Una volta entrato nel dominio del sistema operativo Linux, l'elenco delle possibilità di elaborazione tramite l'ambiente della riga di comando Linux sembrerà infinito. È semplicemente perché più usi Linux, più vuoi imparare e questa brama ti porta attraverso innumerevoli opportunità di apprendimento.
In questo tutorial, esamineremo il conteggio e la stampa di righe duplicate in un file di testo in un ambiente con sistema operativo Linux. Questo modulo tutorial fa parte della gestione dei file di Linux.
La riga di comando di Linux o l'ambiente del terminale non sono nuovi per l'elaborazione di file di testo di input. È così abile in tali operazioni che deve ancora affrontare una sfida degna nell'elaborazione di file di testo.
Questo tutorial farà luce sull'identificazione/gestione delle righe duplicate all'interno di file di testo casuali in Linux.
Dichiarazione del problema
Per rendere questo tutorial più semplice e interessante, creeremo un file di testo di esempio che fungerà da file casuale di cui vogliamo verificare l'esistenza di righe duplicate.
$ sudo nano sample_file.txt
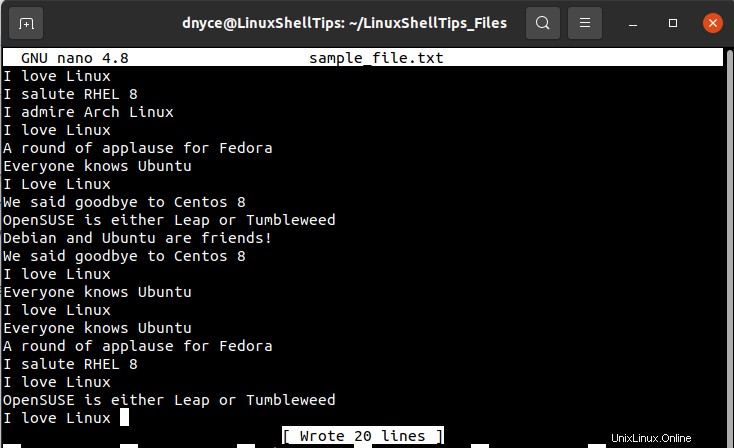
Semplicemente scansionando l'acquisizione dello schermo del file di testo sopra, dovremmo essere in grado di notare l'esistenza di alcune righe duplicate ma non possiamo essere certi del loro numero esatto di occorrenze.
Per essere certi del numero di righe duplicate che si verificano, troveremo le nostre soluzioni dai seguenti approcci Linux basati su riga di comando/terminale:
Trova le righe duplicate nel file usando i comandi sort e uniq
La comodità di utilizzare uniq il comando è che viene fornito con -c opzione di comando. Tuttavia, questa opzione di comando è valida solo se il file di testo che stai prendendo di mira/scansionando ha righe adiacenti duplicate.
Per evitare questo inconveniente durante l'utilizzo di uniq comando per stampare righe duplicate dobbiamo prendere in prestito l'approccio del comando di ordinamento di raggruppare righe ripetute/duplicate all'interno di un file di testo mirato.
In breve, passeremo prima il file di testo di destinazione tramite il ordinamento comando e successivamente reindirizzarlo a uniq comando che sarà poi accompagnato dal -c opzione di comando come mostrato di seguito:
$ sort sample_file.txt | uniq -c
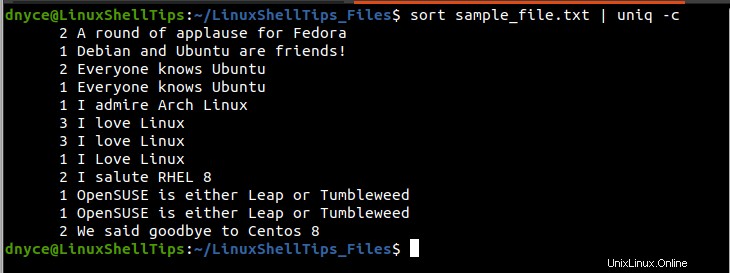
La prima colonna (a sinistra) dell'output sopra indica il numero di volte in cui le righe stampate sulla colonna di destra compaiono all'interno del file_campione.txt file di testo. Ad esempio, la frase "I love Linux" viene duplicato/ripetuto (3+3+1) volte all'interno del file di testo per un totale di 7 volte.
Stampa righe duplicate nel file utilizzando il comando Awk
Il awk comando per risolvere questo "stampa righe duplicate in un file di testo Il problema è un semplice one-liner. Per capire come funziona, dobbiamo prima implementarlo come mostrato di seguito:
$ awk '{ a[$0]++ } END{ for(x in a) print a[x], x }' sample_file.txt
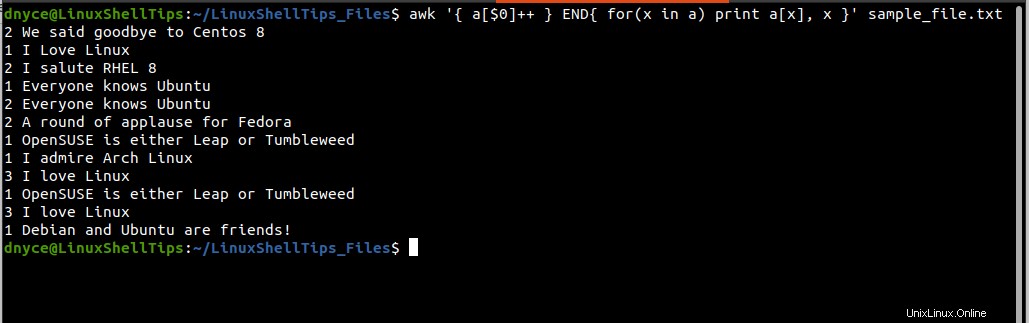
L'esecuzione del comando precedente genera due colonne, la prima colonna conta il numero di volte in cui una riga ripetuta/duplicata appare all'interno del file di testo e la seconda colonna punta alla riga in questione.
Tuttavia, l'output del comando precedente non è organizzato come quello in ordina e uniq comandi.
Abbiamo spiegato con successo come stampare righe duplicate in un file di testo in un ambiente con sistema operativo Linux.