Introduzione
I dati mancanti sono un problema comune quando si lavora con set di dati realistici. Conoscere e analizzare le cause dei valori mancanti aiuta a fornire un quadro più chiaro dei passaggi per risolvere il problema. Python fornisce molti metodi per analizzare e risolvere il problema dei dati non contabilizzati.
Questo tutorial spiega le cause e le soluzioni dei dati mancanti attraverso un esempio pratico in Python.

Prerequisiti
- Python 3 installato e configurato
- Moduli Panda e NumPy installati
- Un set di dati con valori mancanti
In che modo i dati mancanti influiscono sul tuo algoritmo?
Esistono tre modi in cui i dati mancanti influiscono sull'algoritmo e sulla ricerca:
- I valori mancanti forniscono un'idea sbagliata sui dati stessi, causando ambiguità . Ad esempio, il calcolo di una media per una colonna con metà delle informazioni non disponibili o impostata su zero fornisce la metrica errata.
- Quando i dati non sono disponibili, alcuni algoritmi non funzionano. Alcuni algoritmi di machine learning con set di dati contenenti NaN (Non un numero) i valori generano un errore.
- Il modello dei dati mancanti è un fattore essenziale. Se i dati di un set di dati mancano casualmente, le informazioni sono comunque utili nella maggior parte dei casi. Tuttavia, se mancano informazioni sistematicamente, tutte le analisi sono distorte.
Cosa può causare la mancanza di dati?
La causa dei dati mancanti dipende dai metodi di raccolta dei dati. L'identificazione della causa aiuta a determinare quale percorso intraprendere durante l'analisi di un set di dati.
Ecco alcuni esempi del motivo per cui i set di dati hanno valori mancanti:
Sondaggi . I dati raccolti attraverso i sondaggi spesso contengono informazioni mancanti. Che sia per motivi di privacy o semplicemente per non conoscere una risposta a una domanda specifica, i questionari spesso contengono dati mancanti.
IoT . Molti problemi sorgono quando si lavora con i dispositivi IoT e si raccolgono dati dai sistemi di sensori ai server di edge computing. Una perdita temporanea di comunicazione o un sensore malfunzionante spesso causa la scomparsa di parti di dati.
Accesso limitato . Alcuni dati hanno un accesso limitato, in particolare i dati protetti da HIPAA, GDPR e altre normative.
Errore manuale . I dati inseriti manualmente di solito presentano incongruenze a causa della natura del lavoro o della grande quantità di informazioni.
Come gestire i dati mancanti?
Per analizzare e spiegare il processo su come gestire i dati mancanti in Python, useremo:
- Il set di dati dei permessi di costruzione di San Francisco
- Ambiente Jupyter Notebook
Le idee si applicano a diversi set di dati e ad altri IDE ed editor Python.
Importa e visualizza i dati
Scarica il set di dati e copia il percorso del file. Utilizzando la libreria Pandas, importa e archivia il Building_Permits.csv dati in una variabile:
import pandas as pd
data = pd.read_csv('<path to Building_Permits.csv>')Per confermare i dati importati correttamente, eseguire:
data.head()Il comando mostra le prime righe dei dati in formato tabulare:
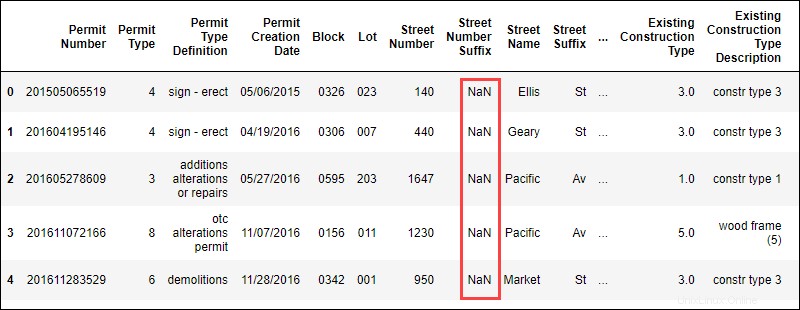
La presenza di NaN valori indica che mancano dati in questo set di dati.
Trova i valori mancanti
Trova quanti valori mancanti ci sono per colonna eseguendo:
data.isnull().sum()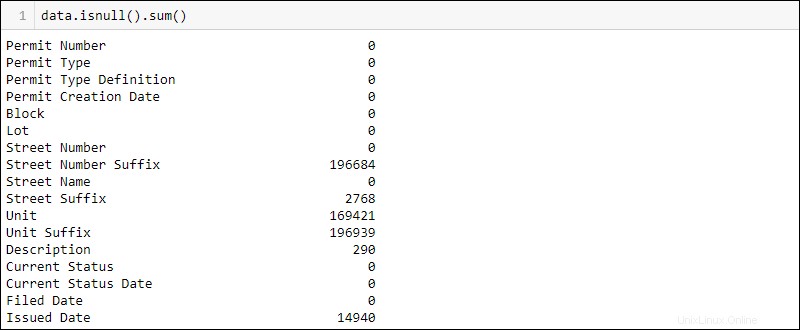
I numeri forniscono più significato se visualizzati come percentuali. Per visualizzare le somme in percentuale, dividi il numero per la lunghezza totale del set di dati:
data.isnull().sum()/len(data)
Per mostrare prima le colonne con la percentuale più alta di dati mancanti, aggiungi .sort_values(ascending=False) alla riga di codice precedente:
data.isnull().sum().sort_values(ascending = False)/len(data)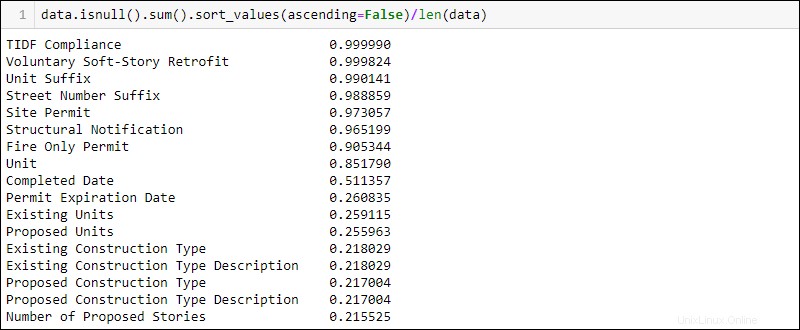
Prima di rimuovere o modificare qualsiasi valore, controllare la documentazione per eventuali motivi per cui mancano dati. Ad esempio, la colonna Conformità TIDF ha quasi tutti i dati mancanti. Tuttavia, la documentazione afferma che si tratta di un nuovo requisito legale, quindi è logico che manchi la maggior parte dei valori.
Segna i valori mancanti
Visualizza i dati statistici generali per un set di dati eseguendo:
data.describe()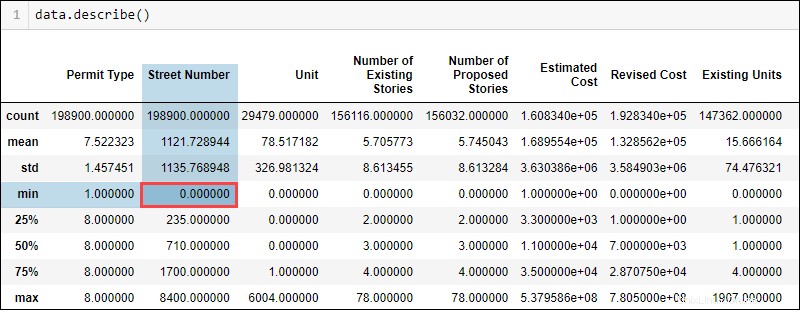
A seconda del tipo di dati e della conoscenza del dominio, alcuni valori non si adattano logicamente. Ad esempio, un numero civico non può essere zero. Tuttavia, il valore minimo mostra zero, indicando i probabili valori mancanti nella colonna del numero civico.
Per vedere quanti Numero civico i valori sono 0, esegui:
(data['Street Number'] == 0).sum()Usando la libreria NumPy, scambia il valore con NaN per indicare l'informazione mancante:
import numpy as np
data['Street Number'] = data['Street Number'].replace(0, np.nan)Il controllo dei dati statistici aggiornati ora indica che il numero civico minimo è 1.
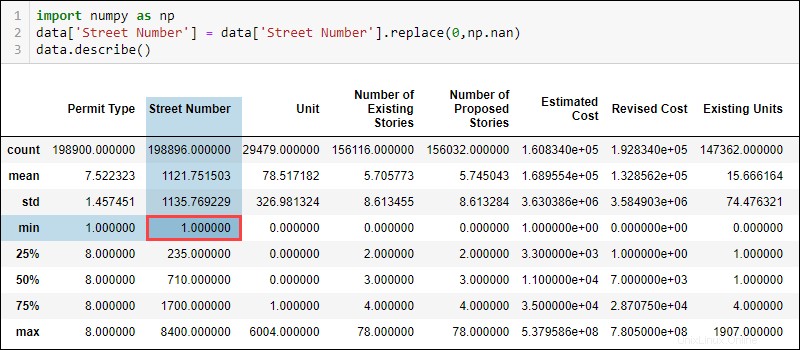
Allo stesso modo, la somma dei valori NaN ora mostra che mancano dati nella colonna del numero civico.
Cambiano anche altri valori nella colonna Numero civico, come il conteggio e la media. La differenza non è enorme perché solo alcuni valori sono 0. Tuttavia, con quantità più significative di dati etichettati in modo errato, anche le differenze nelle metriche sono più evidenti.
Elimina i valori mancanti
Il modo più semplice per gestire i valori mancanti in Python è eliminare le righe o le colonne in cui mancano le informazioni.
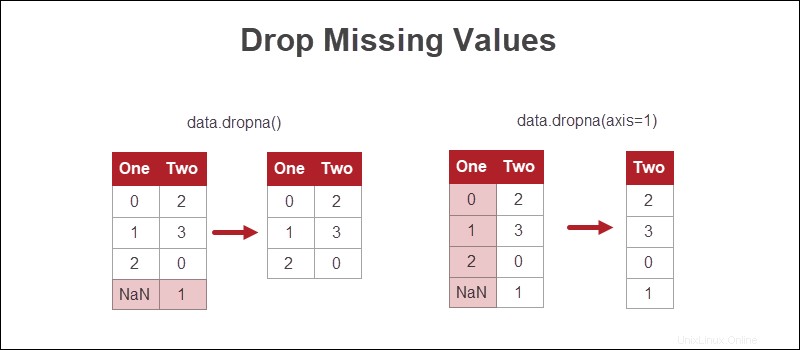
Sebbene questo approccio sia il più rapido, la perdita di dati non è l'opzione più praticabile. Se possibile, sono preferibili altri metodi.
Rilascia righe con valori mancanti
Per rimuovere le righe con valori mancanti, utilizza il dropna funzione:
data.dropna()Quando viene applicata al set di dati di esempio, la funzione rimuove tutte le righe di dati perché ogni riga di dati ne contiene almeno una Valore NaN.
Rilascia colonne con valori mancanti
Per rimuovere le colonne con valori mancanti, utilizza il dropna funzione e fornire l'asse:
data.dropna(axis = 1)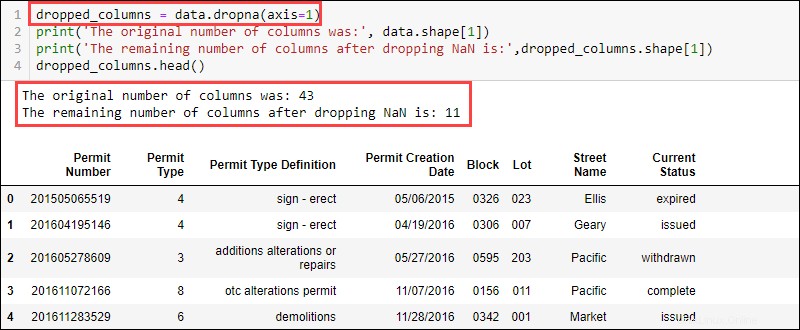
Il set di dati ora contiene 11 colonne rispetto alle 43 inizialmente disponibili.
Imposta valori mancanti
L'imputazione è un metodo per riempire i valori mancanti con numeri utilizzando una strategia specifica. Alcune opzioni da considerare per l'imputazione sono:
- Un valore medio, mediano o modale da quella colonna.
- Un valore distinto, come 0 o -1.
- Un valore selezionato casualmente dal set esistente.
- Valori stimati utilizzando un modello predittivo.
Il modulo Pandas DataFrame fornisce un metodo per riempire i valori NaN utilizzando varie strategie. Ad esempio, per sostituire tutti i valori NaN con 0:
data.fillna(0)
Il fillna La funzione fornisce diversi metodi per sostituire i valori mancanti. Il riempimento è un metodo comune che riempie l'informazione mancante con qualsiasi valore venga dopo:
data.fillna(method = 'bfill')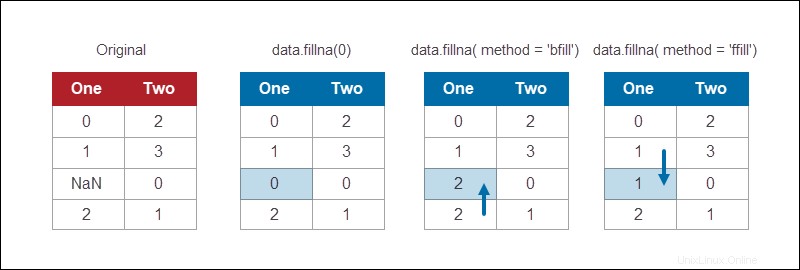
Se manca l'ultimo valore, riempire tutti i restanti NaN con il valore desiderato. Ad esempio, per riempire tutti i valori possibili e riempire i restanti con 0, utilizzare:
data.fillna(method = 'bfill', axis = 0).fillna(0)Allo stesso modo, usa riempimento per riempire i valori in avanti. Entrambi i metodi di riempimento in avanti e all'indietro funzionano quando i dati hanno un ordine logico.
Algoritmi che supportano i valori mancanti
Esistono algoritmi di apprendimento automatico robusti con dati mancanti. Alcuni esempi includono:
- kNN (k-vicino più vicino)
- Baie ingenue
Altri algoritmi, come gli alberi di classificazione o di regressione, utilizzano le informazioni non disponibili come identificatore univoco.