Interfaccia utente grafica gli elaboratori di testi e le applicazioni per prendere appunti dispongono di informazioni o indicatori di dettaglio per i dettagli dei documenti come il conteggio delle pagine , parole e caratteri , un elenco di intestazioni negli elaboratori di testi, un sommario in alcuni editor di markdown, ecc. e trovare l'occorrenza di parole o frasi è facile come premere Ctrl + F e digitando i caratteri che desideri cercare.
Una GUI rende tutto facile, ma cosa succede quando puoi lavorare solo dalla riga di comando e vuoi controllare il numero di volte in cui una parola, una frase o un carattere ricorre in un file di testo? È facile quasi come quando usi una GUI, purché tu abbia il comando giusto e sto per raccontarti come è fatto.
Supponiamo di avere un example.txt file contenente le frasi:
Praesent in mauris eu tortor porttitor accumsan. Mauris suscipit, ligula sit amet pharetra semper, nibh ante cursus purus, vel sagittis velit mauris vel metus enean fermentum risus.
Puoi usare il comando grep per contare il numero di volte "mauris" appare nel file come mostrato.
$ grep -o -i mauris example.txt | wc -l
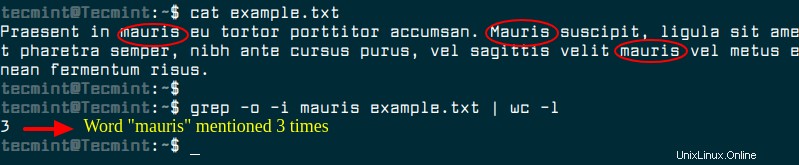
Usando grep -c da solo conterà il numero di righe che contengono la parola corrispondente invece del numero di corrispondenze totali. Il -o opzione è ciò che dice a grep di generare ogni corrispondenza in una riga univoca e quindi wc -l dice a wc di contare il numero di righe. In questo modo viene dedotto il numero totale di parole corrispondenti.
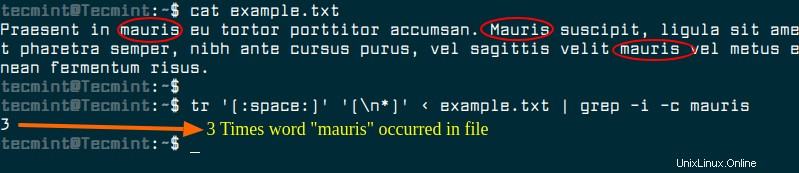
Un approccio diverso consiste nel trasformare il contenuto del file di input con il comando tr in modo che tutte le parole siano in una singola riga e quindi utilizzare grep -c per contare il conteggio delle corrispondenze.
$ tr '[:space:]' '[\n*]' < example.txt | grep -i -c mauris
È così che controlleresti l'occorrenza delle parole dal tuo terminale? Condividi la tua esperienza con noi e facci sapere se hai un altro modo per portare a termine l'attività.