Immagina di avere un file (o un gruppo di file) e di voler cercare una stringa specifica o un'impostazione di configurazione all'interno di questi file. Aprire ogni file individualmente e cercare di trovare la stringa specifica sarebbe noioso e probabilmente non è l'approccio giusto. Allora cosa possiamo usare?
Ci sono molti strumenti che possiamo usare nei sistemi basati su *nix per trovare e manipolare il testo. In questo articolo tratteremo il grep comando per cercare i pattern, trovati nei file o provenienti da uno stream (un file o input proveniente da una pipe, o | ). In un prossimo articolo, vedremo anche come utilizzare sed (Stream Editor) per manipolare uno stream.
Il modo migliore per comprendere il funzionamento di un programma o di un'utilità è consultare la relativa pagina man. Molti (se non tutti) strumenti Unix forniscono pagine di manuale durante l'installazione. Sui sistemi basati su Red Hat Enterprise Linux, possiamo eseguire quanto segue per elencare grep i file di documentazione di:
$ rpm -qd grep
/usr/share/doc/grep/AUTHORS
/usr/share/doc/grep/NEWS
/usr/share/doc/grep/README
/usr/share/doc/grep/THANKS
/usr/share/doc/grep/TODO
/usr/share/info/grep.info.gz
/usr/share/man/man1/egrep.1.gz
/usr/share/man/man1/fgrep.1.gz
Con le pagine man a nostra disposizione, ora possiamo usare grep ed esplora le sue opzioni.
grep basi
Durante questa parte dell'articolo, utilizziamo le words file, che puoi trovare al seguente percorso:
$ ls -l /usr/share/dict/words
lrwxrwxrwx. 1 root root 11 Feb 3 2019 /usr/share/dict/words -> linux.words
Questo file contiene 479.826 parole ed è fornito dalle words pacchetto. Nel mio sistema Fedora, quel pacchetto è words-3.0-33.fc30.noarch . Quando elenchiamo il contenuto delle words file, vediamo il seguente output:
$ cat /usr/share/dict/words
1080
10-point
10th
11-point
[……]
[……]
zyzzyva
zyzzyvas
ZZ
Zz
zZt
ZZZ
Ok, quindi abbiamo detto le words il file conteneva 479.826 righe, ma come facciamo a saperlo? Ricorda, abbiamo parlato delle pagine man in precedenza. Vediamo se grep offre un'opzione per contare le righe in un determinato file.
Ironia della sorte, useremo grep per cercare l'opzione come segue:

Quindi, abbiamo ovviamente bisogno di -c o l'opzione lunga --count , per contare il numero di righe in un determinato file. Conteggio delle righe in /usr/share/dict/words rendimenti:
$ grep -c '.' /usr/share/dict/words
479826
Il '.' significa che conteremo tutte le righe contenenti almeno un carattere, spazio, spazio vuoto, tabulazione, ecc.
grep di base espressioni regolari
Il grep il comando diventa più potente quando utilizziamo espressioni regolari (regex). Quindi, mentre ci concentriamo su grep comando stesso, tratteremo anche la sintassi di base delle espressioni regolari.
Supponiamo di essere interessati solo alle parole che iniziano con Z . Questa è la situazione in cui le espressioni regolari tornano utili. Usiamo il carato (^ ) per cercare pattern che iniziano con un carattere specifico, che denota l'inizio di una stringa:
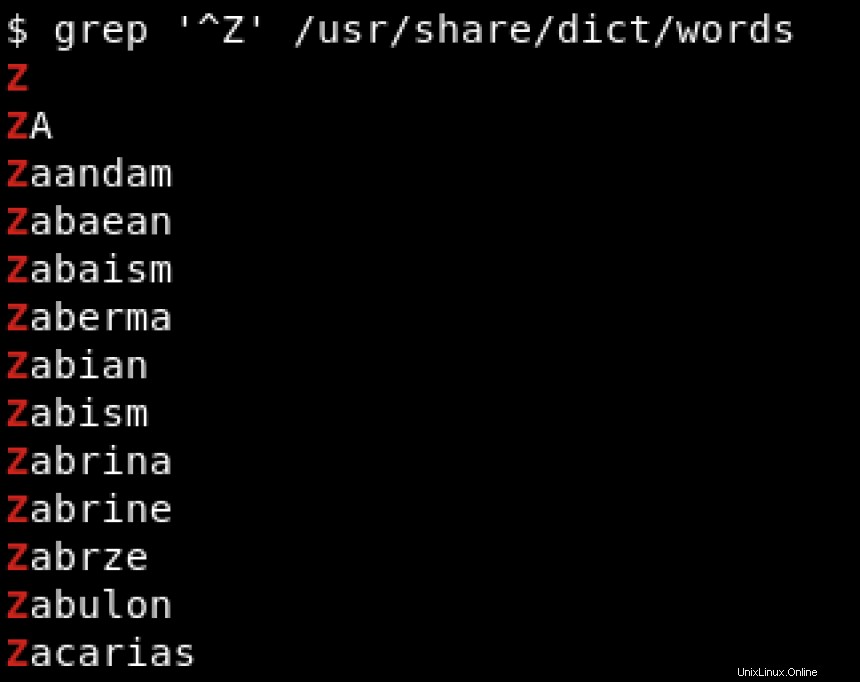
Per cercare pattern che terminano con un carattere specifico, utilizziamo il simbolo del dollaro ($ ) per indicare la fine della stringa. Vedi l'esempio qui sotto dove cerchiamo le stringhe che terminano con hat :
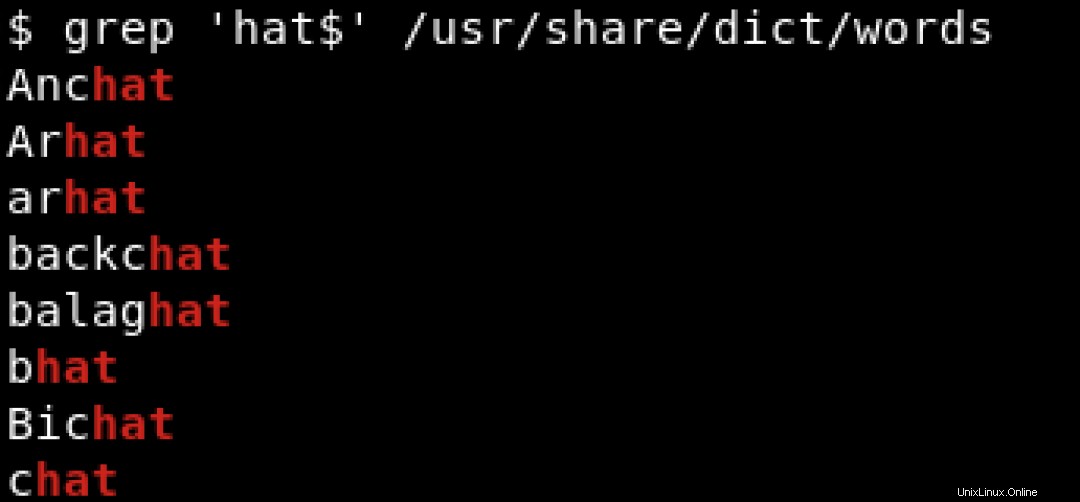
Per stampare tutte le righe che contengono hat indipendentemente dalla sua posizione, sia all'inizio che alla fine della riga, useremmo qualcosa del tipo:
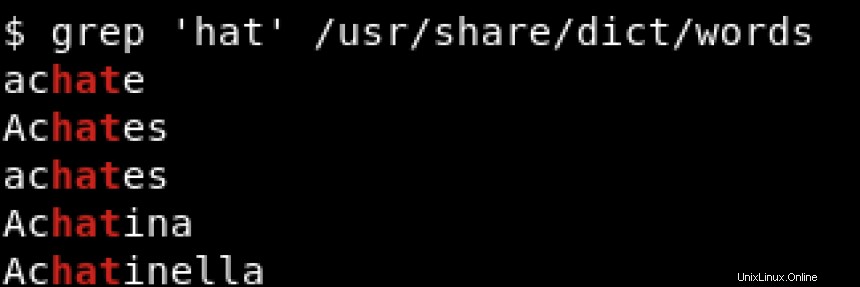
Il ^ e $ sono chiamati metacaratteri e devono essere sottoposti a escape con una barra rovesciata (\ ) quando vogliamo abbinare questi caratteri alla lettera. Se vuoi saperne di più sui metacaratteri, visita https://www.regular-expressions.info/characters.html.
Esempio:rimuovi commenti
Ora che abbiamo graffiato la superficie di grep , lavoriamo su alcuni scenari del mondo reale. Molti file di configurazione in *nix contengono commenti che descrivono diverse impostazioni all'interno del file di configurazione. Il /etc/fstab , ad esempio, il file ha:
$ cat /etc/fstab
#
# /etc/fstab
# Created by anaconda on Thu Oct 27 05:06:06 2016
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
/dev/mapper/VGCRYPTO-ROOT / ext4 defaults,x-systemd.device-timeout=0 1 1
UUID=e9de0f73-ddddd-4d45-a9ba-1ffffa /boot ext4 defaults 1 2
LABEL=SSD_SWAP swap swap defaults 0 0
#/dev/mapper/VGCRYPTO-SWAP swap swap defaults,x-systemd.device-timeout=0 0 0
I commenti sono contrassegnati dall'hash (# ), e vogliamo ignorarli quando vengono stampati. Un'opzione è il cat comando:
$ cat /etc/fstab | grep -v '^#'
Tuttavia, non hai bisogno di cat qui (evitare l'uso inutile del gatto). Il grep command è perfettamente in grado di leggere file, quindi puoi usare qualcosa del genere per ignorare le righe che contengono commenti:
$ grep -v '^#' /etc/fstab
Se invece vuoi inviare l'output (senza commenti) a un altro file, dovresti usare:
$ grep -v '^#' /etc/fstab > ~/fstab_without_comment
Mentre grep può formattare l'output sullo schermo, questo comando non è in grado di modificare un file sul posto. Per fare ciò, avremmo bisogno di un editor di file come ed . Nel prossimo articolo useremo sed per ottenere la stessa cosa che abbiamo fatto qui con grep .
Esempio:rimuovere commenti e righe vuote
Mentre siamo ancora su grep , esaminiamo il /etc/sudoers file. Questo file contiene molti commenti, ma siamo interessati solo alle righe che non hanno commenti e vogliamo anche eliminare le righe vuote.
Quindi, per prima cosa, rimuoviamo le righe che contengono i commenti. Viene prodotto il seguente output:
# grep -v '^#' /etc/sudoers
Defaults !visiblepw
Defaults env_reset
Defaults env_keep = "COLORS DISPLAY HOSTNAME HISTSIZE KDEDIR LS_COLORS"
Defaults env_keep += "MAIL PS1 PS2 QTDIR USERNAME LANG LC_ADDRESS LC_CTYPE"
Defaults env_keep += "LC_COLLATE LC_IDENTIFICATION LC_MEASUREMENT LC_MESSAGES"
Defaults env_keep += "LC_MONETARY LC_NAME LC_NUMERIC LC_PAPER LC_TELEPHONE"
Defaults env_keep += "LC_TIME LC_ALL LANGUAGE LINGUAS _XKB_CHARSET XAUTHORITY"
Defaults secure_path = /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
root ALL=(ALL) ALL
%wheel ALL=(ALL) ALL
Ora, vogliamo sbarazzarci delle righe vuote (vuote). Bene, è facile, esegui un altro grep comando:
# grep -v '^#' /etc/sudoers | grep -v '^$'
Defaults !visiblepw
Defaults env_reset
Defaults env_keep = "COLORS DISPLAY HOSTNAME HISTSIZE KDEDIR LS_COLORS"
Defaults env_keep += "MAIL PS1 PS2 QTDIR USERNAME LANG LC_ADDRESS LC_CTYPE"
Defaults env_keep += "LC_COLLATE LC_IDENTIFICATION LC_MEASUREMENT LC_MESSAGES"
Defaults env_keep += "LC_MONETARY LC_NAME LC_NUMERIC LC_PAPER LC_TELEPHONE"
Defaults env_keep += "LC_TIME LC_ALL LANGUAGE LINGUAS _XKB_CHARSET XAUTHORITY"
Defaults secure_path = /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
root ALL=(ALL) ALL
%wheel ALL=(ALL) ALL
valentin.local ALL=NOPASSWD: /usr/bin/updatedb
Potremmo fare di meglio? Possiamo eseguire il nostro grep comando per essere più rispettoso delle risorse e non fork grep due volte? Possiamo certamente:
# grep -Ev '^#|^$' /etc/sudoers
Defaults !visiblepw
Defaults env_reset
Defaults env_keep = "COLORS DISPLAY HOSTNAME HISTSIZE KDEDIR LS_COLORS"
Defaults env_keep += "MAIL PS1 PS2 QTDIR USERNAME LANG LC_ADDRESS LC_CTYPE"
Defaults env_keep += "LC_COLLATE LC_IDENTIFICATION LC_MEASUREMENT LC_MESSAGES"
Defaults env_keep += "LC_MONETARY LC_NAME LC_NUMERIC LC_PAPER LC_TELEPHONE"
Defaults env_keep += "LC_TIME LC_ALL LANGUAGE LINGUAS _XKB_CHARSET XAUTHORITY"
Defaults secure_path = /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
root ALL=(ALL) ALL
%wheel ALL=(ALL) ALL
valentin.local ALL=NOPASSWD: /usr/bin/updatedb
Qui abbiamo introdotto un altro grep opzione, -E (o --extended-regexp ) <PATTERN> è un'espressione regolare estesa.
Esempio:stampa solo /etc/passwd utenti
È ovvio che grep è potente se usato con le espressioni regolari. Questo articolo copre solo una piccola parte di ciò che grep ne è davvero capace. Per dimostrare le capacità di grep e l'uso di espressioni regolari, analizzeremo il /etc/passwd archiviare e stampare solo i nomi utente.
Il formato del /etc/passwd il file è il seguente:
$ head /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
I campi sopra indicati hanno il seguente significato:
<name>:<password>:<UID>:<GID>:<GECOS>:<directory>:<shell>
Vedi man 5 passwd per ulteriori informazioni su /etc/passwd file. Per stampare solo i nomi utente, potremmo usare qualcosa di simile al seguente:
$ grep -Eo '^[a-zA-Z_-]+' /etc/passwd
root
bin
daemon
adm
lp
sync
shutdown
halt
mail
operator
In grep sopra comando, abbiamo introdotto un'altra opzione:-o (o --only-matching ) per mostrare solo la parte di riga corrispondente a <PATTERN> . Quindi, abbiamo combinato -Eo per ottenere il risultato desiderato.
Ora spezzeremo il comando sopra in modo da poter capire meglio cosa sta realmente accadendo. Da sinistra a destra:
^partite all'inizio della riga.[a-zA-Z_-]è chiamata classe di caratteri e corrisponde a un elenco incluso di corrispondenza di caratteri singoli.+è un quantificatore che corrisponde tra uno e un numero illimitato di volte.
L'espressione regolare sopra si ripeterà fino a raggiungere un carattere che non corrisponde. La prima riga del file è:
root:x:0:0:root:/root:/bin/bash
Viene elaborato come segue:
- Il primo carattere è un
r, quindi è abbinato a[a-z]. - Il
+passa al carattere successivo. - Il secondo carattere è un
oe questo è abbinato a[a-z]. - Il
+passa al carattere successivo.
Questa sequenza si ripete finché non premiamo i due punti (: ). La classe di caratteri [a-zA-Z_-] non corrisponde a : simbolo, quindi grep passa alla riga successiva.
Poiché i nomi utente nel passwd sono tutti minuscoli, potremmo anche semplificare la nostra classe di caratteri come segue e ottenere comunque il risultato desiderato:
$ grep -Eo '^[a-z_-]+' /etc/passwd
Esempio:trova un processo
Quando si utilizza ps per grep per un processo, usiamo spesso qualcosa come:
$ ps aux | grep ‘thunderbird’
Ma il ps il comando non elencherà solo il thunderbird processi. Elenca anche il grep comando che abbiamo appena eseguito, poiché grep è anche in esecuzione dopo la pipe ed è mostrato nell'elenco dei processi:
$ ps aux | grep thunderbird
val+ 2196 0.7 2.1 52 33 tty2 Sl+ 16:47 1:55 /usr/lib64/thunderbird/thunderbird
val+ 14064 0.0 0.0 57 82 pts/2 S+ 21:12 0:00 grep --color=auto thunderbird
Possiamo gestirlo aggiungendo grep -v grep per escludere grep dall'output:
$ ps aux | grep thunderbird | grep -v grep
val+ 2196 0.7 2.1 52 33 tty2 Sl+ 16:47 1:55 /usr/lib64/thunderbird/thunderbird
Durante l'utilizzo di grep -v grep farà quello che volevamo, esistono modi migliori per ottenere lo stesso risultato senza biforcare un nuovo grep processo:
$ ps aux | grep [t]hunderbird
val+ 2196 0.7 2.1 52 33 tty2 Sl+ 16:47 1:55 /usr/lib64/thunderbird/thunderbird
Il [t]hunderbird qui corrisponde al letterale t e fa distinzione tra maiuscole e minuscole. Non corrisponderà a grep , ed è per questo che ora vediamo solo thunderbird nell'output.
Questo esempio è solo una dimostrazione della flessibilità di grep cioè, non ti aiuterà a risolvere il tuo albero dei processi. Ci sono strumenti migliori adatti a questo scopo, come pgrep .
Concludi
Usa grep quando si desidera cercare un modello, in un file o in più directory in modo ricorsivo. Cerca di capire come funzionano le espressioni regolari quando grep , poiché le espressioni regolari possono essere potenti.
[Vuoi provare Red Hat Enterprise Linux? Scaricalo ora gratuitamente.]