Che cos'è un filesystem? Secondo il primo collaboratore e autore di Linux, Robert Love, "Un filesystem è un archivio gerarchico di dati che aderiscono a una struttura specifica". Tuttavia, questa descrizione si applica ugualmente bene a VFAT (Virtual File Allocation Table), Git e Cassandra (un database NoSQL). Quindi cosa distingue un filesystem?
Nozioni di base sui filesystem
Il kernel Linux richiede che un'entità sia un filesystem, deve anche implementare open() , leggi() e scrivi() metodi su oggetti persistenti a cui sono associati nomi. Dal punto di vista della programmazione orientata agli oggetti, il kernel tratta il filesystem generico come un'interfaccia astratta e queste tre grandi funzioni sono "virtuali", senza una definizione predefinita. Di conseguenza, l'implementazione del filesystem di default del kernel è chiamata filesystem virtuale (VFS).
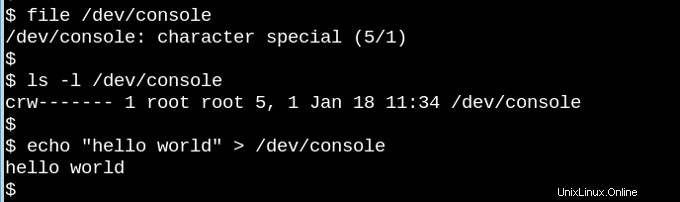
VFS è alla base della famosa osservazione che nei sistemi simili a Unix "tutto è un file". Considera quanto sia strano che la piccola demo qui sopra contenga il dispositivo del personaggio /dev/console funziona davvero. L'immagine mostra una sessione Bash interattiva su una telescrivente virtuale (tty). L'invio di una stringa al dispositivo della console virtuale la fa apparire sullo schermo virtuale. VFS ha altre proprietà ancora più strane. Ad esempio, è possibile cercare in esse.
Più risorse Linux
- Comandi Linux cheat sheet
- Cheat sheet sui comandi avanzati di Linux
- Corso online gratuito:Panoramica tecnica RHEL
- Cheat sheet della rete Linux
- Cheat sheet di SELinux
- Cheat sheet dei comandi comuni di Linux
- Cosa sono i container Linux?
- I nostri ultimi articoli su Linux
I filesystem familiari come ext4, NFS e /proc forniscono tutti le definizioni delle tre grandi funzioni in una struttura di dati in linguaggio C chiamata file_operations. Inoltre, particolari filesystem estendono e sovrascrivono le funzioni VFS nel modo familiare orientato agli oggetti. Come sottolinea Robert Love, l'astrazione di VFS consente agli utenti Linux di copiare allegramente file da e verso sistemi operativi estranei o entità astratte come pipe senza preoccuparsi del formato dei dati interni. Per conto dello spazio utente, tramite una chiamata di sistema, un processo può copiare da un file nelle strutture dati del kernel con il metodo read() di un filesystem, quindi utilizzare il metodo write() di un altro tipo di filesystem per produrre i dati.
Le definizioni delle funzioni che appartengono allo stesso tipo di base VFS si trovano nei file fs/*.c nel sorgente del kernel, mentre le sottodirectory di fs/ contengono i filesystem specifici. Il kernel contiene anche entità simili a filesystem come cgroups, /dev e tmpfs, che sono necessarie all'inizio del processo di avvio e sono quindi definite nella sottodirectory init/ del kernel. Nota che cgroups, /dev e tmpfs non chiamano le tre funzioni di file_operations, ma leggono e scrivono direttamente nella memoria.
Il diagramma seguente illustra approssimativamente come lo spazio utente accede a vari tipi di filesystem comunemente montati su sistemi Linux. Non vengono mostrati costrutti come pipe, dmesg e POSIX clock che implementano anche struct file_operations e i cui accessi quindi passano attraverso il livello VFS.
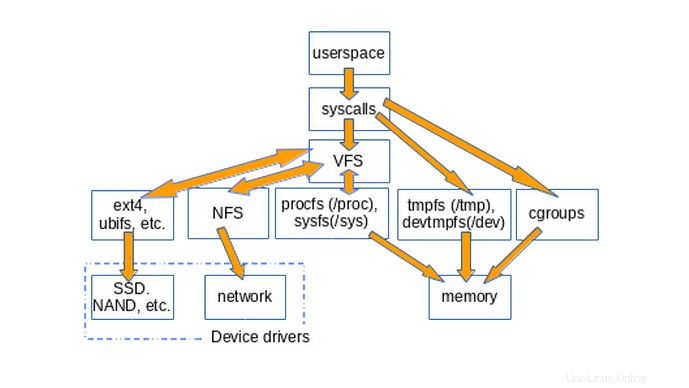
L'esistenza di VFS promuove il riutilizzo del codice, poiché i metodi di base associati ai filesystem non devono essere re-implementati da ogni tipo di filesystem. Il riutilizzo del codice è una best practice di ingegneria del software ampiamente accettata! Purtroppo, se il codice riutilizzato introduce bug seri, tutte le implementazioni che ereditano i metodi comuni ne soffrono.
/tmp:un semplice consiglio
Un modo semplice per scoprire quali VFS sono presenti su un sistema è digitare mount | grep -v sd | grep -v :/ , che elencherà tutti i filesystem montati che non risiedono su un disco e non NFS sulla maggior parte dei computer. Uno dei mount VFS elencati sarà sicuramente /tmp, giusto?

Perché è sconsigliabile mantenere /tmp in memoria? Perché i file in /tmp sono temporanei(!) e i dispositivi di archiviazione sono più lenti della memoria, dove vengono creati tmpfs. Inoltre, i dispositivi fisici sono più soggetti all'usura dovuta alla scrittura frequente rispetto alla memoria. Infine, i file in /tmp possono contenere informazioni riservate, quindi farli sparire ad ogni riavvio è una caratteristica.
Sfortunatamente, gli script di installazione per alcune distribuzioni Linux creano ancora /tmp su un dispositivo di archiviazione per impostazione predefinita. Non disperare se questo dovesse essere il caso del tuo sistema. Segui semplici istruzioni sul sempre ottimo Arch Wiki per risolvere il problema, tenendo presente che la memoria allocata a tmpfs non è disponibile per altri scopi. In altre parole, un sistema con un gigantesco tmpfs con file di grandi dimensioni può esaurire la memoria e andare in crash. Un altro consiglio:quando modifichi il file /etc/fstab, assicurati di terminarlo con una nuova riga, altrimenti il tuo sistema non si avvierà. (Indovina come lo so.)
/proc e /sys
Oltre a /tmp, i VFS con cui la maggior parte degli utenti Linux hanno più familiarità sono /proc e /sys. (/dev si basa sulla memoria condivisa e non ha operazioni_file). Perché due gusti? Diamo un'occhiata più nel dettaglio.
Il procfs offre un'istantanea dello stato istantaneo del kernel e dei processi che controlla per lo spazio utente. In /proc, il kernel pubblica informazioni sui servizi che fornisce, come gli interrupt, la memoria virtuale e lo scheduler. Inoltre, /proc/sys è dove le impostazioni configurabili tramite il comando sysctl sono accessibili allo spazio utente. Lo stato e le statistiche sui singoli processi sono riportati nelle directory /proc/
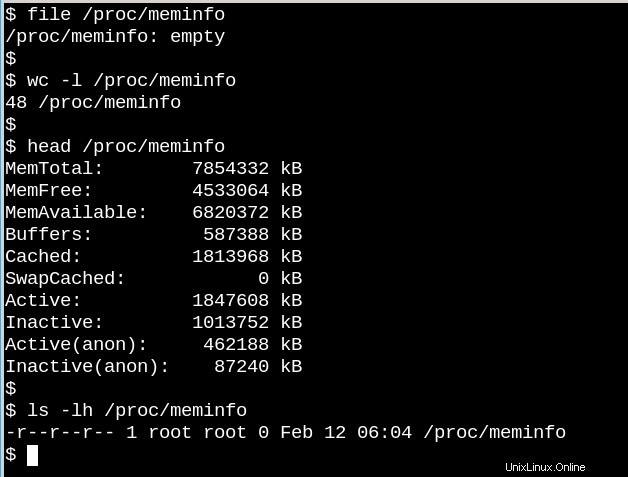
Il comportamento dei file /proc illustra quanto VFS possa essere diverso dai filesystem su disco. Da un lato, /proc/meminfo contiene le informazioni presentate dal comando free . D'altra parte, è anche vuoto! Come può essere? La situazione ricorda un famoso articolo scritto nel 1985 dal fisico della Cornell University N. David Mermin intitolato "C'è la luna quando nessuno guarda? La realtà e la teoria dei quanti". La verità è che il kernel raccoglie statistiche sulla memoria quando un processo le richiede da /proc, e in realtà c'è niente nei file in /proc quando nessuno sta guardando. Come ha detto Mermin, "È una dottrina quantistica fondamentale che una misurazione, in generale, non riveli un valore preesistente della proprietà misurata". (La risposta alla domanda sulla luna è lasciata per esercizio.)

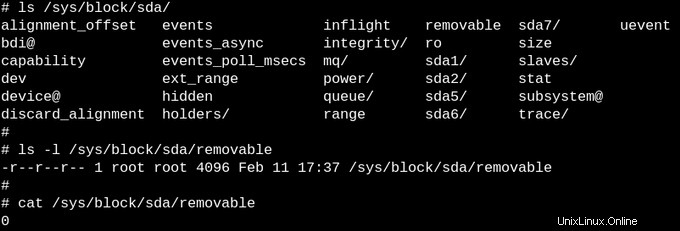
L'apparente vacuità di procfs ha senso, poiché le informazioni disponibili sono dinamiche. La situazione con sysfs è diversa. Confrontiamo quanti file di almeno un byte di dimensione ci sono in /proc rispetto a /sys.
Procfs ne ha proprio uno, ovvero la configurazione del kernel esportata, che è un'eccezione poiché deve essere generata solo una volta per avvio. D'altra parte, /sys ha molti file più grandi, la maggior parte dei quali comprende una pagina di memoria. Tipicamente, i file sysfs contengono esattamente un numero o una stringa, in contrasto con le tabelle di informazioni prodotte dalla lettura di file come /proc/meminfo.
Lo scopo di sysfs è quello di esporre le proprietà leggibili e scrivibili di ciò che il kernel chiama "kobjects" allo spazio utente. L'unico scopo dei kobject è il conteggio dei riferimenti:quando l'ultimo riferimento a un kobject viene cancellato, il sistema rivendicherà le risorse ad esso associate. Tuttavia, /sys costituisce la maggior parte della famosa "ABI stabile nello spazio utente" del kernel che nessuno può mai, in nessuna circostanza, "interrompere". Ciò non significa che i file in sysfs siano statici, il che sarebbe contrario al conteggio dei riferimenti di oggetti volatili.
L'ABI stabile del kernel limita invece ciò che può appaiono in /sys, non ciò che è effettivamente presente in un dato istante. L'elenco dei permessi sui file in sysfs dà un'idea di come i parametri configurabili e sintonizzabili di dispositivi, moduli, filesystem, ecc. possono essere impostati o letti. La logica spinge a concludere che procfs fa anche parte dell'ABI stabile del kernel, sebbene la documentazione del kernel non lo dichiari in modo così esplicito.
Snooping su VFS con strumenti eBPF e bcc
Il modo più semplice per imparare come il kernel gestisce i file sysfs è guardarlo in azione e il modo più semplice per guardarlo su ARM64 o x86_64 è usare eBPF. eBPF (Extended Berkeley Packet Filter) consiste in una macchina virtuale in esecuzione all'interno del kernel che gli utenti privilegiati possono interrogare dalla riga di comando. Il sorgente del kernel dice al lettore cosa il kernel può fare; l'esecuzione degli strumenti eBPF su un sistema avviato mostra invece ciò che il kernel fa effettivamente .
Fortunatamente, iniziare con eBPF è abbastanza facile tramite gli strumenti bcc, che sono disponibili come pacchetti dalle principali distribuzioni Linux e sono stati ampiamente documentati da Brendan Gregg. Gli strumenti bcc sono script Python con piccoli frammenti di C incorporati, il che significa che chiunque abbia dimestichezza con entrambi i linguaggi può modificarli facilmente. A questo punto, ci sono 80 script Python in bcc/tools, il che rende molto probabile che un amministratore di sistema o uno sviluppatore ne trovi uno esistente pertinente alle sue esigenze.
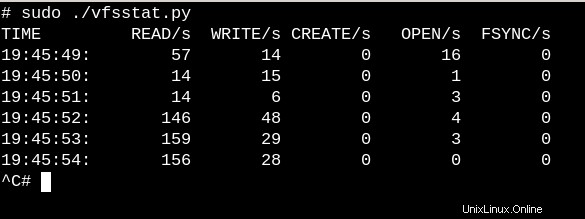
Per avere un'idea molto semplice del lavoro svolto dai VFS su un sistema in esecuzione, prova il semplice vfscount o vfsstat, che mostra che decine di chiamate a vfs_open() e ai suoi amici si verificano ogni secondo.
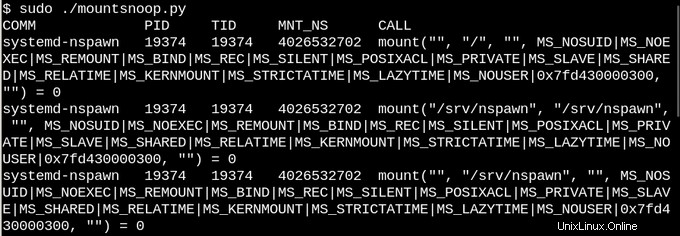
Per un esempio meno banale, vediamo cosa succede in sysfs quando viene inserita una chiavetta USB su un sistema in esecuzione.
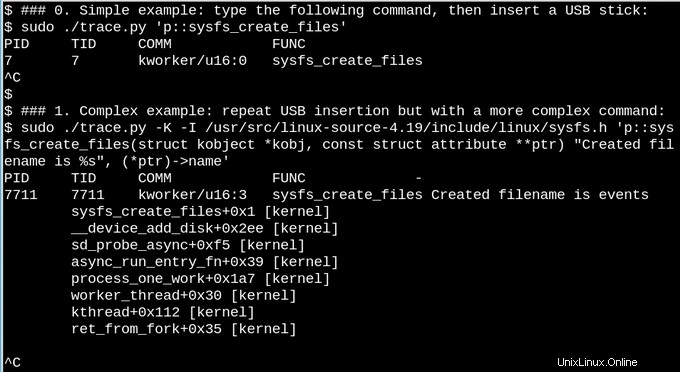
Nel primo semplice esempio sopra, lo script trace.py bcc tools stampa un messaggio ogni volta che viene eseguito il comando sysfs_create_files(). Vediamo che sysfs_create_files() è stato avviato da un thread kworker in risposta all'inserimento della chiavetta USB, ma quale file è stato creato? Il secondo esempio illustra tutta la potenza di eBPF. Qui trace.py sta stampando il backtrace del kernel (opzione -K) più il nome del file creato da sysfs_create_files(). Lo snippet all'interno delle virgolette singole è del codice sorgente C, inclusa una stringa di formato facilmente riconoscibile, che lo script Python fornito induce un compilatore just-in-time LLVM a compilare ed eseguire all'interno di una macchina virtuale interna al kernel. La firma della funzione sysfs_create_files() completa deve essere riprodotta nel secondo comando in modo che la stringa di formato possa fare riferimento a uno dei parametri. Se si commettono errori in questo frammento di codice C, si ottengono errori riconoscibili del compilatore C. Ad esempio, se -I parametro viene omesso, il risultato è "Impossibile compilare il testo BPF". Gli sviluppatori che hanno dimestichezza con C o Python troveranno gli strumenti bcc facili da estendere e modificare.
Quando viene inserita la chiavetta USB, viene visualizzato il backtrace del kernel che mostra che PID 7711 è un thread kworker che ha creato un file chiamato "events" in sysfs. Una chiamata corrispondente con sysfs_remove_files() mostra che la rimozione della chiavetta USB comporta la rimozione del file degli eventi, in linea con l'idea del conteggio dei riferimenti. Guardare sysfs_create_link() con eBPF durante l'inserimento della chiavetta USB (non mostrato) rivela che vengono creati non meno di 48 collegamenti simbolici.
Qual è lo scopo del file degli eventi comunque? L'uso di cscope per trovare la funzione __device_add_disk() rivela che chiama disk_add_events() e che "media_change" o "eject_request" possono essere scritti nel file degli eventi. Qui, il livello di blocco del kernel informa lo spazio utente dell'aspetto e della scomparsa del "disco". Considera la rapidità con cui questo metodo di indagine sul funzionamento dell'inserimento della chiavetta USB è informativo rispetto al tentativo di capire il processo esclusivamente dalla fonte.
I filesystem root di sola lettura rendono possibili i dispositivi embedded
Sicuramente, nessuno spegne un server o un sistema desktop estraendo la spina di alimentazione. Come mai? Perché i filesystem montati sui dispositivi di archiviazione fisici potrebbero avere scritture in sospeso e le strutture di dati che registrano il loro stato potrebbero non essere sincronizzate con ciò che è scritto sullo spazio di archiviazione. Quando ciò accade, i proprietari del sistema dovranno attendere al prossimo avvio che lo strumento di ripristino del file system fsck venga eseguito e, nel peggiore dei casi, perderanno effettivamente dei dati.
Tuttavia, gli appassionati avranno sentito dire che molti dispositivi IoT e embedded come router, termostati e automobili ora eseguono Linux. Molti di questi dispositivi mancano quasi del tutto di un'interfaccia utente e non c'è modo di "riavviarli" in modo pulito. Prendi in considerazione l'avviamento di emergenza di un'auto con una batteria scarica in cui l'alimentazione all'unità principale che esegue Linux va su e giù ripetutamente. Com'è possibile che il sistema si avvii senza un lungo fsck quando il motore finalmente inizia a funzionare? La risposta è che i dispositivi embedded si basano su un file system radice di sola lettura (ro-rootfs in breve).
Un ro-rootfs offre molti vantaggi meno evidenti dell'incorruttibilità. Uno è che il malware non può scrivere su /usr o /lib se nessun processo Linux può scrivere lì. Un altro è che un filesystem in gran parte immutabile è fondamentale per il supporto sul campo di dispositivi remoti, poiché il personale di supporto possiede sistemi locali nominalmente identici a quelli sul campo. Forse il vantaggio più importante (ma anche più sottile) è che ro-rootfs costringe gli sviluppatori a decidere durante la fase di progettazione di un progetto quali oggetti di sistema saranno immutabili. Gestire i ro-rootf può essere spesso scomodo o addirittura doloroso, come spesso lo sono le variabili const nei linguaggi di programmazione, ma i vantaggi ripagano facilmente il sovraccarico aggiuntivo.
La creazione di un rootfs di sola lettura richiede uno sforzo aggiuntivo per gli sviluppatori embedded, ed è qui che entra in gioco VFS. Linux ha bisogno che i file in /var siano scrivibili e, inoltre, molte applicazioni popolari eseguite dai sistemi embedded cercheranno di creare la configurazione dot-file in $HOME. Una soluzione per i file di configurazione nella directory home è in genere quella di pregenerarli e integrarli in rootfs. Per /var, un approccio consiste nel montarlo su una partizione scrivibile separata mentre / stesso è montato in sola lettura. L'uso di cavalcature vincolate o sovrapposte è un'altra alternativa popolare.
Lega e sovrapponi i supporti e il loro utilizzo da parte dei contenitori
Esecuzione di cavalcatura uomo è il posto migliore per conoscere i mount di bind e overlay, che danno agli sviluppatori embedded e agli amministratori di sistema il potere di creare un filesystem in un percorso e poi fornirlo alle applicazioni in un secondo. Per i sistemi embedded, l'implicazione è che è possibile archiviare i file in /var su un dispositivo flash non scrivibile ma sovrapporre o montare un percorso in un tmpfs sul percorso /var all'avvio in modo che le applicazioni possano eseguire lo scarabocchio lì a loro piacimento delizia. Alla successiva accensione, le modifiche in /var scompariranno. I mount overlay forniscono un'unione tra tmpfs e il filesystem sottostante e consentono modifiche apparenti a un file esistente in un ro-rootfs, mentre i mount bind possono far apparire nuove directory tmpfs vuote come scrivibili nei percorsi ro-rootfs. Sebbene overlayfs sia un tipo di filesystem appropriato, i mount bind sono implementati dalla funzione dello spazio dei nomi VFS.
Sulla base della descrizione dei mount overlay e bind, nessuno sarà sorpreso dal fatto che i container Linux ne facciano un uso massiccio. Spiiamo cosa succede quando utilizziamo systemd-nspawn per avviare un container eseguendo lo strumento mountsnoop di bcc:

E vediamo cosa è successo:
Qui, systemd-nspawn fornisce i file selezionati nei procfs e sysfs dell'host al contenitore nei percorsi nei suoi rootfs. Oltre al flag MS_BIND che imposta il montaggio del binding, alcuni degli altri flag richiamati dalla chiamata di sistema "mount" determinano la relazione tra le modifiche nello spazio dei nomi host e nel contenitore. Ad esempio, il bind-mount può propagare le modifiche in /proc e /sys al contenitore o nasconderle, a seconda dell'invocazione.
Riepilogo
Comprendere gli interni di Linux può sembrare un compito impossibile, poiché il kernel stesso contiene una quantità enorme di codice, lasciando da parte le applicazioni dello spazio utente di Linux e l'interfaccia di chiamata di sistema nelle librerie C come glibc. Un modo per fare progressi è leggere il codice sorgente di un sottosistema del kernel con un'enfasi sulla comprensione delle chiamate di sistema e delle intestazioni rivolte allo spazio utente oltre alle principali interfacce interne del kernel, esemplificate qui dalla tabella file_operations. Le operazioni sui file sono ciò che fa funzionare effettivamente "tutto è un file", quindi ottenere un controllo su di esse è particolarmente soddisfacente. I file sorgente C del kernel nella directory fs/ di livello superiore costituiscono la sua implementazione di filesystem virtuali, che sono il livello shim che consente un'interoperabilità ampia e relativamente semplice di filesystem e dispositivi di archiviazione popolari. Bind e overlay mount tramite gli spazi dei nomi Linux sono la magia VFS che rende possibili contenitori e filesystem root di sola lettura. In combinazione con uno studio del codice sorgente, la funzione del kernel eBPF e la sua interfaccia bcc rendono il sondaggio del kernel più semplice che mai.
Grazie mille ad Akkana Peck e Michael Eager per commenti e correzioni.
Alison Chaiken presenterà i filesystem virtuali:perché ne abbiamo bisogno e come funzionano alla 17a edizione annuale della Southern California Linux Expo (SCaLE 17x) dal 7 al 10 marzo a Pasadena, in California.