Gli amministratori di sistema hanno molti strumenti per visualizzare e gestire i processi in esecuzione. Per me, questi erano principalmente i migliori , in cima e htop . Alcuni anni fa, ho trovato Sguardi, uno strumento che mostra informazioni che nessuno dei miei altri preferiti fa. Tutti questi strumenti monitorano l'utilizzo della CPU e della memoria e la maggior parte di essi elenca le informazioni sui processi in esecuzione (almeno). Tuttavia, Glances monitora anche l'I/O del filesystem, l'I/O di rete e le letture dei sensori che possono visualizzare la temperatura della CPU e di altro hardware, nonché la velocità della ventola e l'utilizzo del disco in base al dispositivo hardware e al volume logico.
Sguardi
Ho menzionato Sguardi nel mio articolo 4 strumenti open source per il monitoraggio del sistema Linux , ma lo approfondirò più a fondo in questo articolo. Se hai letto il mio precedente articolo, alcune di queste informazioni potrebbero esserti familiari, ma dovresti anche trovare alcune novità qui.
Glances è multipiattaforma perché è scritto in Python. Può essere installato su Windows e altri host con le versioni correnti di Python installate. La maggior parte delle distribuzioni Linux (Fedora nel mio caso) hanno Sguardi nei loro repository. In caso contrario, o se stai utilizzando un sistema operativo diverso (come Windows) o desideri semplicemente scaricarlo direttamente dal sorgente, puoi trovare le istruzioni per scaricarlo e installarlo nel repository GitHub di GitHub.
Suggerisco di eseguire Sguardi su una macchina di prova mentre provi i comandi in questo articolo. Se non hai un host fisico disponibile per il test, puoi esplorare Sguardi su una macchina virtuale (VM), ma non vedrai la sezione dei sensori hardware; dopotutto, una macchina virtuale non ha hardware reale.
Per avviare Glance su un host Linux, apri una sessione di terminale e immetti il comando sguardi .
Sguardi ha tre sezioni principali:Riepilogo, Processo e Avvisi, oltre a una barra laterale. Li esplorerò e altri dettagli per l'utilizzo di Sguardi ora.
Sezione di riepilogo
Nelle prime righe, la sezione Riepilogo di Sguardi contiene molte delle stesse informazioni che troverai nelle sezioni di riepilogo di altri monitor. Se hai abbastanza spazio orizzontale nel tuo terminale, Sguardi può mostrare l'utilizzo della CPU sia con un grafico a barre che con un indicatore numerico; altrimenti mostrerà solo il numero.
Mi piace la sezione Riepilogo di Glances meglio di quella di altri monitor (come top ); Penso che fornisca le informazioni giuste in un formato facilmente comprensibile.
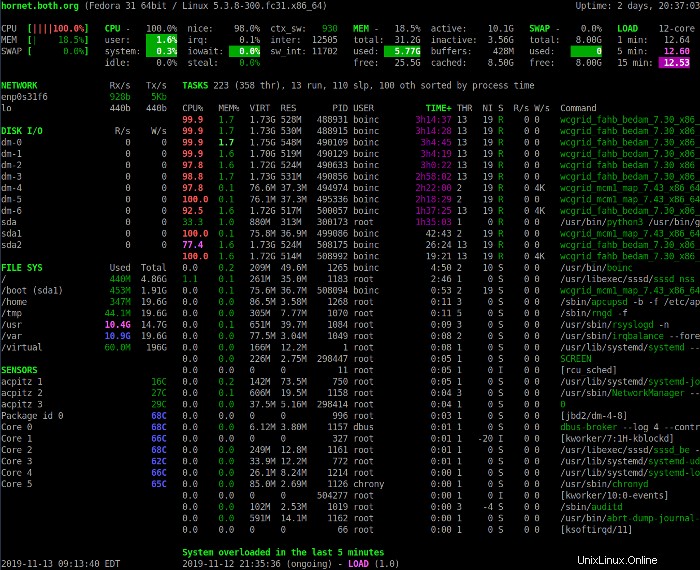
La sezione Riepilogo sopra fornisce una panoramica dello stato del sistema. La prima riga mostra il nome host, la distribuzione Linux, la versione del kernel e il tempo di attività del sistema.
Le quattro righe successive mostrano le statistiche relative a CPU, utilizzo della memoria, scambio e caricamento. La colonna di sinistra mostra le percentuali di CPU, memoria e spazio di scambio in uso. Mostra anche le statistiche combinate per tutte le CPU presenti nel sistema.
Premi il 1 tasto per alternare tra la visualizzazione dell'utilizzo consolidato della CPU e la visualizzazione delle singole CPU. L'immagine seguente mostra il display Sguardi con le statistiche della singola CPU.
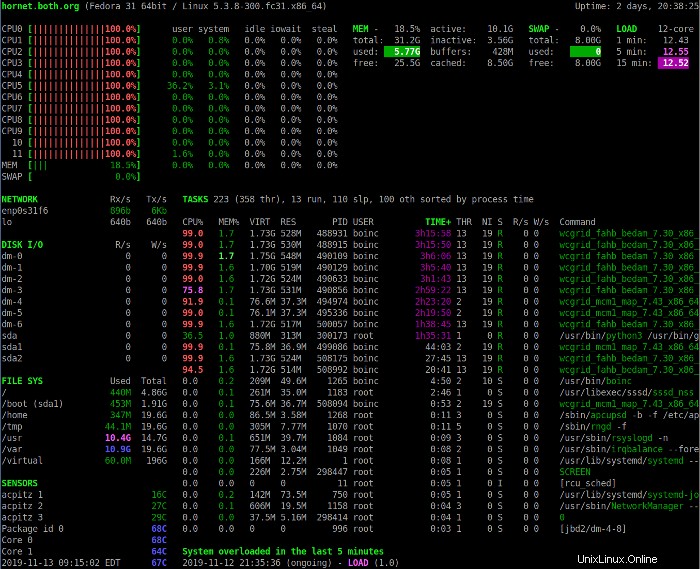
Questa visualizzazione include alcune statistiche aggiuntive sulla CPU. In entrambe le modalità di visualizzazione, le descrizioni dei campi di utilizzo della CPU possono aiutare a interpretare i dati visualizzati nella sezione CPU. Si noti che le CPU sono numerate a partire da 0 (Zero).
| CPU | Questo è l'utilizzo attuale della CPU come percentuale del totale disponibile. |
| utente | Queste sono le applicazioni e altri programmi in esecuzione nello spazio utente, ovvero non nel kernel. |
| sistema | Queste sono funzioni a livello di kernel. Non include il tempo CPU impiegato dal kernel stesso, solo le chiamate di sistema del kernel. |
| inattivo | Questo è il tempo di inattività, ovvero il tempo non utilizzato da alcun processo in esecuzione. |
| bello | Questo è il tempo utilizzato dai processi che funzionano a un livello positivo e gradevole. |
| irq | Queste sono le richieste di interrupt che richiedono tempo di CPU. |
| io attendo | Questi sono i cicli della CPU che vengono spesi in attesa che si verifichi l'I/O:si tratta di tempo CPU sprecato. |
| rubare | La percentuale di cicli della CPU che una CPU virtuale attende per una CPU reale mentre l'hypervisor esegue la manutenzione di un altro processore virtuale. |
| ctx-sw | Questo è il numero di cambi di contesto al secondo; rappresenta il numero di volte al secondo che la CPU passa dall'esecuzione di un processo all'altro. |
| inter | Questo è il numero di interrupt hardware al secondo. Un interrupt hardware si verifica quando un dispositivo hardware, come un disco rigido, comunica a una CPU che ha completato un trasferimento di dati o che una scheda di interfaccia di rete è pronta per accettare più dati. |
| sw_int | Gli interrupt software comunicano alla CPU che un'attività richiesta è stata completata o che il software è pronto per qualcosa. Questi tendono ad essere più comuni nel software a livello di kernel. |
A proposito di bei numeri
I numeri piacevoli sono il meccanismo utilizzato dagli amministratori per influenzare la priorità di un processo. Non è possibile modificare direttamente la priorità di un processo, ma cambiare il numero piacevole può modificare i risultati dell'algoritmo di impostazione della priorità dello scheduler del kernel. I numeri piacevoli vanno da -20 a +19, dove i numeri più alti sono più piacevoli. Il numero nice predefinito è 0 e la priorità predefinita è 20. L'impostazione del numero nice superiore a zero aumenta leggermente il numero di priorità, rendendo così il processo più piacevole e quindi meno avido di cicli della CPU. L'impostazione del numero piacevole su un numero più negativo comporta un numero di priorità inferiore che rende il processo meno piacevole. I numeri di Nizza possono essere modificati utilizzando il comando renice o da top, atop e htop.
Memoria
La parte Memoria della sezione Riepilogo contiene statistiche sull'utilizzo della memoria.
| MEM | Questo mostra l'utilizzo della memoria come percentuale della quantità totale disponibile. |
| totale | Questa è la quantità totale di memoria RAM installata nell'host, meno l'importo assegnato alla scheda video. |
| usato | Questa è la quantità totale di memoria utilizzata dal sistema e dai programmi applicativi, ma non include cache o buffer. |
| gratuito | Questa è la quantità di memoria libera. |
| attivo | Questa è la quantità di memoria utilizzata attivamente:la memoria inattiva è soggetta a scambio su disco in caso di necessità. |
| non attivo | Questa è la memoria che è in uso ma a cui non si accede da un po' di tempo. |
| buffer | Questa è la memoria utilizzata per lo spazio nel buffer; viene solitamente utilizzato dalle comunicazioni e dagli I/O come il networking. I dati vengono ricevuti e archiviati fino a quando il software non può recuperarli per l'uso o possono essere inviati a un dispositivo di archiviazione o trasmessi alla rete. |
| in cache | Questa è la memoria utilizzata per archiviare i dati per il trasferimento su disco fino a quando non può essere utilizzata da un programma o memorizzata su disco. |
La sezione Swap è autoesplicativa se capisci qualcosa sullo spazio di swap e su come funziona. Questo mostra quanto spazio di scambio totale è disponibile, quanto viene utilizzato e quanto rimane.
La parte Carica della sezione Riepilogo mostra le medie di carico di uno, cinque e 15 minuti.
Puoi utilizzare i tasti numerici 1 , 3 , 4 e 5 per modificare la visualizzazione dei dati in questa sezione. Il 2 il tasto attiva e disattiva la barra laterale sinistra.
Ulteriori informazioni sulle medie di carico
Le medie di carico sono comunemente fraintese, anche se sono un criterio chiave per misurare l'utilizzo della CPU. Ma cosa significa veramente quando dico che la media del carico di uno (o cinque o 10) minuto è 4,04, per esempio? Il carico medio può essere considerato una misura della domanda per la CPU; è un numero che rappresenta il numero medio di istruzioni in attesa di tempo della CPU, quindi è una vera misura delle prestazioni della CPU.
Altro sugli amministratori di sistema
- Abilita blog Sysadmin
- The Automated Enterprise:una guida alla gestione dell'IT con l'automazione
- eBook:Ansible Automation per SysAdmins
- Racconti dal campo:una guida per l'amministratore di sistema all'automazione IT
- eBook:una guida a Kubernetes per SRE e amministratori di sistema
- Ultimi articoli sull'amministratore di sistema
Ad esempio, una CPU di sistema a processore singolo completamente utilizzata avrebbe una media di carico di 1. Ciò significa che la CPU sta tenendo esattamente il passo con la domanda; in altre parole, ha un utilizzo perfetto. Una media di carico inferiore a 1 significa che la CPU è sottoutilizzata e una media di carico maggiore di 1 significa che la CPU è sovrautilizzata e che c'è una domanda repressa e insoddisfatta. Ad esempio, una media di carico di 1,5 in un sistema a CPU singola indica che un terzo delle istruzioni della CPU deve attendere per essere eseguito fino al completamento della precedente.
Questo vale anche per più processori. Se un sistema a quattro CPU ha una media di carico di 4, ha un utilizzo perfetto. Se ha una media di carico di 3,24, ad esempio, tre dei suoi processori sono completamente utilizzati e uno viene utilizzato a circa il 24%. Nell'esempio sopra, un sistema con quattro CPU ha una media di carico di un minuto di 4,04, il che significa che non c'è capacità rimanente tra le quattro CPU e alcune istruzioni sono costrette ad attendere. Un sistema a quattro CPU perfettamente utilizzato mostrerebbe una media di carico di 4,00, il che significa che il sistema è completamente carico ma non sovraccarico.
La condizione ottimale della media del carico è che la media del carico sia uguale al numero totale di CPU in un sistema. Ciò significherebbe che ogni CPU è completamente utilizzata e nessuna istruzione deve essere costretta ad attendere. Ma la realtà è disordinata e le condizioni ottimali sono raramente soddisfatte. Se un host fosse in esecuzione al 100% di utilizzo, ciò non consentirebbe picchi nei requisiti di carico della CPU.
Le medie di carico a lungo termine indicano le tendenze di utilizzo complessive.
Diario Linux ha pubblicato un eccellente articolo sulle medie di carico, la teoria, la matematica dietro di esse e come interpretarle, nel numero del 1° dicembre 2006. Sfortunatamente, Linux Journal ha cessato la pubblicazione e i suoi archivi non sono più disponibili direttamente, quindi il collegamento è a un archivio di terze parti.
Trovare problemi di CPU
Uno dei motivi per utilizzare uno strumento come Sguardi è trovare processi che occupano troppo tempo della CPU. Apri una nuova sessione del terminale (diversa da quella su cui è in esecuzione Glances) e inserisci e avvia il seguente programma Bash che monopolizza la CPU.
X=0;while [ 1 ];do echo $X;X=$((X+1));doneQuesto programma è un hog della CPU e utilizzerà ogni ciclo della CPU disponibile. Consenti che venga eseguito mentre finisci questo articolo e fai esperimenti con Sguardi. Ti darà un'idea di come appare un programma che monopolizza i cicli della CPU. Assicurati di osservare gli effetti sulle medie di carico nel tempo, nonché il tempo cumulativo nel TIME+ colonna per questo processo.
Sezione di processo
La sezione Processo mostra le informazioni standard su ogni processo in esecuzione. A seconda della modalità di visualizzazione e delle dimensioni dello schermo del terminale, verranno visualizzate diverse colonne di informazioni per i processi in esecuzione. La modalità predefinita con un terminale sufficientemente ampio mostra le colonne elencate di seguito. Le colonne visualizzate cambiano automaticamente se lo schermo del terminale viene ridimensionato. Le seguenti colonne sono generalmente visualizzate per ogni processo da sinistra a destra.
| CPU% | Questa è la quantità di tempo della CPU come percentuale di un singolo core. Ad esempio, il 98% rappresenta il 98% dei cicli CPU disponibili per un singolo core. Più processi possono mostrare fino al 100% di utilizzo della CPU. |
| MEM% | Questa è la quantità di memoria RAM utilizzata dal processo come percentuale della memoria virtuale totale nell'host. |
| VIRT | Questa è la quantità di memoria virtuale utilizzata dal processo in un formato leggibile dall'uomo, ad esempio 12M per 12 megabyte. |
| RES | Questo si riferisce alla quantità di memoria fisica (residente) utilizzata dal processo. Ancora una volta, questo è in formato leggibile, con un indicatore di K , M o G , per specificare kilobyte, megabyte o gigabyte. |
| PID | Ogni processo ha un numero di identificazione, chiamato PID. Questo numero può essere utilizzato nei comandi, come renice e uccidi , per gestire il processo. Ricorda che l'uccisione l'utilità può inviare segnali a un altro processo oltre al segnale "kill". |
| UTENTE | Questo è il nome dell'utente che possiede il processo. |
| TEMPO+ | Questo indica la quantità cumulativa di tempo CPU accumulato dal processo dall'inizio. |
| THR | Questo è il numero totale di thread attualmente in esecuzione per questo processo. |
| NI | Questo è il bel numero del processo. |
| S | Questo è lo stato attuale; può essere (R )unning, (S )dormire, (io )dle, T o t quando il processo viene interrotto durante una traccia di debug oppure (Z )Ombi. Uno zombi è un processo che è stato ucciso ma non è morto completamente, quindi continua a consumare alcune risorse di sistema, come la RAM. |
| R/s e W/s | Queste sono le letture e le scritture del disco al secondo. |
| Comando | Questo è il comando utilizzato per avviare il processo. |
Sguardi di solito determina automaticamente la colonna di ordinamento predefinita. I processi possono essere ordinati automaticamente (a ) o dalla CPU (c ), memoria (m ), nome (p ), utente (u ), tasso di I/O (i ) o l'ora (t ). I processi vengono ordinati automaticamente in base alla risorsa più utilizzata. Nelle immagini sopra, il TIME+ la colonna è evidenziata.
Sezione avvisi
Sguardi mostra anche avvisi e avvisi critici, inclusi l'ora e la durata dell'evento, nella parte inferiore dello schermo. Questo può essere utile quando stai tentando di diagnosticare problemi e non puoi fissare lo schermo per ore alla volta. Questi registri degli avvisi possono essere attivati o disattivati con la l (L minuscola), gli avvisi possono essere cancellati con il tasto w chiave, mentre gli avvisi e gli avvisi possono essere cancellati con x .
Barra laterale
Sguardi ha una barra laterale molto bella sulla sinistra che mostra informazioni che non sono disponibili in top o htop . Mentre in cima visualizza alcuni di questi dati, Sguardi è l'unico monitor che visualizza i dati sui sensori. Dopotutto, a volte è bello vedere le temperature all'interno del tuo computer.
I singoli moduli, disco, filesystem, rete e sensori possono essere attivati e disattivati utilizzando il d , f , n e s chiavi, rispettivamente. L'intera barra laterale può essere attivata utilizzando 2 . Le statistiche Docker possono essere visualizzate nella barra laterale con D .
Tieni presente che i sensori hardware non vengono visualizzati quando Glances è in esecuzione su una macchina virtuale.
Ricevere aiuto
Puoi ricevere assistenza premendo la h chiave; chiudere la pagina della guida premendo h ancora. La pagina della Guida è piuttosto concisa, ma mostra le opzioni interattive disponibili e come attivarle e disattivarle. La pagina man contiene spiegazioni concise delle opzioni che possono essere utilizzate all'avvio di Glances.
Puoi premere q o Esc per uscire da Sguardi.
Configurazione
Glance non richiede un file di configurazione per funzionare correttamente. Se scegli di averne uno, l'istanza a livello di sistema del file di configurazione si troverà in /etc/glances/glances.conf . I singoli utenti possono avere un'istanza locale in ~/.config/glances/glances.conf , che sovrascriverà la configurazione globale. Lo scopo principale di questi file di configurazione è impostare le soglie per gli avvisi e gli avvisi critici. Puoi anche specificare se alcuni moduli vengono visualizzati per impostazione predefinita o meno.
Il file /usr/local/share/doc/glances/README.rst contiene ulteriori informazioni utili, inclusi moduli Python opzionali che puoi installare per supportare alcune funzionalità opzionali di Glances.
Opzioni della riga di comando
Sguardi fornisce opzioni della riga di comando che consentono l'avvio in modalità di visualizzazione specifiche. Ad esempio, il comando sguardi -2 avvia il programma con la barra laterale sinistra disabilitata.
Telecomando e altro
Avviandolo in modalità server, puoi utilizzare Sguardi per monitorare gli host remoti:
[root@testvm1 ~]# glances -sPuoi quindi connetterti al server dal client con:
[root@testvm2 ~]# glances -c @testvm1Sguardi può mostrare un elenco di server Sguardi insieme a un riepilogo della loro attività. Ha anche un'interfaccia web in modo da poter monitorare i server Glance remoti da un browser. Le versioni recenti di Sguardi possono anche visualizzare le statistiche Docker.
Ci sono anche moduli collegabili per Sguardi che forniscono dati di misurazione non disponibili nel programma di base.
Limitazioni
Sebbene Glance possa monitorare molti aspetti di un host, non può gestire i processi. Non può cambiare il bel numero di un processo né ucciderne uno, come top e htop potere. Sguardi non è uno strumento interattivo. È usato rigorosamente per il monitoraggio. Strumenti esterni come uccidi e renice può essere utilizzato per gestire i processi.
Sguardi può mostrare solo i processi che occupano la maggior parte della risorsa specificata, come il tempo della CPU, nello spazio disponibile. Se c'è spazio per elencare solo 10 processi, questo è tutto ciò che sarai in grado di vedere. Sguardi non fornisce opzioni di scorrimento o di ordinamento inverso che ti consentirebbero di vedere altri processi X diversi dai principali.
L'impatto della misurazione
L'effetto osservatore è una teoria fisica che afferma che "la semplice osservazione di una situazione o di un fenomeno cambia necessariamente quel fenomeno". Questo vale anche quando si misurano le prestazioni del sistema Linux.
Il semplice utilizzo di uno strumento di monitoraggio altera l'utilizzo delle risorse da parte del sistema, inclusa la memoria e il tempo della CPU. Il top utility e la maggior parte degli altri monitor utilizzano forse dal 2% al 3% del tempo di CPU di un sistema. L'utilità Sguardi ha un impatto molto maggiore rispetto alle altre; di solito utilizza tra il 10% e il 20% del tempo della CPU e ho visto che utilizza fino al 40% di una CPU in un sistema molto grande e attivo con 32 CPU. È molto, quindi considera il suo impatto quando pensi di utilizzare Glance come monitor.
La mia opinione personale è che questo è un piccolo prezzo da pagare quando hai bisogno delle capacità di Sguardi.
Riepilogo
Nonostante la mancanza di capacità interattive, come la capacità di rinnovare o uccidi processi e il suo elevato carico della CPU, trovo che Glance sia uno strumento molto utile. La documentazione completa di Glances è disponibile su Internet e la pagina man di Glances contiene opzioni di avvio e informazioni sui comandi interattivi.
Parti di questo articolo sono basate sul nuovo libro di David Both, Using and Administering Linux:Volume 2 – Zero to SysAdmin:Advanced Topics.