo Linux. Innanzitutto, dovrai accedere al file "/proc/buddyinfo". Puoi utilizzare il seguente comando per raggiungere questo obiettivo.
$ less /proc/buddyinfo
L'output del tuo terminale dovrebbe essere simile allo screenshot seguente.
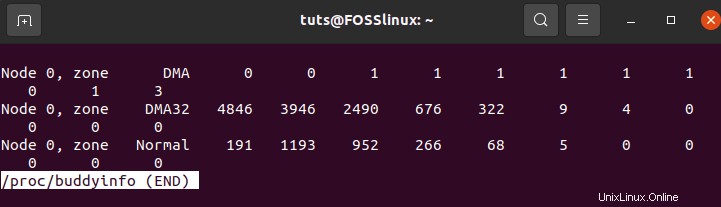
Come puoi vedere, dalla mia parte, ho a che fare con tre zone:DMA, DMA32 e zone Normali.
L'interpretazione dei dati di queste zone è semplice. Ad esempio, se andiamo con la zona DMA32, possiamo svelare alcune informazioni critiche. Spostandoci da sinistra a destra, possiamo rivelare quanto segue:
4846: I blocchi di memoria disponibili possono essere interpretati come 4846 di 2^(0*PAGESIZE)
3946: I blocchi di memoria disponibili possono essere interpretati come 3946 di 2^(1*PAGESIZE)
2490: I blocchi di memoria disponibili possono essere interpretati come 2490 di 2^(2*PAGESIZE)
...
0: I blocchi di memoria disponibili possono essere interpretati come 0 di 2^(512*PAGESIZE)
Le informazioni di cui sopra chiariscono come i nodi e le zone si relazionano tra loro.
Pagine di file e pagine anonime
Le voci della tabella delle pagine forniscono la funzionalità di mappatura della memoria con i mezzi necessari per registrare l'utilizzo di pagine di memoria specifiche. Per questo motivo, la mappatura della memoria esiste nelle seguenti fasi funzionali:
File supportato: Con questo tipo di mappatura, i dati che esistono qui provengono da un file. La mappatura non limita la sua funzionalità a tipi di file specifici. Qualsiasi tipo di file è utilizzabile fintanto che la funzione di mappatura può leggere i dati da esso. La flessibilità di questa funzionalità di sistema è che una memoria liberata dal sistema può essere facilmente recuperata e i suoi dati riutilizzati fintanto che il file contenente i dati rimane leggibile.
Se per caso si verificano modifiche ai dati nella memoria, il file del disco rigido dovrà registrare le modifiche ai dati. Dovrebbe aver luogo prima che la memoria in uso sia di nuovo libera. Se questa precauzione non viene eseguita, il file del disco rigido non annoterà le modifiche ai dati che si sono verificate in memoria.
Anonimo: Questo tipo di tecnica di mappatura della memoria non ha funzionalità di backup di file o dispositivi. Le richieste di memoria disponibili su queste pagine possono essere descritte come al volo e vengono avviate da programmi che necessitano urgentemente di conservare i dati. Tali richieste di memoria sono efficaci anche quando si tratta di stack e heap di memoria.
Poiché questi tipi di dati non sono associati ai file, la loro natura anonima ha bisogno di qualcosa che funga da posizione di archiviazione affidabile istantaneamente. In questo caso, viene creata una partizione di scambio o un file di scambio per contenere questi dati del programma. I dati verranno prima spostati per lo scambio prima che le pagine anonime che contenevano questi dati vengano liberate.
Dispositivo supportato: I file di dispositivo a blocchi vengono utilizzati per indirizzare i dispositivi di sistema. Il sistema considera i file del dispositivo come normali file di sistema. Qui è possibile sia la lettura che la scrittura dei dati. I dati di archiviazione del dispositivo facilitano e avviano la mappatura della memoria supportata dal dispositivo.
Condiviso: Una singola pagina RAM può ospitare o può essere mappata con più voci di tabella di pagina. Qualsiasi di queste mappature può essere utilizzata per accedere alle posizioni di memoria disponibili. Qualunque sia il percorso di mappatura, la visualizzazione dei dati finali sarà sempre la stessa. Poiché le posizioni di memoria qui sono osservate congiuntamente, la comunicazione tra processi è più efficiente attraverso lo scambio di dati. Anche le comunicazioni tra processi sono altamente performanti grazie alle mappature scrivibili condivise.
Copia su scrittura: Questa tecnica di allocazione è alquanto pigramente orientata. Se si verifica una richiesta di risorsa e la risorsa richiesta esiste già in memoria, la risorsa originale viene mappata per soddisfare tale richiesta. Inoltre, la risorsa potrebbe essere condivisa da altri processi multipli.
In questi casi, un processo potrebbe tentare di scrivere su quella risorsa. Se questa operazione di scrittura deve avere esito positivo, in memoria dovrebbe esistere una replica di tale risorsa. La copia o la replica della risorsa conterrà ora le modifiche apportate. In breve, è questo primo comando di scrittura che avvia ed esegue l'allocazione della memoria.
Di questi cinque approcci di mappatura della memoria discussi, lo swappiness si occupa di pagine supportate da file e routine di mappatura della memoria di pagine anonime. Quindi, sono le prime due tecniche di mappatura della memoria discusse.
Capire lo scambio
Sulla base di ciò che abbiamo trattato e discusso finora, la definizione di swappiness può ora essere facilmente compresa.
In termini semplici, lo swappiness è un meccanismo di controllo del sistema che descrive in dettaglio l'intensità dell'aggressività del kernel di sistema nello scambio di pagine di memoria. Un valore swappiness viene utilizzato per identificare questo livello di aggressività del kernel di sistema. Una maggiore aggressività del kernel è indicata da valori di swappiness più elevati, mentre l'importo di swap diminuirà con valori più bassi.
Quando il suo valore è a 0, il kernel non dispone dell'autenticazione per avviare lo scambio. Invece, il kernel fa riferimento alle pagine libere e supportate da file prima di avviare lo scambio. Pertanto, quando si confronta lo swappiness con lo swap, lo swappiness è responsabile della misurazione intensiva dello scambio su e giù. È interessante notare che un valore di swappiness impostato a zero non impedisce lo scambio. Invece, blocca lo scambio solo mentre il kernel di sistema attende che alcune condizioni di scambio siano praticabili.
Github fornisce una descrizione del codice sorgente più convincente e valori associati all'implementazione di swappiness. Per definizione, il suo valore predefinito è rappresentato con la seguente dichiarazione e inizializzazione della variabile.
Int vm_swappiness = 60;
Gli intervalli di valori di swappiness sono compresi tra 0 e 100. Il collegamento Github sopra punta al codice sorgente per la sua implementazione.
Il valore di scambio ideale
Diversi fattori determinano il valore di swappiness ideale per un sistema Linux. Includono il tipo di disco rigido del computer, l'hardware, il carico di lavoro e se è progettato per funzionare come server o computer desktop.
È inoltre necessario notare che il ruolo principale dello scambio non è avviare un meccanismo di liberazione della memoria per la RAM di una macchina quando lo spazio di memoria disponibile si sta esaurendo. L'esistenza dello swap è, per impostazione predefinita, un indicatore di un buon funzionamento del sistema. La sua assenza implicherebbe che il tuo sistema Linux debba aderire a folli routine di gestione della memoria.
L'effetto dell'implementazione di un valore di swappiness nuovo o personalizzato su un sistema operativo Linux è istantaneo. Elimina la necessità di un riavvio del sistema. Pertanto, questa finestra è un'opportunità per regolare e monitorare gli effetti del nuovo valore di swappiness. Questi aggiustamenti del valore e il monitoraggio del sistema dovrebbero aver luogo per un periodo di giorni e settimane fino a quando non arrivi a un numero che non influisca sulle prestazioni e sullo stato di salute del tuo sistema operativo Linux.
Durante la regolazione del valore di swappiness, considera i seguenti suggerimenti:
- In primo luogo, l'implementazione di 0 come valore di scambio impostato non disabilita la funzionalità di scambio. Al contrario, l'attività del disco rigido del sistema cambia da associata a swap a associata a file.
- Se si lavora con dischi rigidi del computer vecchi o obsoleti, si consiglia di ridurre il valore di swappiness di Linux associato. Ridurrà al minimo gli effetti dell'abbandono della partizione di scambio e impedirà anche il ripristino anonimo della pagina. L'abbandono del file system aumenterà quando si riduce l'abbandono dello scambio. Con l'aumento di un'impostazione che causa la diminuzione di un'altra, il tuo sistema Linux sarà più sano e performante con un metodo di gestione della memoria efficace invece di produrre prestazioni medie con due metodi.
- I server di database e altri server monouso dovrebbero disporre di linee guida software dai loro fornitori. Sono dotati di una gestione affidabile della memoria e di meccanismi di cache dei file appositamente progettati. I fornitori di questo software sono obbligati a suggerire un valore di swappiness Linux consigliato in base al carico di lavoro e alle specifiche della macchina.
- Se sei un utente desktop Linux medio, è consigliabile attenersi al valore di swappiness già impostato, soprattutto se stai utilizzando hardware ragionevolmente recente.
Lavorare con il valore di swappiness personalizzato sulla tua macchina Linux
Puoi modificare il tuo valore di swappiness di Linux in una cifra personalizzata a tua scelta. Innanzitutto, devi conoscere il valore attualmente impostato. Ti darà un'idea di quanto desideri ridurre o aumentare il valore di swappiness impostato nel sistema. Puoi controllare il valore attualmente impostato sulla tua macchina Linux con il seguente comando.
$ cat /proc/sys/vm/swappiness
Dovresti ottenere un valore come 60 poiché è l'impostazione predefinita del sistema.

Il "sysctl" è utile quando è necessario modificare questo valore di swappiness con una nuova cifra. Ad esempio, possiamo cambiarlo in 50 con il seguente comando.
$ sudo sysctl vm.swappiness=50
Il tuo sistema Linux rileverà immediatamente questo valore appena impostato senza bisogno di alcun riavvio. Il riavvio della macchina ripristina questo valore al valore predefinito 60. L'uso del comando precedente è temporaneo a causa di un motivo principale. Consente agli utenti Linux di sperimentare i valori di swappiness che hanno in mente prima di decidere su uno fisso che intendono utilizzare in modo permanente.
Se si desidera che il valore di swappiness sia persistente anche dopo un riavvio del sistema riuscito, sarà necessario per includere il suo valore impostato nel file di configurazione di sistema “/etc/sysctl.conf”. Per la dimostrazione, considera la seguente implementazione di questo caso discusso tramite l'editor nano. Ovviamente puoi usare qualsiasi editor supportato da Linux a tua scelta.
$ sudo nano /etc/sysctl.conf
Quando questo file di configurazione si apre sull'interfaccia del tuo terminale, scorri fino in fondo e aggiungi una riga di dichiarazione di variabile contenente il tuo valore di swappiness. Considera la seguente implementazione.
vm.swappiness=50
Salva questo file e sei a posto. Il prossimo riavvio del sistema utilizzerà questo nuovo valore di swappiness impostato.
Nota finale
La complessità della gestione della memoria lo rende un ruolo ideale per il kernel di sistema poiché sarebbe un mal di testa per l'utente medio di Linux. Poiché lo swappiness è associato alla gestione della memoria, potresti sovrastimare o pensare di utilizzare troppa RAM. D'altra parte, Linux trova la RAM libera ideale per ruoli di sistema come la memorizzazione nella cache del disco. In questo caso, il valore della memoria "libera" sarà artificialmente inferiore e il valore della memoria "usata" artificialmente superiore.
In pratica, questa proporzionalità dei valori di memoria libera e utilizzata è usa e getta. Motivo? La RAM libera che si assegna come cache del disco è recuperabile in qualsiasi istanza di sistema. È perché il kernel di sistema lo contrassegnerà come spazio di memoria disponibile e riutilizzabile.