Questa guida fa un tour di alcuni dei migliori strumenti da riga di comando utilizzati per la ricerca di stringhe o modelli corrispondenti nei file di testo. Questi strumenti vengono solitamente utilizzati insieme alle espressioni regolari, abbreviate in REGEX – che sono stringhe univoche per descrivere un modello di ricerca.
Senza ulteriori indugi, tuffiamoci.
1. Comando Grep
Al primo posto c'è lo strumento di utilità grep, acronimo di Global Regular Expression Print , è un potente strumento da riga di comando che è utile durante la ricerca di una stringa o di un pattern specifico in un file.
Grep viene fornito con le moderne distribuzioni Linux per impostazione predefinita e ti offre la flessibilità di restituire vari risultati di ricerca. Con grep puoi eseguire una vasta gamma di funzioni come:
- Cerca stringhe o pattern corrispondenti in un file.
- Cerca stringhe o pattern corrispondenti nei file compressi con Gzip.
- Conta il numero di corrispondenze di stringhe.
- Stampa i numeri di riga che contengono la stringa o il pattern.
- Cerca ricorsivamente la stringa nelle directory.
- Esegui una ricerca inversa (ad es. Visualizza i risultati delle stringhe che non corrispondono ai criteri di ricerca).
- Ignora la distinzione tra maiuscole e minuscole durante la ricerca di stringhe.
La sintassi per l'utilizzo di grep il comando è abbastanza semplice:
$ grep pattern FILE
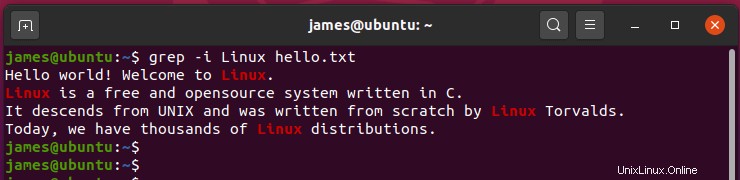
Ad esempio, per cercare la stringa "Linux ' in un file, ad esempio ciao.txt ignorando la distinzione tra maiuscole e minuscole, esegui il comando:
$ grep -i Linux hello.txt

Per ottenere più opzioni che puoi utilizzare con grep , leggi semplicemente il nostro articolo che illustra esempi di comandi grep più avanzati.
2. sed comando
Sed – abbreviazione di Stream Editor – è un altro utile strumento da riga di comando per la manipolazione del testo in un file di testo. Sed ricerca, filtra e sostituisce le stringhe in un dato file in modo non interattivo.
Per impostazione predefinita, sed il comando stampa l'output su STDOUT (Standard ), implicando che il risultato dell'esecuzione viene stampato sul terminale invece di essere salvato in un file.
Il comando Sed viene invocato come segue:
$ sed -OPTIONS command [ file to be edited ]
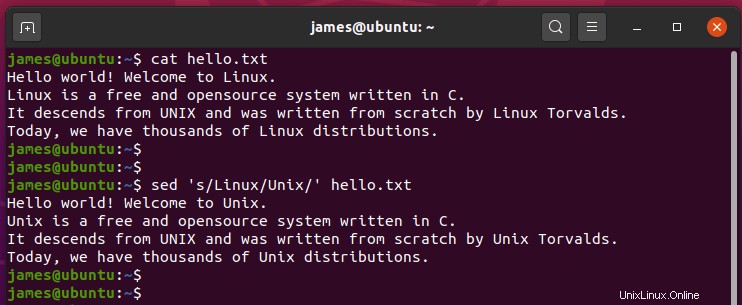
Ad esempio, per sostituire tutte le istanze di "Unix ' con 'Linux ', invoca il comando:
$ sed 's/Unix/Linux' hello.txt
Se vuoi reindirizzare l'output invece di stamparlo sul terminale, usa il segno di reindirizzamento ( > ) come mostrato.
$ sed 's/Unix/Linux' hello.txt > output.txt
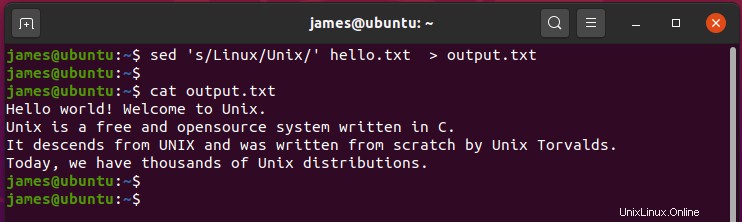
L'output del comando viene salvato in output.txt file invece di essere stampato sullo schermo.
Per verificare più opzioni che possono essere utilizzate, controlla ancora una volta le pagine man.
$ man sed
3. Ack comando
Conferma è uno strumento da riga di comando veloce e portatile scritto in Perl. Conferma è considerato un sostituto amichevole per utilità grep e produce risultati visivamente accattivanti.
Conferma Il comando ricerca nel file o nella directory le righe che contengono la corrispondenza per i criteri di ricerca. Quindi evidenzia la stringa corrispondente nelle righe.
Ack ha la capacità di distinguere i file in base alle loro estensioni e, in una certa misura, al contenuto dei file.
Sintassi del comando Ack:
$ ack [options] PATTERN [FILE...] $ ack -f [options] [DIRECTORY...]
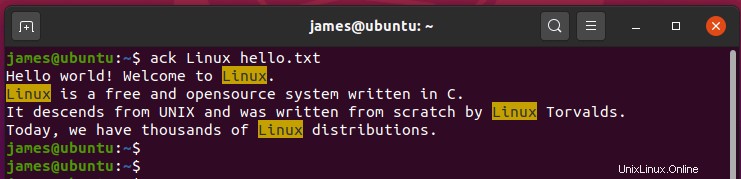
Ad esempio, per cercare il termine di ricerca Linux , esegui:
$ ack Linux hello.txt
Lo strumento di ricerca è abbastanza intelligente e se l'utente non fornisce alcun file o directory, ricerca il modello di ricerca nella directory e nelle sottodirectory correnti.
Nell'esempio seguente non è stato fornito alcun file o directory, ma ack ha rilevato automaticamente il file disponibile e ha cercato il modello di corrispondenza fornito.
$ ack Linux

Per installare ack sul tuo sistema esegui il comando:
$ sudo apt install ack-grep [On Debian/Ubuntu] $ sudo dnf install ack-grep [On CentOS/RHEL]
4. Comando Awk
Awk è un vero e proprio linguaggio di scripting e anche uno strumento di elaborazione del testo e manipolazione dei dati. Cerca file o programmi che contengono il modello di ricerca. Quando viene trovata la stringa o il pattern, awk agisce sulla partita o sulla linea e stampa i risultati su STDOUT .
Il AWK pattern è racchiuso tra parentesi graffe mentre l'intero programma è racchiuso tra virgolette singole.
Prendiamo l'esempio più semplice. Supponiamo che tu stia stampando la data del tuo sistema come mostrato:
$ date

Supponiamo di voler stampare solo il primo valore, che è il giorno della settimana. In tal caso, reindirizza l'output in awk come mostrato:
$ date | awk '{print $1}'
Per visualizzare i valori successivi, separali utilizzando una virgola come mostrato:
$ date | awk '{print $1,$2}'
Il comando sopra visualizzerà il giorno della settimana e la data del mese.

Per ottenere più opzioni che puoi utilizzare con awk , leggi semplicemente la nostra serie di comandi awk.
5. Cercatore d'argento
Silver Searcher è uno strumento di ricerca di codice opensource e multipiattaforma simile a ack ma con un'enfasi sulla velocità. Ti semplifica la ricerca di una stringa specifica all'interno dei file nel più breve tempo possibile:
Sintassi:
$ ag OPTIONS search_pattern /path/to/file
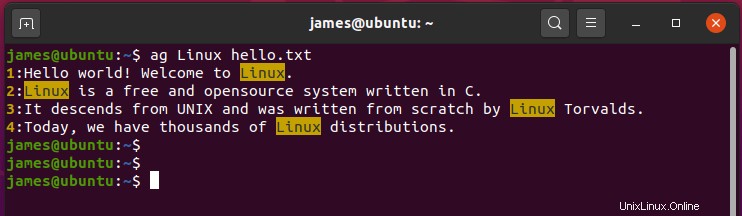
Ad esempio, per cercare la stringa "Linux ' in un file ciao.txt invoca il comando:
$ ag Linux hello.txt
Per ulteriori opzioni, visita le pagine man:
$ man ag
6. Ripgrep
Infine, abbiamo lo strumento da riga di comando ripgrep. Ripgrep è un'utilità multipiattaforma per la ricerca di pattern regex. È molto più veloce di tutti gli strumenti di ricerca menzionati in precedenza e ricerca ricorsivamente nelle directory i modelli di corrispondenza. In termini di velocità e prestazioni, nessun altro strumento si distingue come Ripgrep .
Per impostazione predefinita, ripgrep salterà i file binari/file e directory nascosti. Inoltre, tieni presente che per impostazione predefinita non cercherà i file ignorati da .gitignore/.ignore/.rgignore file.
Ripgrep consente anche di cercare tipi di file specifici. Ad esempio, per limitare la ricerca a Javascript file eseguiti:
$ rg -Tsj
La sintassi per usare ripgrep è abbastanza semplice:
$ rg [OPTIONS] PATTERN [PATH...]
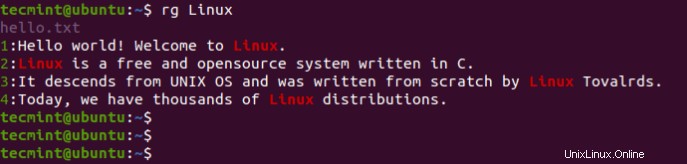
Per esempio. Per cercare le istanze della stringa 'Linux' nei file che si trovano all'interno della directory corrente, esegui il comando:
$ rg Linux
Per installare ripgrep sul tuo sistema esegui i seguenti comandi:
$ sudo apt install ripgrep [On Debian/Ubuntu] $ sudo pacman -S ripgrep [On Arch Linux] $ sudo zypper install ripgrep [On OpenSuse] $ sudo dnf install ripgrep [On CentOS/RHEL/Fedora]
Per ulteriori opzioni, visita le pagine man:
$ man rg
Questi sono alcuni degli strumenti da riga di comando più utilizzati per la ricerca, il filtraggio e la manipolazione del testo in Linux. Se hai altri strumenti che ritieni siano stati tralasciati, faccelo sapere nella sezione commenti.