Questo articolo esamina il monte namespace ed è il terzo della serie Linux Namespace. Nel primo articolo, ho fornito un'introduzione ai sette spazi dei nomi più comunemente usati, gettando le basi per il lavoro pratico iniziato nell'articolo sugli spazi dei nomi utente. Il mio obiettivo è sviluppare alcune conoscenze fondamentali su come funzionano le basi dei container Linux. Se sei interessato a come Linux controlla le risorse su un sistema, dai un'occhiata alla serie CGroup, che ho scritto prima. Se tutto va bene, quando avrai finito con il lavoro pratico sugli spazi dei nomi, sarò in grado di collegare insieme CGroup e spazi dei nomi in modo significativo, completando il quadro per te.
Per ora, tuttavia, questo articolo esamina lo spazio dei nomi di montaggio e come può aiutarti ad avvicinarti alla comprensione dell'isolamento che i container Linux apportano agli amministratori di sistema e, per estensione, a piattaforme come OpenShift e Kubernetes.
[ Potrebbe piacerti anche: Condivisione di gruppi supplementari con contenitori Podman ]
Lo spazio dei nomi di montaggio
Lo spazio dei nomi di montaggio non si comporta come ci si potrebbe aspettare dopo la creazione di un nuovo spazio dei nomi utente. Per impostazione predefinita, se dovessi creare un nuovo spazio dei nomi di montaggio con unshare -m , la tua visione del sistema rimarrebbe sostanzialmente invariata e non confinata. Questo perché ogni volta che crei un nuovo spazio dei nomi di montaggio, una copia dei punti di montaggio dallo spazio dei nomi padre viene creato nel nuovo spazio dei nomi di montaggio. Ciò significa che qualsiasi azione intrapresa sui file all'interno di uno spazio dei nomi di montaggio mal configurato sarà impatto sull'host.
Alcuni passaggi di configurazione per gli spazi dei nomi di montaggio
Allora a che serve lo spazio dei nomi di montaggio? Per dimostrarlo, utilizzo un tarball di Alpine Linux.
In sintesi, scaricalo, decomprimilo e spostalo in una nuova directory, concedendo alla directory di primo livello le autorizzazioni per un utente non privilegiato:
[root@localhost ~] export CONTAINER_ROOT_FOLDER=/container_practice
[root@localhost ~] mkdir -p ${CONTAINER_ROOT_FOLDER}/fakeroot
[root@localhost ~] cd ${CONTAINER_ROOT_FOLDER}
[root@localhost ~] wget https://dl-cdn.alpinelinux.org/alpine/v3.13/releases/x86_64/alpine-minirootfs-3.13.1-x86_64.tar.gz
[root@localhost ~] tar xvf alpine-minirootfs-3.13.1-x86_64.tar.gz -C fakeroot
[root@localhost ~] chown container-user. -R ${CONTAINER_ROOT_FOLDER}/fakeroot
Il fakeroot la directory deve essere di proprietà dell'utente utente-container perché una volta creato un nuovo spazio dei nomi utente, il root l'utente nel nuovo spazio dei nomi verrà mappato all'utente-container al di fuori dello spazio dei nomi. Ciò significa che un processo all'interno del nuovo spazio dei nomi penserà di avere le capacità necessarie per modificare i propri file. Tuttavia, le autorizzazioni del file system dell'host impediranno l'utente-contenitore account dalla modifica dei file Alpine dal tarball (che hanno root come proprietario).
Quindi cosa succede se avvii semplicemente un nuovo spazio dei nomi di montaggio?
PS1='\u@new-mnt$ ' unshare -Umr Ora che sei all'interno del nuovo spazio dei nomi, potresti non aspettarti di vedere nessuno dei punti di montaggio originali dall'host. Tuttavia, questo non è il caso:
root@new-mnt$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/cs-root 36G 5.2G 31G 15% /
tmpfs 737M 0 737M 0% /sys/fs/cgroup
devtmpfs 720M 0 720M 0% /dev
tmpfs 737M 0 737M 0% /dev/shm
tmpfs 737M 8.6M 728M 2% /run
tmpfs 148M 0 148M 0% /run/user/0
/dev/vda1 976M 197M 713M 22% /boot
root@new-mnt$ ls /
bin container_practice etc lib media opt root sbin sys usr
boot dev home lib64 mnt proc run srv tmp var
Il motivo è che systemd di default condivide ricorsivamente i punti di montaggio con tutti i nuovi spazi dei nomi. Se hai montato un tmpfs filesystem da qualche parte, ad esempio /mnt all'interno del nuovo spazio dei nomi di montaggio, l'host può vederlo?
root@new-mnt$ mount -t tmpfs tmpfs /mnt
root@new-mnt$ findmnt |grep mnt
└─/mnt tmpfs tmpfs rw,relatime,seclabel,uid=1000,gid=1000 L'host, tuttavia, non vede questo:
[root@localhost ~]# findmnt |grep mnt Quindi, almeno, sai che lo spazio dei nomi di montaggio funziona correttamente. Questo è un buon momento per fare una piccola deviazione per discutere della propagazione dei punti di montaggio. Sto riassumendo brevemente ma se sei interessato a una maggiore comprensione, dai un'occhiata all'articolo LWN di Michael Kerrisk e alla pagina man per lo spazio dei nomi di montaggio. Normalmente non mi affido così tanto alle pagine man poiché spesso scopro che non sono facilmente digeribili. Tuttavia, in questo caso, sono pieni di esempi e in (per lo più) un inglese semplice.
Teoria dei punti di montaggio
I mount si propagano per impostazione predefinita a causa di una funzionalità nel kernel denominata sottostruttura condivisa . Ciò consente a ogni punto di montaggio di avere il proprio tipo di propagazione associato. Questi metadati determinano se i nuovi montaggi in un determinato percorso vengono propagati ad altri punti di montaggio. L'esempio fornito nella pagina man è quello di un disco ottico. Se il tuo disco ottico viene montato automaticamente in /cdrom , il contenuto sarebbe visibile in altri spazi dei nomi solo se è impostato il tipo di propagazione appropriato.
Gruppi di pari e stati delle cavalcature
La documentazione del kernel dice che un "gruppo di pari è definito come un gruppo di vfsmount che si propagano gli eventi tra loro." Gli eventi sono cose come il montaggio di una condivisione di rete o lo smontaggio di un dispositivo ottico. Perché è importante, chiedi? Bene, quando si tratta dello spazio dei nomi di montaggio, i gruppi di peer sono spesso il fattore decisivo in merito al fatto che una cavalcatura sia visibile o meno e con cui si possa interagire. Uno stato di montaggio determina se un membro di un gruppo di pari può ricevere l'evento. Secondo la stessa documentazione del kernel, ci sono cinque stati di montaggio:
- condiviso - Una montatura che appartiene a un gruppo di pari. Eventuali modifiche si propagheranno a tutti i membri del gruppo di pari.
- schiavo - Propagazione unidirezionale. Il punto di montaggio master propagherà gli eventi a uno slave, ma il master non vedrà alcuna azione intrapresa dallo slave.
- condiviso e schiavo - Indica che il punto di montaggio ha un master, ma ha anche un proprio gruppo peer. Il master non riceverà una notifica delle modifiche a un punto di montaggio, ma lo farà tutti i membri del gruppo di peer a valle.
- privato - Non riceve né inoltra alcun evento di propagazione.
- non vincolabile - Non riceve o inoltra alcun evento di propagazione e non può essere vincolato montato.
È importante notare che lo stato del punto di montaggio è per punto di montaggio . Questo significa che se hai / e /boot , ad esempio, dovresti applicare separatamente lo stato desiderato a ciascun punto di montaggio.
Nel caso ti stia chiedendo dei container, la maggior parte dei motori di container utilizza stati di montaggio privati durante il montaggio di un volume all'interno di un container. Non preoccuparti troppo di questo per ora. Voglio solo fornire un contesto. Se vuoi provare alcuni scenari di montaggio specifici, guarda le pagine man poiché gli esempi sono abbastanza buoni.
Creazione del nostro spazio dei nomi di montaggio
Se utilizzi un linguaggio di programmazione come Go o C, puoi utilizzare le chiamate del kernel di sistema non elaborate per creare l'ambiente appropriato per i tuoi nuovi spazi dei nomi. Tuttavia, poiché l'intento alla base di questo è aiutarti a capire come interagire con un contenitore già esistente, dovrai eseguire alcuni trucchi bash per portare il tuo nuovo spazio dei nomi di montaggio nello stato desiderato.
Innanzitutto, crea il nuovo spazio dei nomi di montaggio come utente normale:
unshare -Urm
Una volta che sei all'interno dello spazio dei nomi, guarda findmnt del dispositivo mapper, che contiene il file system di root (per brevità, ho rimosso la maggior parte delle opzioni di montaggio dall'output):
findmnt |grep mapper
/ /dev/mapper/cs-root xfs rw,relatime,[...] C'è solo un punto di montaggio che ha il mapper del dispositivo root. Questo è importante perché una delle cose che devi fare è associare il dispositivo mapper nella directory Alpine:
export CONTAINER_ROOT_FOLDER=/container_practice
mount --bind ${CONTAINER_ROOT_FOLDER}/fakeroot ${CONTAINER_ROOT_FOLDER}/fakeroot
cd ${CONTAINER_ROOT_FOLDER}/fakeroot
Questo perché stai usando un'utilità chiamata pivot_root per eseguire un chroot -come azione. pivot_root accetta due argomenti:new_root e old_root (a volte indicato come put_old ). pivot_root sposta il file system radice del processo corrente nella directory put_old e crea new_root il nuovo file system radice.
IMPORTANTE :Una nota su chroot . chroot è spesso considerato come dotato di ulteriori vantaggi in termini di sicurezza. In una certa misura, questo è vero, poiché ci vuole una quantità più significativa di esperienza per liberarsene. Un chroot accuratamente costruito può essere molto sicuro. Tuttavia, chroot non modifica o limita le capacità di Linux di cui ho parlato nel precedente articolo sullo spazio dei nomi. Né limita le chiamate di sistema al kernel. Ciò significa che un aggressore sufficientemente abile potrebbe potenzialmente sfuggire a un chroot che non è stato ben pensato. Gli spazi dei nomi di montaggio e utente aiutano a risolvere questo problema.
Se usi pivot_root senza il bind mount, il comando risponde con:
pivot_root: failed to change root from `.' to `old_root/': Invalid argument
Per passare al filesystem root di Alpine, prima crea una directory per old_root e quindi ruotare nel filesystem di root (alpino) previsto. Poiché il filesystem radice di Alpine Linux non ha collegamenti simbolici per /bin e /sbin , dovrai aggiungerli al tuo percorso e infine smontare il old_root :
mkdir old_root
pivot_root . old_root
PATH=/bin:/sbin:$PATH
umount -l /old_root
Ora hai un bell'ambiente in cui l'utente e montare i namespace lavorano insieme per fornire un livello di isolamento dall'host. Non hai più accesso ai file binari sull'host. Prova a emettere findmnt comando che hai usato in precedenza:
root@new-mnt$ findmnt
-bash: findmnt: command not found Puoi anche guardare il filesystem di root o provare a vedere cosa è montato:
root@new-mnt$ ls -l /
total 12
drwxr-xr-x 2 root root 4096 Jan 28 21:51 bin
drwxr-xr-x 2 root root 18 Feb 17 22:53 dev
drwxr-xr-x 15 root root 4096 Jan 28 21:51 etc
drwxr-xr-x 2 root root 6 Jan 28 21:51 home
drwxr-xr-x 7 root root 247 Jan 28 21:51 lib
drwxr-xr-x 5 root root 44 Jan 28 21:51 media
drwxr-xr-x 2 root root 6 Jan 28 21:51 mnt
drwxrwxr-x 2 root root 6 Feb 17 23:09 old_root
drwxr-xr-x 2 root root 6 Jan 28 21:51 opt
drwxr-xr-x 2 root root 6 Jan 28 21:51 proc
drwxr-xr-x 2 root root 6 Feb 17 22:53 put_old
drwx------ 2 root root 27 Feb 17 22:53 root
drwxr-xr-x 2 root root 6 Jan 28 21:51 run
drwxr-xr-x 2 root root 4096 Jan 28 21:51 sbin
drwxr-xr-x 2 root root 6 Jan 28 21:51 srv
drwxr-xr-x 2 root root 6 Jan 28 21:51 sys
drwxrwxrwt 2 root root 6 Feb 19 16:38 tmp
drwxr-xr-x 7 root root 66 Jan 28 21:51 usr
drwxr-xr-x 12 root root 137 Jan 28 21:51 var
root@new-mnt$ mount
mount: no /proc/mounts
È interessante notare che non esiste proc filesystem montato di default. Prova a montarlo:
root@new-mnt$ mount -t proc proc /proc
mount: permission denied (are you root?)
root@new-mnt$ whoami
root
Perché proc è un tipo speciale di montaggio relativo allo spazio dei nomi PID, non puoi montarlo anche se ti trovi nel tuo spazio dei nomi di montaggio. Questo risale all'ereditarietà delle capacità di cui ho discusso in precedenza. Riprenderò questa discussione nel prossimo articolo quando tratterò lo spazio dei nomi PID. Tuttavia, come promemoria sull'ereditarietà, dai un'occhiata al diagramma seguente:
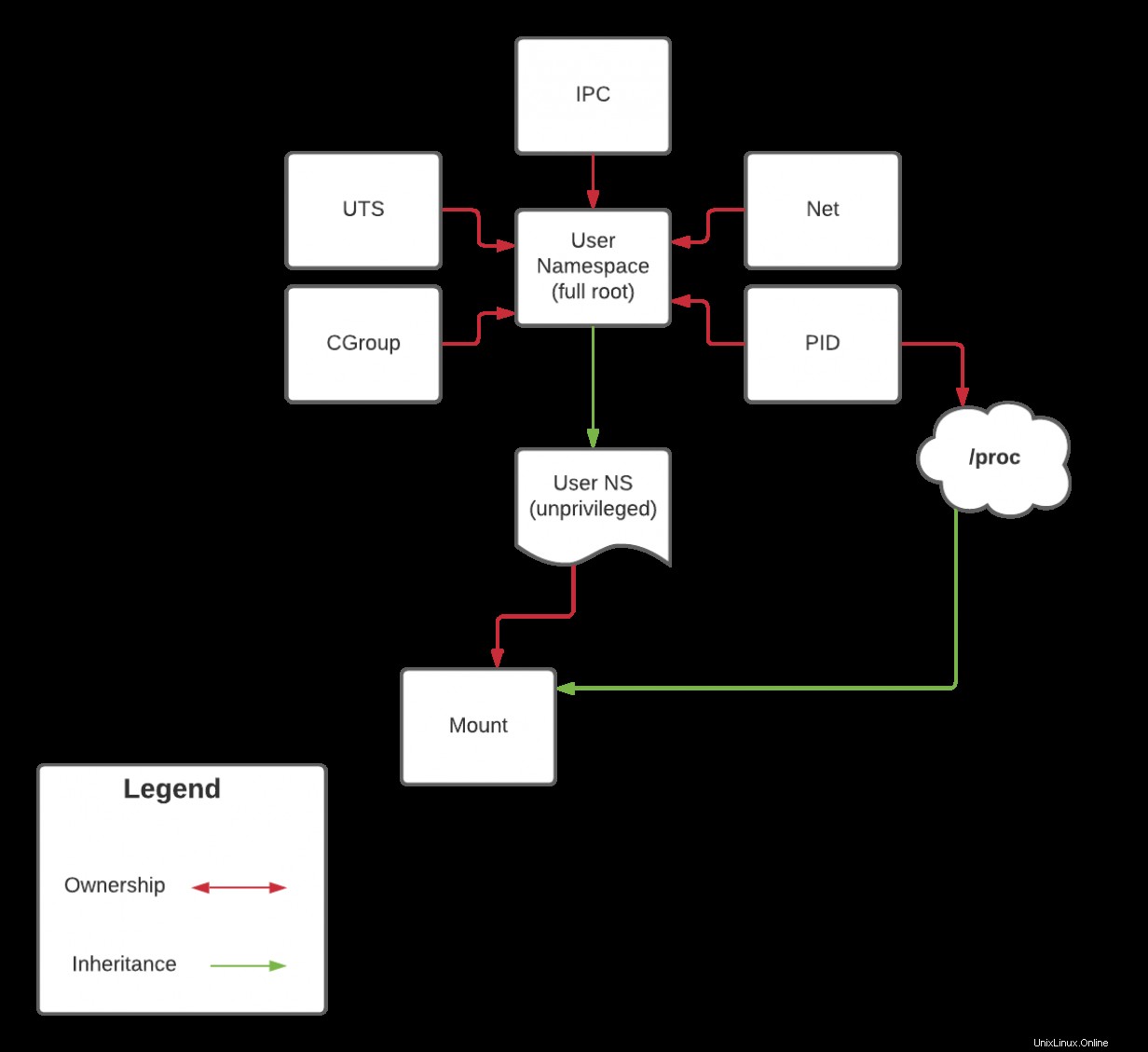
Nel prossimo articolo, rifarò questo diagramma, ma se hai seguito fin dall'inizio, dovresti essere in grado di fare alcune inferenze prima di allora.
[ Manuale del proprietario dell'API:7 best practices per programmi API efficaci ]
Conclusione
In questo articolo, ho trattato alcune teorie più approfondite sullo spazio dei nomi di montaggio. Ho discusso dei gruppi di pari e di come si relazionano con gli stati di montaggio applicati a ciascun punto di montaggio su un sistema. Per la parte pratica, hai scaricato un file system minimo di Alpine Linux e poi hai spiegato come utilizzare l'utente e montare gli spazi dei nomi per creare un ambiente che assomiglia molto a chroot tranne che potenzialmente più sicuro.
Per ora, prova a montare i file system all'interno e all'esterno del tuo nuovo spazio dei nomi. Prova a creare nuovi punti di montaggio che utilizzano il condiviso , privato e slave stati di montaggio. Nel prossimo articolo, utilizzerò lo spazio dei nomi PID per continuare a costruire il contenitore primitivo per ottenere l'accesso al proc file system e isolamento del processo.