Dal momento che è già stabilito che il sistema operativo Linux è il tuttofare informatico attraverso i numerosi suggerimenti e articoli sulla riga di comando di Linux che hai trovato su questo sito.
È tempo di accrescere ulteriormente la reputazione di questo sistema operativo. Come parte della gestione dei file Linux, esamineremo modi per mescolare le righe in un file che risiede in un ambiente del sistema operativo Linux.
Riordinare le righe in un file in un ambiente del sistema operativo Linux può richiedere due approcci. Nell'approccio uno, potresti cercare di mischiare/riordinare le righe in un file di destinazione in modo che appaia in un ordine richiesto specifico. In tal caso, viene richiamato un comando di ordinamento.
Nell'approccio 2, non sei consapevole dell'ordine in cui dovrebbero apparire le righe finali nel file di destinazione. In questi casi, un comando shuf è chiamato.
Questo articolo ci guiderà attraverso diverse tecniche Linux di mescolare casualmente le righe in un file in Linux.
Dichiarazione del problema
Avremo bisogno di creare un file di testo di esempio con poche righe a cui faremo riferimento durante l'implementazione e l'esecuzione di vari comandi di mescolamento Linux da discutere.
$ sudo nano sample_file.txt
Possiamo usare il comando cat per la vista numerata di questo intero file:
$ cat -n sample_file.txt
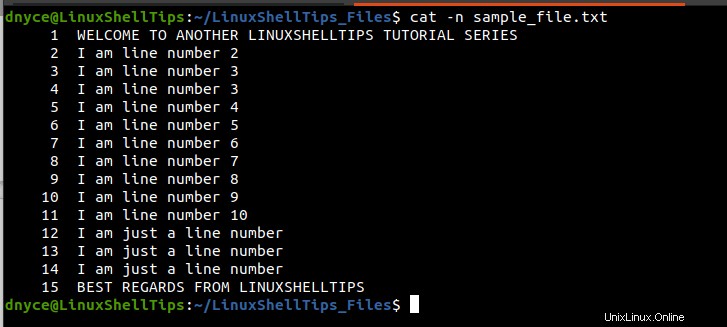
Il comando cat l'output ci dice che abbiamo a che fare con un file di testo con un totale di 15 Linee. Inoltre, come avrai notato, righe 12 a 14 sono ripetitivi. L'occorrenza di queste tre righe ci aiuterà a capire come funzionano i diversi comandi di mescolamento.
Rimescolamento delle righe utilizzando il comando Shuf in Linux
Dal momento che le GNU Coreutils host del pacchetto shuf comando, dovrebbe essere installato per impostazione predefinita nella distribuzione del tuo sistema operativo Linux. La funzione principale di shuf il comando consiste nel generare permutazioni casuali in base a un input fornitogli.
Il meccanismo di funzionamento di shuf il comando è il seguente; prima carica i dati di input in memoria, fa riferimento se la memoria libera è maggiore dei dati di input/dimensione del file prima di procedere con la sua esecuzione.
La sua sintassi è la seguente:
$ shuf [TARGET_INPUT_FILE]
Nel nostro caso, la sua implementazione sarà la seguente:
$ shuf sample_file.txt
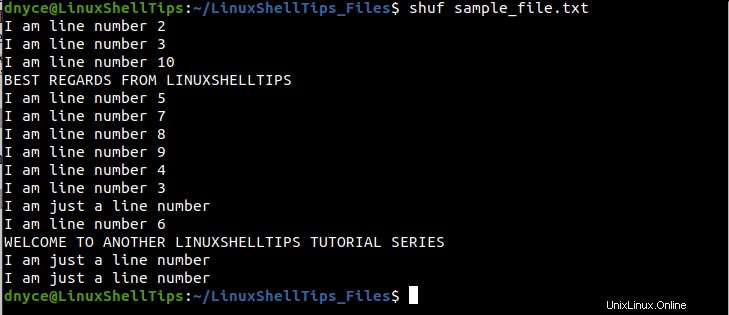
Come puoi vedere, siamo riusciti a mescolare casualmente le righe nel nostro file di testo di esempio. Se esegui shuf comando, ancora e ancora, otterrai ogni volta un risultato diverso:
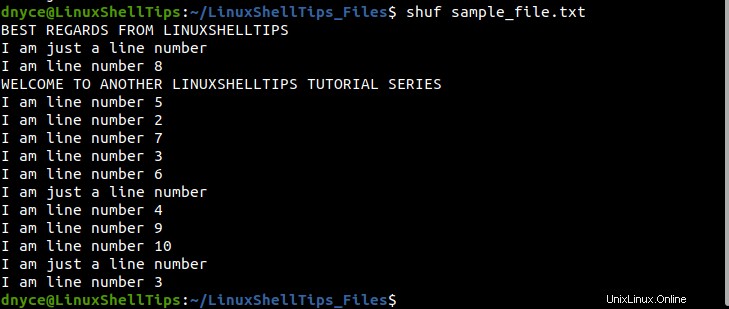
$ shuf random_file.txt
Usa il comando di ordinamento per mescolare le righe in Linux
Mentre il ordinamento comando viene utilizzato principalmente per riorganizzare le righe di un file in un modo specifico, possiamo randomizzare queste righe di file se combiniamo il ordinamento comando con il -R opzione.
$ sort -R sample_file.txt
L'esecuzione del comando più e più volte dovrebbe produrre risultati diversi ogni volta.
Usa il comando Awk per mescolare le righe di file in Linux
Secondo la sua pagina man di Linux (man awk ), awk è un perfetto linguaggio di programmazione per la scansione di modelli e l'elaborazione del testo. Tuttavia, per comprendere il suo utilizzo nelle righe di rimescolamento, avrai bisogno di una certa esposizione a concetti di programmazione come variabili, loop (while loop) e istruzioni (if istruzione) come mostrato di seguito:
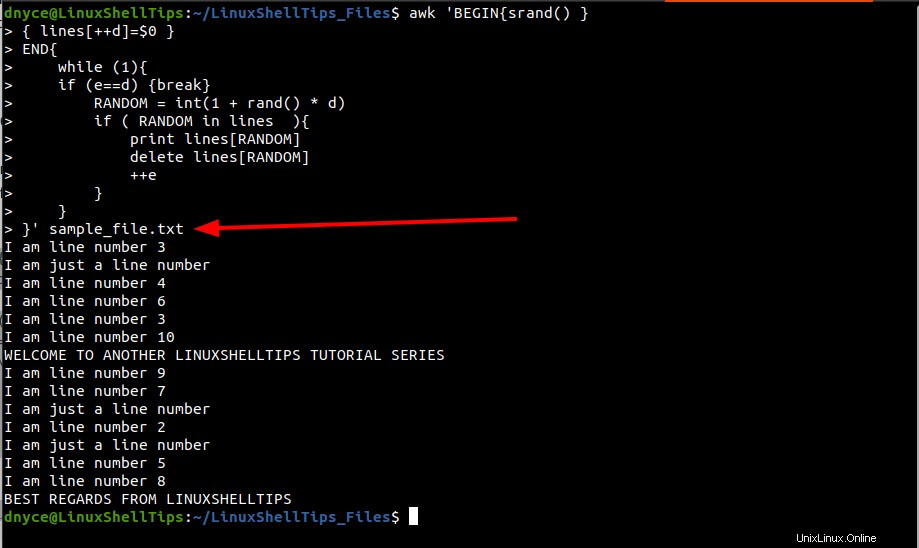
awk 'BEGIN{srand() }
{ lines[++d]=$0 }
END{
while (1){
if (e==d) {break}
RANDOM = int(1 + rand() * d)
if ( RANDOM in lines ){
print lines[RANDOM]
delete lines[RANDOM]
++e
}
}
}' sample_file.txt
Ora siamo a nostro agio con la mescolanza delle righe in un file in Linux.