Apache Cassandra è uno dei database NoSQL più popolari. Sebbene siano disponibili altre versioni di NoSQL. Ma perché Apache Cassandra è popolare? diamo un'occhiata. Qui vedremo le funzionalità e l'installazione di Apache Cassandra.
Introduzione
Organizzazioni che gestiscono un'enorme quantità di dati non strutturati, preferendoli. È un database NoSQL basato su Java. Senza uno schema fisso, Cassandra è in grado di gestire e gestire un volume di dati davvero enorme. Funziona con il modello Peer to peer-based, in cui ogni nodo è connesso a tutti gli altri nodi. I nodi hanno l'autorizzazione di lettura-scrittura, quindi non è necessario un nodo master. Puoi aggiungere infiniti nodi nel cluster.
Caratteristiche
1. Architettura peer-to-peer
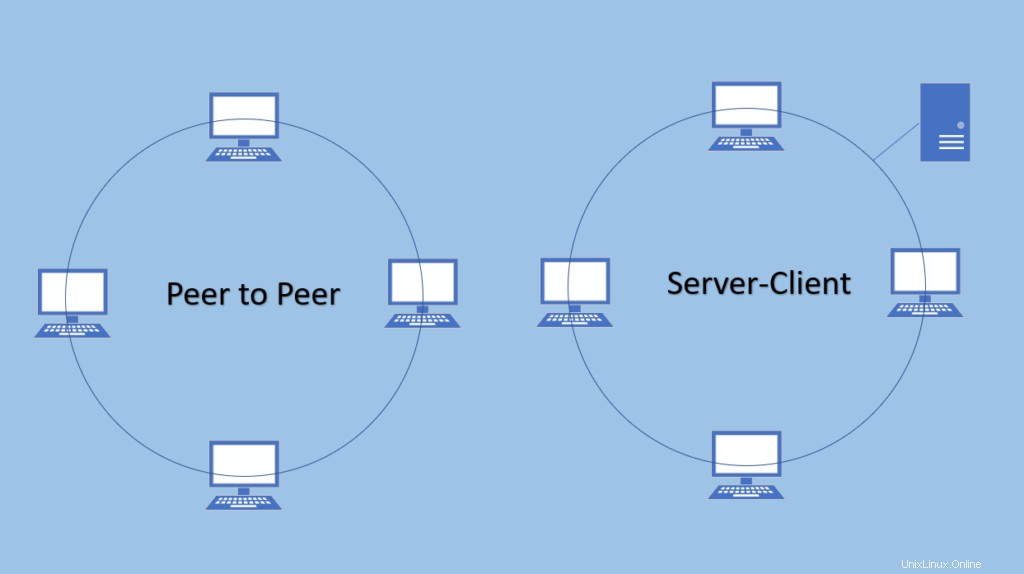
Non esiste alcuna dipendenza dal server master, tutti i nodi vengono trattati allo stesso modo qui. Non c'è alcun punto in errore a causa del modello peer to peer e server.
2. Alta scalabilità
A causa del design del throughput di lettura/scrittura. Viene aggiunto un nuovo nodo o macchina, senza interrompere alcuna applicazione in esecuzione o operazioni in tempo reale.
3. Tolleranza ai guasti
Ogni nodo ha la stessa copia di dati. Supponiamo che ci siano 5 nodi nel cluster e uno di questi smetta di funzionare, quel nodo difettoso può essere rimosso rapidamente.
4. Archiviazione dati flessibile
Può supportare tutti i tipi di dati strutturati come formati di dati semi-strutturati, strutturati e non strutturati.
5. Archiviazione e accesso rapidi ai dati
Può funzionare anche su strutture hardware economiche, può archiviare un'enorme quantità di dati senza sacrificare la velocità del data center.
Installazione
Prerequisiti:
- In questa dimostrazione di installazione, utilizzeremo Rocky Linux.
- Sono necessari JAVA e YUM aggiornati per completare la configurazione.
Aggiorna prima il sistema:
# yum update Installa JAVA e Python
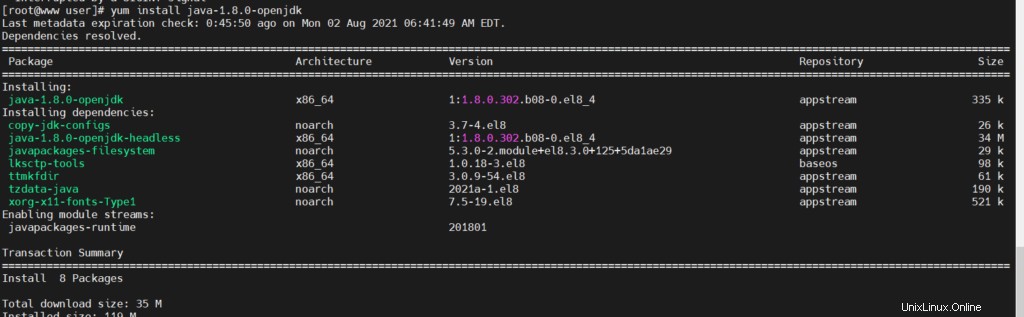
# yum install java-1.8.0-openjdk
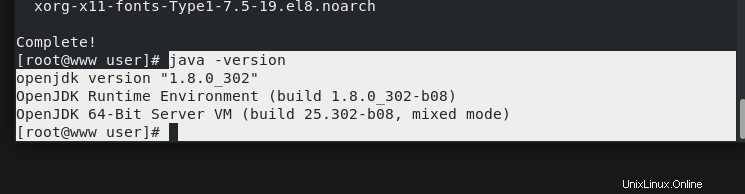
Dopo l'esecuzione del comando, controlla quale versione di JAVA è installata.
# java -versionopenjdk version "1.8.0_302"
OpenJDK Runtime Environment (build 1.8.0_302-b08)
OpenJDK 64-Bit Server VM (build 25.302-b08, mixed mode)
Ora installiamo il repository Cassandra sul server.
Crea un nuovo file repository per Cassandra, modifica il file come segue.
$ sudo vim /etc/yum.repos.d/cassandra.repo[cassandra]
name=Apache Cassandra
baseurl=https://downloads.apache.org/cassandra/redhat/40x/
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://downloads.apache.org/cassandra/KEYS
Installa il pacchetto.
$ sudo yum install cassandra -yModifica le impostazioni richieste per il cluster.
Il cluster predefinito denominato "Test Cluster" per impostazione predefinita. È necessario rinominarlo. Tutte le configurazioni sono archiviate in /etc/cassandra . Tutti i dati del cluster vengono archiviati in /var/lib/cassandra
Cambia il nome del cluster, passa alla riga di comando.
# cqlsh
cqlsh> UPDATE system.local SET cluster_name = 'unixcop Cluster' WHERE KEY = 'local';
# service cassandra restart
Aprire cassandra.yaml, rinominare il nome del cluster. Salva il file ed esci.
# cd /etc/cassandra/default.confApri il file e apporta le modifiche richieste.
# vim cassandra.yaml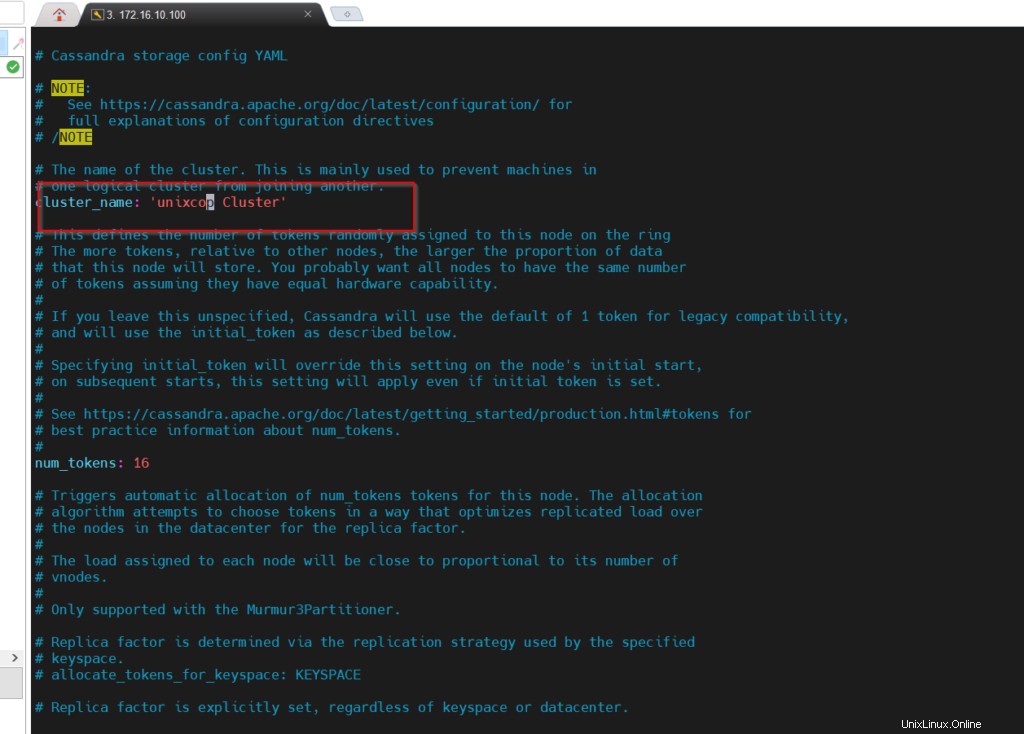
Riavvia il servizio e ci siamo.
Conclusione
Oggi abbiamo mostrato come configurare e rinominare il database Cassandra. Sebbene sia uno dei database NoSQL più popolari, non è adatto a tutti i requisiti di database complicati. Inizialmente era un progetto open source, ora parte del progetto Apache.