Non molto tempo fa, ho scritto un articolo che copre una panoramica degli spazi dei nomi più comuni. Le informazioni sono ottime da avere e, in una certa misura, sono sicuro che puoi estrapolare come potresti mettere a frutto queste conoscenze. Normalmente non è nel mio stile lasciare le cose così aperte. Quindi, per i prossimi due articoli, dedico un po' di tempo a dimostrare alcuni degli spazi dei nomi più importanti attraverso l'obiettivo della creazione di un contenitore Linux primitivo. In un certo senso, sto scrivendo le mie esperienze con le tecniche che utilizzo durante la risoluzione dei problemi di un container Linux su un sito client. Con questo in mente, inizio con le fondamenta di qualsiasi container, soprattutto quando la sicurezza è un problema.
Un po' sulle funzionalità di Linux
La sicurezza su un sistema Linux può assumere molte forme. Ai fini di questo articolo, mi occupo principalmente della sicurezza quando si tratta di autorizzazioni per i file. Come promemoria, tutto su un sistema Linux è una sorta di file, e quindi i permessi dei file sono la prima linea di difesa contro un'applicazione che potrebbe comportarsi in modo anomalo.
Il modo principale in cui Linux gestisce i permessi dei file è attraverso l'implementazione di utenti . Ci sono utenti normali per cui Linux applica il controllo dei privilegi e c'è il superutente che aggira la maggior parte (se non tutti) i controlli. In breve, il modello Linux originale era tutto o niente.
Per aggirare questo problema, alcuni programmi binari hanno il set uid po 'impostato su di loro. Questa impostazione consente al programma di essere eseguito come l'utente proprietario del file binario. Il passwd l'utilità ne è un buon esempio. Qualsiasi utente può eseguire questa utilità sul sistema. Deve avere privilegi elevati sul sistema per interagire con shadow file, che memorizza gli hash per le password degli utenti su un sistema Linux. Mentre il passwd binary ha controlli integrati per garantire che un utente normale non possa modificare la password di un altro utente, molte applicazioni non hanno lo stesso livello di controllo, specialmente se l'amministratore di sistema ha attivato set uid bit.
funzionalità di Linux sono stati creati per fornire un'applicazione più granulare del modello di sicurezza. Invece di eseguire il file binario come root, puoi applicare solo le capacità specifiche richieste da un'applicazione per essere efficace. A partire dal kernel Linux 5.1, ci sono 38 funzionalità. Le pagine man per le capacità sono in realtà scritte abbastanza bene e descrivono ciascuna capacità.
Un set di funzionalità è il modo in cui le capacità possono essere assegnate ai thread. In breve, ci sono cinque set di capacità totali, ma per questa discussione solo due di essi sono rilevanti:Effettivo e Consentito.
Efficace :il kernel verifica ogni azione privilegiata e decide se consentire o meno una chiamata di sistema. Se un thread o un file ha il efficace capacità, sei autorizzato a eseguire l'azione relativa alla capacità effettiva.
Consentito :le funzionalità consentite non sono ancora attive. Tuttavia, se un processo è autorizzato capacità, significa che il processo stesso può scegliere di trasformare il proprio privilegio in un privilegio effettivo.
Per vedere quali funzionalità può avere un determinato processo, puoi eseguire getpcaps ${PID} comando. L'output di questo comando avrà un aspetto diverso a seconda della distribuzione di Linux. Su RHEL/CentOS otterrai un intero elenco di funzionalità:
[root@CentOS8 ~]# getpcaps $$
Capabilities for `1304': = cap_chown,cap_dac_override,cap_dac_read_search,cap_fowner,cap_fsetid,cap_kill,cap_setgid,cap_setuid,cap_setpcap,cap_linux_immutable,cap_net_bind_service,cap_net_broadcast,cap_net_admin,cap_net_raw,cap_ipc_lock,cap_ipc_owner,cap_sys_module,cap_sys_rawio,cap_sys_chroot,cap_sys_ptrace,cap_sys_pacct,cap_sys_admin,cap_sys_boot,cap_sys_nice,cap_sys_resource,cap_sys_time,cap_sys_tty_config,cap_mknod,cap_lease,cap_audit_write,cap_audit_control,cap_setfcap,cap_mac_override,cap_mac_admin,cap_syslog,cap_wake_alarm,cap_block_suspend,cap_audit_read,38,39+ep
Se esegui il comando man 7 capabilities , troverai un elenco di tutte queste funzionalità insieme a una descrizione per ciascuna. In alcune distribuzioni, come Ubuntu o Arch, eseguire lo stesso comando si traduce semplicemente in questo:
[root@Arch ~]# getpcaps $$
414429: =ep È presente uno spazio bianco prima di = cartello. Questo spazio bianco è intercambiabile con la parola chiave tutti . Come avrai intuito, ciò significa che tutte le funzionalità disponibili sul sistema sono concesse sia in E efficace e P insiemi di capacità emessi.
Perché questo è importante? Prima di tutto, i set di capacità sono legati a uno spazio dei nomi utente (di cui parlerò di seguito). Per ora, ciò significa che ogni spazio dei nomi avrà il proprio insieme di funzionalità che si applicano solo al suo proprio spazio dei nomi. Supponiamo di avere uno spazio dei nomi chiamato vincolato . È possibile che vincolato sembra come se avesse tutte le capacità appropriate come si vede con getpcaps comando. Tuttavia, se vincolato è stato creato da un processo e uno spazio dei nomi che non disponeva di un set completo di funzionalità (come un utente normale), vincolato non possono essere concesse più autorizzazioni su un sistema rispetto al processo di creazione.
Per riassumere, quindi, le capacità, pur non essendo una tecnologia dello spazio dei nomi, lavorano di pari passo nel determinare cosa e come possono essere eseguiti i processi all'interno di uno spazio dei nomi.
[ Potresti anche divertirti: Eseguire Podman senza root come utente non root ]
Lo spazio dei nomi utente
Prima di immergerti nella creazione di uno spazio dei nomi utente, ecco un breve riepilogo dello scopo di questo spazio dei nomi. Come ho discusso in un articolo precedente, i nomi utente e, in definitiva, il numero di identificazione dell'utente (UID), sono uno dei livelli di sicurezza che un sistema utilizzerà per garantire che le persone e i processi non accedano a cose a cui non sono autorizzati.
Teoria dietro lo spazio dei nomi utente
Lo spazio dei nomi utente è un modo per un contenitore (un insieme di processi isolati) di avere un diverso insieme di autorizzazioni rispetto al sistema stesso. Ogni contenitore eredita le sue autorizzazioni dall'utente che ha creato il nuovo spazio dei nomi utente. Ad esempio, nella maggior parte dei sistemi Linux, gli ID utente regolari iniziano da 1000 o da oltre. Per il resto di questa serie, utilizzo un utente denominato container-user , che ha i seguenti ID (i contesti SELinux sono omessi per queste demo):
uid=1000(container-user) gid=1000(container-user) groups=1000(container-user) È importante notare che, a meno che non sia limitato intenzionalmente dall'amministratore di sistema, qualsiasi utente può, in teoria, creare un nuovo spazio dei nomi utente. Questo, tuttavia, non fornisce alcun offuscamento da parte degli amministratori sul sistema stesso. Gli spazi dei nomi utente sono una gerarchia. Considera il diagramma seguente:
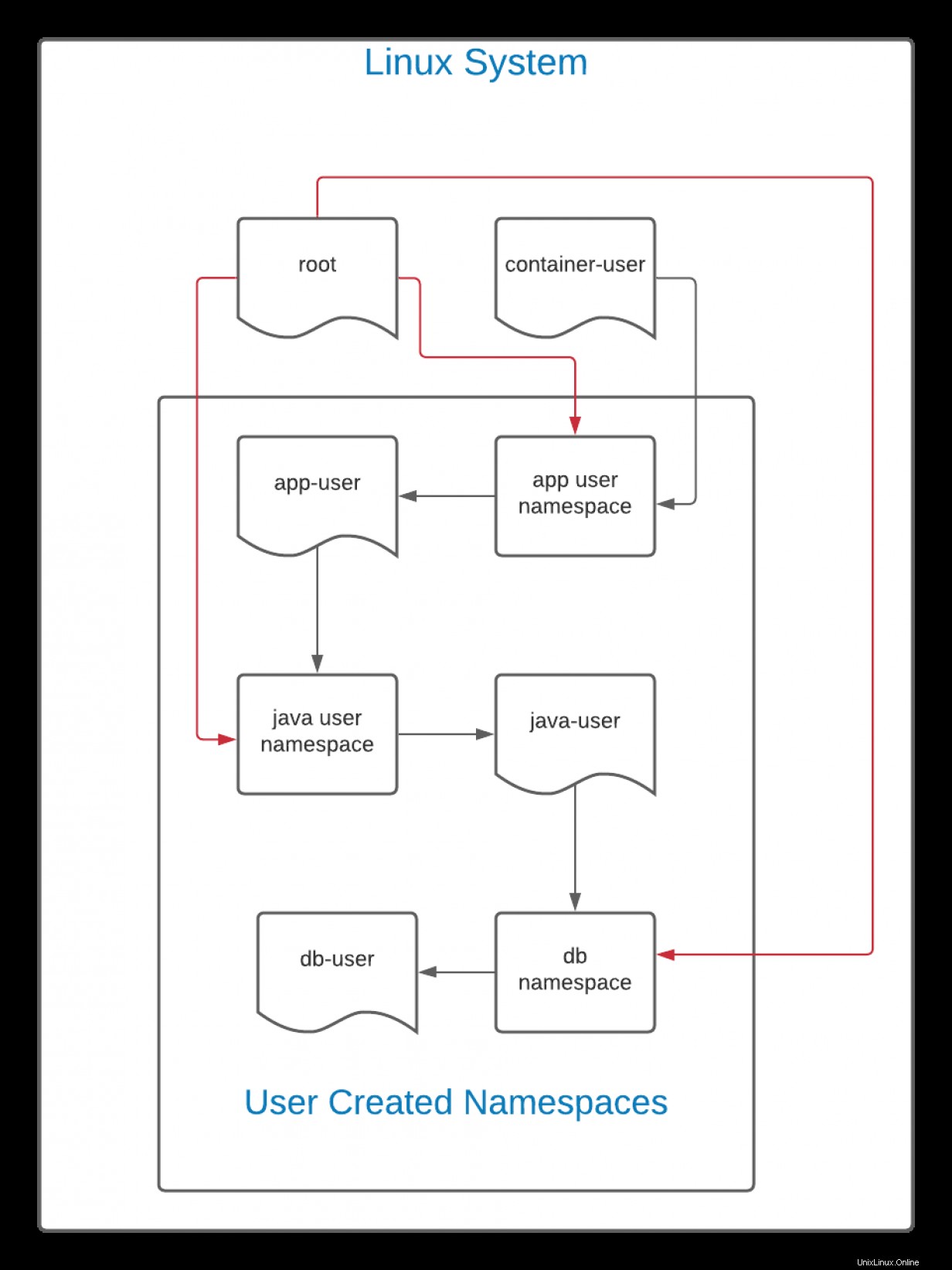
In questo diagramma, le linee nere indicano il flusso della creazione. L'utente utente-contenitore crea uno spazio dei nomi per un utente chiamato app-user . In teoria, questo sarebbe un front-end web o un'altra applicazione. Successivamente, utente app crea uno spazio dei nomi utente per utente java . In questo spazio dei nomi, utente java crea uno spazio dei nomi per db-user .
Poiché si tratta di una gerarchia, utente-contenitore può vedere e accedere a tutti i file creati da uno qualsiasi degli spazi dei nomi generati dal suo UID. Allo stesso modo, perché il root l'utente sul sistema Linux può vedere e interagire con tutti file su un sistema, inclusi quelli creati da utente-container , la radice l'utente (rappresentato dalla linea rossa) può avere l'autorità totale su tutti gli spazi dei nomi.
Tuttavia, non è vero il contrario. L'utente db l'utente, in questo caso, non può vedere o interagire con nulla al di sopra di esso. Se la mappatura dell'ID viene mantenuta invariata (la norma predefinita), app-user , utente java e utente db tutti hanno lo stesso UID. Tuttavia, sebbene condividano lo stesso UID, db-user non può interagire con utente java , che non può interagire con utente app , e così via.
Qualsiasi autorizzazione concessa in uno spazio dei nomi utente si applica solo nel proprio spazio dei nomi e possibilmente negli spazi dei nomi sotto di esso.
Esperienza pratica con gli spazi dei nomi utente
Per creare un nuovo spazio dei nomi utente, usa semplicemente unshare -U comando:
[container-user@localhost ~]$ PS1='\u@app-user$ ' unshare -U
nobody@app-user$ Il comando precedente include una PS1 variabile che cambia semplicemente la shell in modo che sia più facile determinare in quale spazio dei nomi è attiva la shell. È interessante notare che l'utente è nessuno :
nobody@app-user$ whoami
nobody
nobody@app-user$ id
uid=65534(nobody) gid=65534(nobody) groups=65534(nobody) Questo perché, per impostazione predefinita, non è in corso alcuna mappatura dell'ID utente. Quando non viene definita alcuna mappatura, lo spazio dei nomi utilizza semplicemente le regole del tuo sistema per determinare come gestire un utente non definito.
Tuttavia, se crei lo spazio dei nomi in questo modo:
PS1='\u@app-user$ ' unshare -Ur La mappatura verrà creata automaticamente per te:
root@app-user$ cat /proc/$$/uid_map
0 1000 1 Questo file rappresenta quanto segue:
ID-inside-ns ID-outside-ns range La gamma value rappresenta il numero di utenti da mappare. Ad esempio, se questo fosse 0 1000 4 , la mappatura sarebbe così
0 1000
1 1001
2 1002
3 1003 E così via. La maggior parte delle volte, ti interessa davvero solo la radice mappatura utente, ma l'opzione è disponibile se lo si desidera. Cosa succede quando crei l'utente java spazio dei nomi?
root@app-user$ PS1='\u@java-user$ ' unshare -Ur
root@java-user$ Come previsto, il prompt della shell cambia e tu sei l'utente root, ma che aspetto ha la mappatura UID?
root@java-user$ cat /proc/$$/uid_map
0 0 1 Lo vedi ora, hai uno 0 a 0 Mappatura. Questo perché l'utente che crea un'istanza del nuovo spazio dei nomi viene utilizzato per il processo di mappatura ID. Dato che eri root nello spazio dei nomi precedente, il nuovo spazio dei nomi ha una mappatura di root per rootare . Tuttavia, poiché root nell'utente app lo spazio dei nomi non ha root sul sistema, nemmeno il nuovo spazio dei nomi root utente.
Oltre a controllare semplicemente la uid_map , puoi anche verificare dall'esterno dello spazio dei nomi se due processi si trovano nello stesso spazio dei nomi. Ovviamente, devi prima trovare il PID del processo, ma con quello in mano puoi eseguire il seguente comando:
readlink /proc/$PID/ns/user Per semplificare, ho eseguito quanto segue:
[container-user@localhost ~]$ PS1='\u@app-user$ ' unshare -Ur
root@app-user$ sleep 100000
In un altro terminale, ho recuperato il PID e ho utilizzato il readlink comando su quel PID e sulla shell corrente:
[root@localhost ~]# readlink /proc/1307/ns/user
user:[4026532275]
[root@localhost ~]# readlink /proc/$$/ns/user
user:[4026531837] Come puoi vedere, il link dell'utente è diverso. Se operassero nello stesso spazio dei nomi, sarebbe simile a questo:
[root@localhost ~]# readlink /proc/1424/ns/user
user:[4026532275]
[root@localhost ~]# readlink /proc/1307/ns/user
user:[4026532275] Il più grande vantaggio per lo spazio dei nomi utente è la possibilità di eseguire container senza privilegi di root. Inoltre, a seconda di come imposti la mappatura UID, puoi evitare completamente di avere un superutente all'interno di un determinato spazio dei nomi utente. Ciò significa che non è possibile eseguire alcun processo privilegiato all'interno di questo tipo di spazio dei nomi.
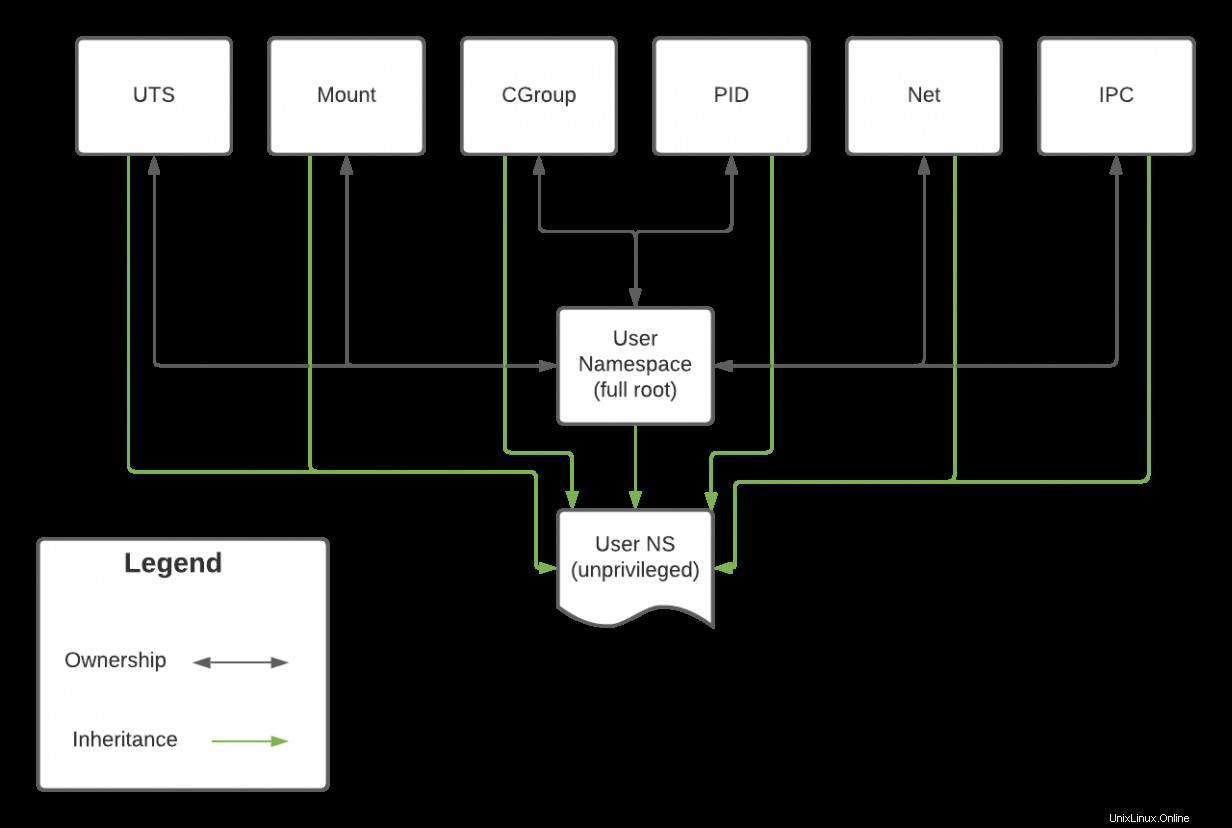
Nota :l'utente namespace governa ogni namespace. Ciò significa che le capacità di uno spazio dei nomi sono direttamente correlate alle capacità del suo utente padre spazio dei nomi.
La root originale e completa lo spazio dei nomi utente possiede tutti gli spazi dei nomi su un sistema nel diagramma seguente. Questa relazione ha il potenziale per essere bidirezionale. Se un processo è in esecuzione nella rete namespace viene eseguito come root , può influire su tutti gli altri processi di proprietà della root spazio dei nomi utente. Tuttavia, mentre la creazione di uno spazio dei nomi utente senza privilegi consente a quel nuovo spazio dei nomi utente di accedere alle risorse in altri spazi dei nomi, potrebbe non alterarli poiché non ne è il proprietario. Pertanto, mentre un processo nello spazio dei nomi non privilegiato può ping un IP (che si basa sulla rete namespace), potrebbe non modificare la configurazione di rete dell'host.
Molte cose al di fuori di ciò che pensi come container Linux utilizzano gli spazi dei nomi. Il formato di pacchetto Linux Flatpak utilizza gli spazi dei nomi degli utenti e alcune altre tecnologie per fornire una sandbox dell'applicazione. Flatpak raggruppa tutte le librerie di un'applicazione nello stesso file di distribuzione del pacchetto. Ciò consente a una macchina Linux di ricevere le applicazioni più aggiornate senza doversi preoccupare di avere la versione corretta di glibc installato, per esempio. La possibilità di averli nel proprio spazio dei nomi utente significa che (in teoria) un processo che si comporta in modo anomalo all'interno del flatpak non può modificare (o forse anche accedere) a nessun file o processo al di fuori dello spazio dei nomi.
[ Iniziare con i container? Dai un'occhiata a questo corso gratuito. Distribuzione di applicazioni containerizzate:una panoramica tecnica. ]
Conclusione
L'uso degli spazi dei nomi utente da solo non risolve il problema che Flatpak e altri stanno cercando di gestire. Sebbene gli spazi dei nomi utente siano parte integrante della storia della sicurezza e delle capacità di altri spazi dei nomi, da soli non forniscono molto. C'è molto da considerare quando si creano nuovi spazi dei nomi isolati. Nel prossimo articolo, esaminerò l'utilizzo della montaggio namespace insieme allo spazio dei nomi utente per creare un chroot -like ambiente con spazi dei nomi.
Se stai cercando alcune sfide per rafforzare la tua comprensione, prova a mappare una serie di utenti nel nuovo spazio dei nomi. Cosa succede se si mappa l'intero intervallo in uno spazio dei nomi? È possibile diventare l'utente apache in uno spazio dei nomi senza privilegi? Quali sono le implicazioni sulla sicurezza per la scrittura di una uid_map errata file? (Suggerimento :Avrai bisogno di due gusci aperti; uno per creare e vivere all'interno del nuovo spazio dei nomi e l'altro per scrivere la uid_map e gid_map File. Se stai lottando con questo, scrivimi un messaggio su Twitter @linuxovens).