Apache Kafka è una piattaforma di streaming distribuita. Con il suo ricco set di API (Application Programming Interface), possiamo collegare praticamente qualsiasi cosa a Kafka come fonte di dati e, dall'altra parte, possiamo impostare un gran numero di consumatori che riceveranno il vapore di record per l'elaborazione. Kafka è altamente scalabile e archivia i flussi di dati in modo affidabile e tollerante ai guasti. Dal punto di vista della connettività, Kafka può fungere da ponte tra molti sistemi eterogenei, che a loro volta possono fare affidamento sulle sue capacità di trasferire e mantenere i dati forniti.
In questo tutorial installeremo Apache Kafka su un Red Hat Enterprise Linux 8, creeremo il systemd unit file per semplificare la gestione e testare la funzionalità con gli strumenti a riga di comando forniti.
In questo tutorial imparerai:
- Come installare Apache Kafka
- Come creare servizi di sistema per Kafka e Zookeeper
- Come testare Kafka con client a riga di comando
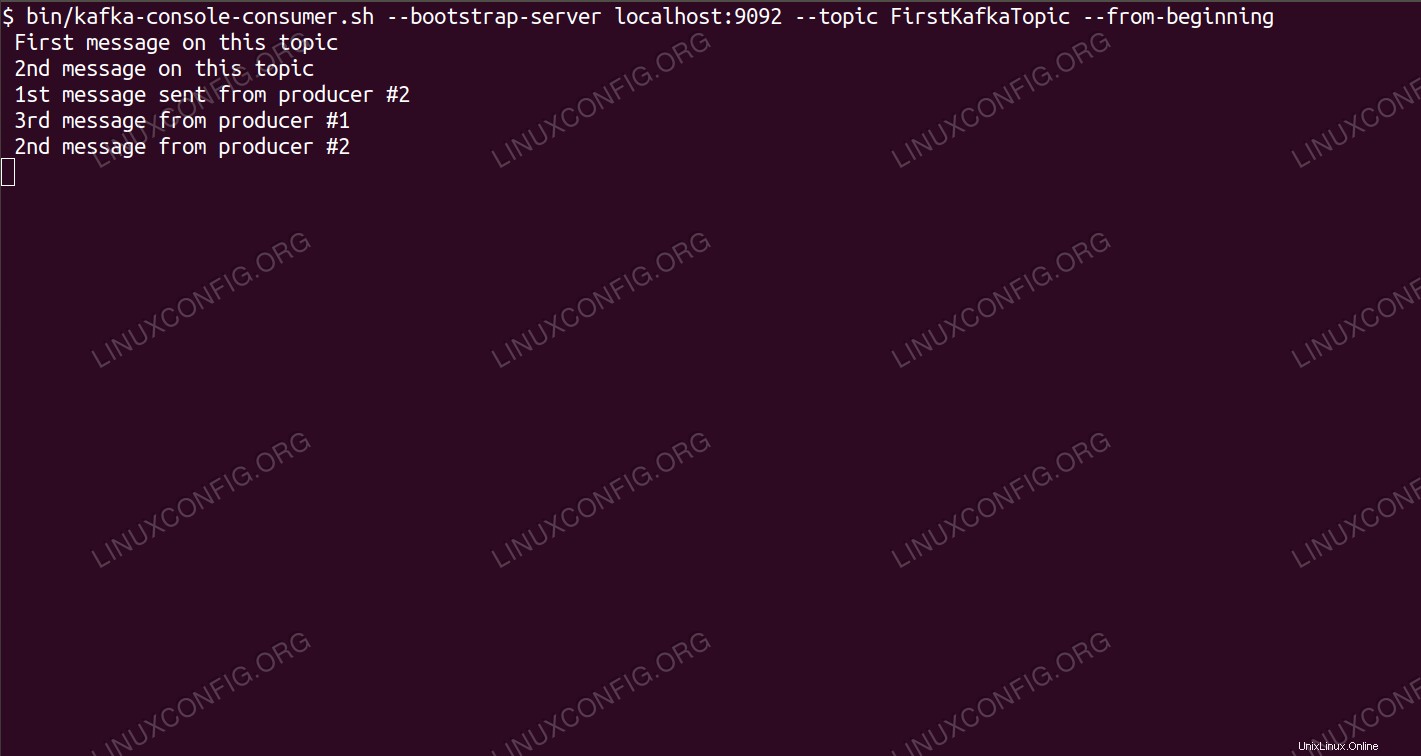 Consumare messaggi sull'argomento Kafka dalla riga di comando.
Consumare messaggi sull'argomento Kafka dalla riga di comando. Requisiti e convenzioni software utilizzati
| Categoria | Requisiti, convenzioni o versione del software utilizzata |
|---|---|
| Sistema | Red Hat Enterprise Linux 8 |
| Software | Apache Kafka 2.11 |
| Altro | Accesso privilegiato al tuo sistema Linux come root o tramite sudo comando. |
| Convenzioni | # – richiede che i comandi linux dati vengano eseguiti con i privilegi di root direttamente come utente root o usando sudo comando$ – richiede che i comandi linux dati vengano eseguiti come un normale utente non privilegiato |
Come installare kafka su Redhat 8 istruzioni passo passo
Apache Kafka è scritto in Java, quindi tutto ciò di cui abbiamo bisogno è OpenJDK 8 installato per procedere con l'installazione. Kafka si affida ad Apache Zookeeper, un servizio di coordinamento distribuito, anch'esso scritto in Java, e spedito con il pacchetto che scaricheremo. Anche se l'installazione di servizi HA (High Availability) su un singolo nodo elimina il loro scopo, installeremo ed eseguiremo Zookeeper per il bene di Kafka.
- Per scaricare Kafka dal mirror più vicino, è necessario consultare il sito di download ufficiale. Possiamo copiare l'URL del
.tar.gzfile da lì. Useremowgete l'URL incollato per scaricare il pacchetto sulla macchina di destinazione:# wget https://www-eu.apache.org/dist/kafka/2.1.0/kafka_2.11-2.1.0.tgz -O /opt/kafka_2.11-2.1.0.tgz
- Inseriamo il
/optdirectory ed estrarre l'archivio:# cd /opt # tar -xvf kafka_2.11-2.1.0.tgz
E crea un collegamento simbolico chiamato
/opt/kafkache punta al/opt/kafka_2_11-2.1.0ora creato directory per semplificarci la vita.ln -s /opt/kafka_2.11-2.1.0 /opt/kafka
- Creiamo un utente non privilegiato che eseguirà entrambi
zookeeperekafkaservizio.# useradd kafka
- E imposta il nuovo utente come proprietario dell'intera directory che abbiamo estratto, in modo ricorsivo:
# chown -R kafka:kafka /opt/kafka*
- Creiamo il file dell'unità
/etc/systemd/system/zookeeper.servicecon il seguente contenuto:[Unit] Description=zookeeper After=syslog.target network.target [Service] Type=simple User=kafka Group=kafka ExecStart=/opt/kafka/bin/zookeeper-server-start.sh /opt/kafka/config/zookeeper.properties ExecStop=/opt/kafka/bin/zookeeper-server-stop.sh [Install] WantedBy=multi-user.targetNota che non è necessario scrivere il numero di versione tre volte a causa del collegamento simbolico che abbiamo creato. Lo stesso vale per il prossimo file di unità per Kafka,
/etc/systemd/system/kafka.service, che contiene le seguenti righe di configurazione:[Unit] Description=Apache Kafka Requires=zookeeper.service After=zookeeper.service [Service] Type=simple User=kafka Group=kafka ExecStart=/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties ExecStop=/opt/kafka/bin/kafka-server-stop.sh [Install] WantedBy=multi-user.target - Dobbiamo ricaricare
systemdper farlo leggere i nuovi file di unità:# systemctl daemon-reload
- Ora possiamo avviare i nostri nuovi servizi (in questo ordine):
# systemctl start zookeeper # systemctl start kafka
Se tutto va bene,
systemddovrebbe riportare lo stato di esecuzione sullo stato di entrambi i servizi, in modo simile alle uscite seguenti:# systemctl status zookeeper.service zookeeper.service - zookeeper Loaded: loaded (/etc/systemd/system/zookeeper.service; disabled; vendor preset: disabled) Active: active (running) since Thu 2019-01-10 20:44:37 CET; 6s ago Main PID: 11628 (java) Tasks: 23 (limit: 12544) Memory: 57.0M CGroup: /system.slice/zookeeper.service 11628 java -Xmx512M -Xms512M -server [...] # systemctl status kafka.service kafka.service - Apache Kafka Loaded: loaded (/etc/systemd/system/kafka.service; disabled; vendor preset: disabled) Active: active (running) since Thu 2019-01-10 20:45:11 CET; 11s ago Main PID: 11949 (java) Tasks: 64 (limit: 12544) Memory: 322.2M CGroup: /system.slice/kafka.service 11949 java -Xmx1G -Xms1G -server [...] - Opzionalmente possiamo abilitare l'avvio automatico all'avvio per entrambi i servizi:
# systemctl enable zookeeper.service # systemctl enable kafka.service
- Per testare la funzionalità, ci collegheremo a Kafka con un produttore e un cliente consumatore. I messaggi forniti dal produttore dovrebbero apparire sulla console del consumatore. Ma prima di questo abbiamo bisogno di un mezzo su cui questi due messaggi si scambiano. Creiamo un nuovo canale di dati chiamato
topicnei termini di Kafka, dove il fornitore pubblicherà e dove il consumatore si abbonerà. Chiameremo l'argomentoFirstKafkaTopic. Useremo ilkafkautente per creare l'argomento:$ /opt/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic FirstKafkaTopic
- Avviamo un client consumer dalla riga di comando che sottoscriverà l'argomento (a questo punto vuoto) creato nel passaggio precedente:
$ /opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic FirstKafkaTopic --from-beginning
Lasciamo aperti la console e il client in esecuzione. Questa console è dove riceveremo il messaggio che pubblichiamo con il client produttore.
- Su un altro terminale, avviamo un client produttore e pubblichiamo alcuni messaggi sull'argomento che abbiamo creato. Possiamo interrogare Kafka per gli argomenti disponibili:
$ /opt/kafka/bin/kafka-topics.sh --list --zookeeper localhost:2181 FirstKafkaTopic
E connettiti a quello a cui è abbonato il consumatore, quindi invia un messaggio:
$ /opt/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic FirstKafkaTopic > new message published by producer from console #2
Al terminale del consumatore dovrebbe apparire a breve il messaggio:
$ /opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic FirstKafkaTopic --from-beginning new message published by producer from console #2
Se viene visualizzato il messaggio, il nostro test ha esito positivo e la nostra installazione di Kafka funziona come previsto. Molti clienti potrebbero fornire e consumare uno o più record di argomenti allo stesso modo, anche con l'impostazione di un singolo nodo che abbiamo creato in questo tutorial.