Apache Spark è un sistema di calcolo distribuito. Si compone di un master e uno o più slave, dove il master distribuisce il lavoro tra gli schiavi, dando così la possibilità di utilizzare i nostri numerosi computer per lavorare su un unico compito. Si potrebbe immaginare che questo sia davvero uno strumento potente in cui le attività richiedono calcoli di grandi dimensioni per essere completate, ma possono essere suddivise in blocchi più piccoli di passaggi che possono essere inviati agli slave su cui lavorare. Una volta che il nostro cluster è attivo e funzionante, possiamo scrivere programmi da eseguire su di esso in Python, Java e Scala.
In questo tutorial lavoreremo su una singola macchina che esegue Red Hat Enterprise Linux 8 e installeremo Spark master e slave sulla stessa macchina, ma tieni presente che i passaggi che descrivono la configurazione dello slave possono essere applicati a qualsiasi numero di computer, creando così un vero e proprio cluster in grado di elaborare carichi di lavoro pesanti. Aggiungeremo anche i file di unità necessari per la gestione ed eseguiremo un semplice esempio sul cluster fornito con il pacchetto distribuito per garantire che il nostro sistema sia operativo.
In questo tutorial imparerai:
- Come installare Spark master e slave
- Come aggiungere file di unità systemd
- Come verificare la corretta connessione master-slave
- Come eseguire un semplice lavoro di esempio sul cluster
 Spark shell con pyspark.
Spark shell con pyspark. Requisiti e convenzioni software utilizzati
| Categoria | Requisiti, convenzioni o versione del software utilizzata |
|---|---|
| Sistema | Red Hat Enterprise Linux 8 |
| Software | Apache Spark 2.4.0 |
| Altro | Accesso privilegiato al tuo sistema Linux come root o tramite sudo comando. |
| Convenzioni | # – richiede che i comandi linux dati vengano eseguiti con i privilegi di root direttamente come utente root o usando sudo comando$ – richiede che i comandi linux dati vengano eseguiti come un normale utente non privilegiato |
Come installare Spark su Redhat 8 istruzioni passo passo
Apache Spark viene eseguito su JVM (Java Virtual Machine), quindi è necessaria un'installazione Java 8 funzionante per l'esecuzione delle applicazioni. A parte questo, ci sono più shell spedite all'interno del pacchetto, una di queste è pyspark , una shell basata su Python. Per lavorare con quello, avrai anche bisogno di python 2 installato e configurato.
- Per ottenere l'URL dell'ultimo pacchetto di Spark, dobbiamo visitare il sito di download di Spark. Dobbiamo scegliere il mirror più vicino alla nostra posizione e copiare l'URL fornito dal sito di download. Ciò significa anche che il tuo URL potrebbe essere diverso dall'esempio seguente. Installeremo il pacchetto in
/opt/, quindi entriamo nella directory comeroot:# cd /opt
E invia l'URL acquisito a
wgetper ricevere il pacco:# wget https://www-eu.apache.org/dist/spark/spark-2.4.0/spark-2.4.0-bin-hadoop2.7.tgz
- Decomprimeremo il tarball:
# tar -xvf spark-2.4.0-bin-hadoop2.7.tgz
- E crea un collegamento simbolico per rendere i nostri percorsi più facili da ricordare nei passaggi successivi:
# ln -s /opt/spark-2.4.0-bin-hadoop2.7 /opt/spark
- Creiamo un utente non privilegiato che eseguirà entrambe le applicazioni, master e slave:
# useradd spark
E impostalo come proprietario dell'intero
/opt/sparkdirectory, ricorsivamente:# chown -R spark:spark /opt/spark*
- Creiamo un
systemdfile dell'unità/etc/systemd/system/spark-master.serviceper il servizio master con il seguente contenuto:[Unit] Description=Apache Spark Master After=network.target [Service] Type=forking User=spark Group=spark ExecStart=/opt/spark/sbin/start-master.sh ExecStop=/opt/spark/sbin/stop-master.sh [Install] WantedBy=multi-user.targetE anche uno per il servizio slave che sarà
/etc/systemd/system/spark-slave.service.servicecon i seguenti contenuti:[Unit] Description=Apache Spark Slave After=network.target [Service] Type=forking User=spark Group=spark ExecStart=/opt/spark/sbin/start-slave.sh spark://rhel8lab.linuxconfig.org:7077 ExecStop=/opt/spark/sbin/stop-slave.sh [Install] WantedBy=multi-user.targetNota l'URL spark evidenziato. Questo è costruito con
spark://<hostname-or-ip-address-of-the-master>:7077, in questo caso la macchina di laboratorio che eseguirà il master ha l'hostnamerhel8lab.linuxconfig.org. Il nome del tuo maestro sarà diverso. Ogni slave deve essere in grado di risolvere questo hostname e raggiungere il master sulla porta specificata, che è la porta7077per impostazione predefinita. - Con i file di servizio attivi, dobbiamo chiedere a
systemdper rileggerli:# systemctl daemon-reload
- Possiamo avviare il nostro master Spark con
systemd:# systemctl start spark-master.service
- Per verificare che il nostro master sia in esecuzione e funzionante, possiamo usare systemd status:
# systemctl status spark-master.service spark-master.service - Apache Spark Master Loaded: loaded (/etc/systemd/system/spark-master.service; disabled; vendor preset: disabled) Active: active (running) since Fri 2019-01-11 16:30:03 CET; 53min ago Process: 3308 ExecStop=/opt/spark/sbin/stop-master.sh (code=exited, status=0/SUCCESS) Process: 3339 ExecStart=/opt/spark/sbin/start-master.sh (code=exited, status=0/SUCCESS) Main PID: 3359 (java) Tasks: 27 (limit: 12544) Memory: 219.3M CGroup: /system.slice/spark-master.service 3359 /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181.b13-9.el8.x86_64/jre/bin/java -cp /opt/spark/conf/:/opt/spark/jars/* -Xmx1g org.apache.spark.deploy.master.Master --host [...] Jan 11 16:30:00 rhel8lab.linuxconfig.org systemd[1]: Starting Apache Spark Master... Jan 11 16:30:00 rhel8lab.linuxconfig.org start-master.sh[3339]: starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-spark-org.apache.spark.deploy.master.Master-1[...]L'ultima riga indica anche il logfile principale del master, che si trova nei
logsdirectory nella directory di base di Spark,/opt/sparknel nostro caso. Esaminando questo file, dovremmo vedere una riga alla fine simile all'esempio seguente:2019-01-11 14:45:28 INFO Master:54 - I have been elected leader! New state: ALIVE
Dovremmo anche trovare una riga che ci dice dove è in ascolto l'interfaccia Master:
2019-01-11 16:30:03 INFO Utils:54 - Successfully started service 'MasterUI' on port 8080
Se puntiamo un browser alla porta della macchina host
8080, dovremmo vedere la pagina di stato del master, al momento nessun lavoratore collegato.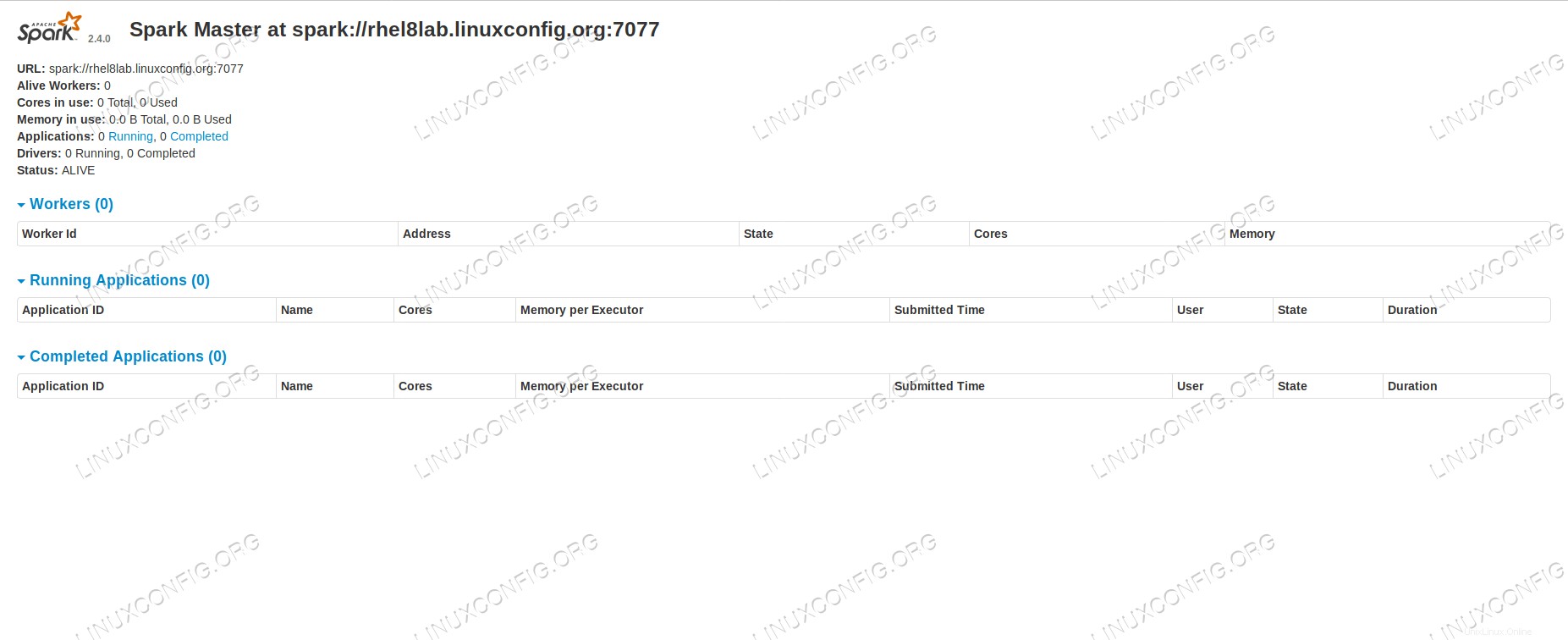 Pagina dello stato principale di Spark senza lavoratori collegati.
Pagina dello stato principale di Spark senza lavoratori collegati. Prendi nota della riga dell'URL nella pagina di stato del master Spark. Questo è lo stesso URL che dobbiamo usare per ogni file di unità slave creato nel
step 5.
Se riceviamo un messaggio di errore "connessione rifiutata" nel browser, probabilmente dobbiamo aprire la porta sul firewall:# firewall-cmd --zone=public --add-port=8080/tcp --permanent success # firewall-cmd --reload success
- Il nostro padrone sta correndo, gli assegneremo uno schiavo. Avviamo il servizio slave:
# systemctl start spark-slave.service
- Possiamo verificare che il nostro slave sia in esecuzione con systemd:
# systemctl status spark-slave.service spark-slave.service - Apache Spark Slave Loaded: loaded (/etc/systemd/system/spark-slave.service; disabled; vendor preset: disabled) Active: active (running) since Fri 2019-01-11 16:31:41 CET; 1h 3min ago Process: 3515 ExecStop=/opt/spark/sbin/stop-slave.sh (code=exited, status=0/SUCCESS) Process: 3537 ExecStart=/opt/spark/sbin/start-slave.sh spark://rhel8lab.linuxconfig.org:7077 (code=exited, status=0/SUCCESS) Main PID: 3554 (java) Tasks: 26 (limit: 12544) Memory: 176.1M CGroup: /system.slice/spark-slave.service 3554 /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181.b13-9.el8.x86_64/jre/bin/java -cp /opt/spark/conf/:/opt/spark/jars/* -Xmx1g org.apache.spark.deploy.worker.Worker [...] Jan 11 16:31:39 rhel8lab.linuxconfig.org systemd[1]: Starting Apache Spark Slave... Jan 11 16:31:39 rhel8lab.linuxconfig.org start-slave.sh[3537]: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-spar[...]Questo output fornisce anche il percorso del file di registro dello slave (o lavoratore), che sarà nella stessa directory, con "lavoratore" nel nome. Controllando questo file, dovremmo vedere qualcosa di simile al seguente output:
2019-01-11 14:52:23 INFO Worker:54 - Connecting to master rhel8lab.linuxconfig.org:7077... 2019-01-11 14:52:23 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@62059f4a{/metrics/json,null,AVAILABLE,@Spark} 2019-01-11 14:52:23 INFO TransportClientFactory:267 - Successfully created connection to rhel8lab.linuxconfig.org/10.0.2.15:7077 after 58 ms (0 ms spent in bootstraps) 2019-01-11 14:52:24 INFO Worker:54 - Successfully registered with master spark://rhel8lab.linuxconfig.org:7077Ciò indica che il lavoratore è connesso correttamente al master. In questo stesso file di log troveremo una riga che ci dice l'URL su cui sta ascoltando il lavoratore:
2019-01-11 14:52:23 INFO WorkerWebUI:54 - Bound WorkerWebUI to 0.0.0.0, and started at http://rhel8lab.linuxconfig.org:8081
Possiamo puntare il nostro browser alla pagina di stato del lavoratore, dove è elencato il suo master.
 Pagina di stato del lavoratore Spark, collegata al master.
Pagina di stato del lavoratore Spark, collegata al master. Nel file di registro del master dovrebbe apparire una riga di verifica:
2019-01-11 14:52:24 INFO Master:54 - Registering worker 10.0.2.15:40815 with 2 cores, 1024.0 MB RAM
Se ricarichiamo ora la pagina di stato del master, anche il lavoratore dovrebbe apparire lì, con un collegamento alla sua pagina di stato.
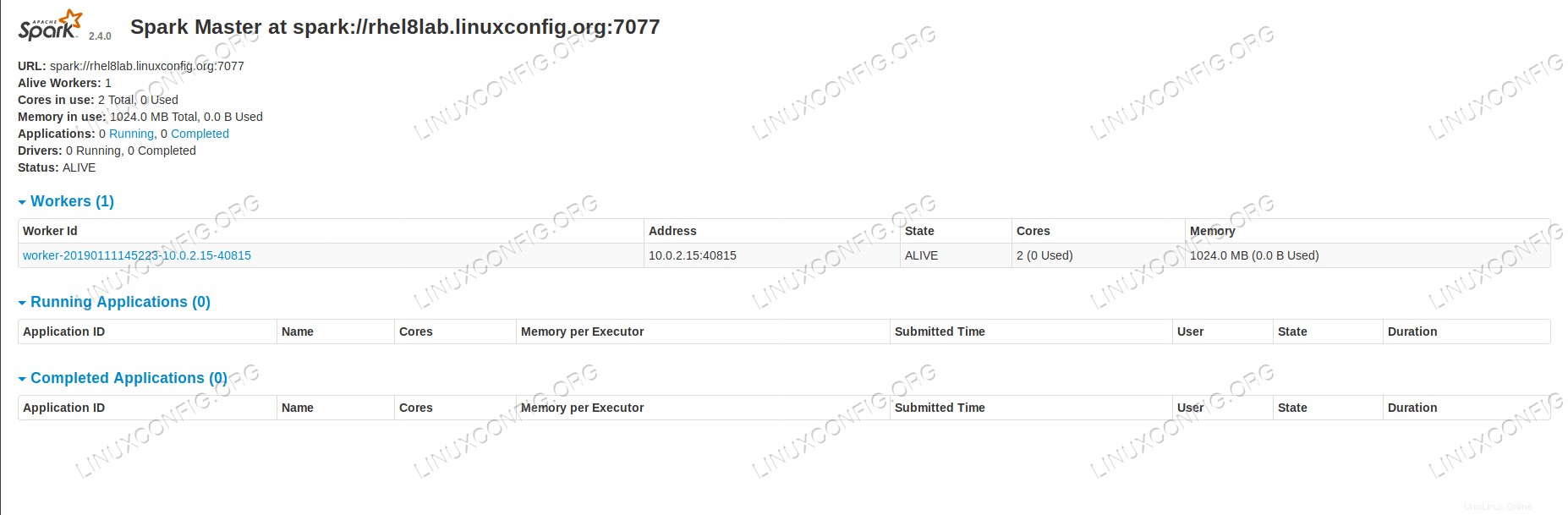 Pagina dello stato principale di Spark con un lavoratore allegato.
Pagina dello stato principale di Spark con un lavoratore allegato. Queste fonti verificano che il nostro cluster sia collegato e pronto per funzionare.
- Per eseguire una semplice attività sul cluster, eseguiamo uno degli esempi forniti con il pacchetto che abbiamo scaricato. Considera il seguente semplice file di testo
/opt/spark/test.file:line1 word1 word2 word3 line2 word1 line3 word1 word2 word3 word4Eseguiremo il
wordcount.pyesempio su di esso che conterà l'occorrenza di ogni parola nel file. Possiamo usare lasparkutente, nessunrootprivilegi necessari.$ /opt/spark/bin/spark-submit /opt/spark/examples/src/main/python/wordcount.py /opt/spark/test.file 2019-01-11 15:56:57 INFO SparkContext:54 - Submitted application: PythonWordCount 2019-01-11 15:56:57 INFO SecurityManager:54 - Changing view acls to: spark 2019-01-11 15:56:57 INFO SecurityManager:54 - Changing modify acls to: spark [...]
Durante l'esecuzione dell'attività, viene fornito un output lungo. Verso la fine dell'output, viene mostrato il risultato, il cluster calcola le informazioni necessarie:
2019-01-11 15:57:05 INFO DAGScheduler:54 - Job 0 finished: collect at /opt/spark/examples/src/main/python/wordcount.py:40, took 1.619928 s line3: 1 line2: 1 line1: 1 word4: 1 word1: 3 word3: 2 word2: 2 [...]
Con questo abbiamo visto il nostro Apache Spark in azione. È possibile installare e collegare ulteriori nodi slave per scalare la potenza di calcolo del nostro cluster.