Ecco i passaggi per installare Apache Kafka su Rocky Linux o server AlmaLinux 8, ovviamente, usando il terminale di comando.
Apache Kafka è un software open source che consente l'archiviazione e l'elaborazione di flussi di dati tramite una piattaforma di streaming distribuita. In parole semplici, Apache Kafka è una piattaforma di streaming di eventi che funge da sistema di messaggistica tra mittente e destinatario con elevata tolleranza ai guasti e capacità di scalabilità perché si basa su un'architettura distribuita ottimizzata per lo stesso.
Ebbene, questo sistema è stato originariamente sviluppato da LinkedIn come coda di messaggi, tuttavia, essendo un progetto di Apache Software Foundation, è open source e una potente piattaforma di streaming con una varietà di funzioni. Offre interfacce per scrivere dati su cluster Kafka, leggere dati o importare ed esportare dati da e verso sistemi di terze parti. Grazie alla bassa latenza e all'elevata velocità effettiva, è in grado di elaborare facilmente i flussi in tempo reale.
Le interfacce consentono inoltre agli utenti di caricare flussi di dati da sistemi di terze parti o di esportarli su questi sistemi. Ciò rende Apache Kafka adatto a grandi quantità di dati e applicazioni nell'ambiente dei big data.
Può essere utilizzato per un'ampia gamma di applicazioni come il monitoraggio dell'attività del sito Web in tempo reale, il monitoraggio di applicazioni distribuite, l'aggregazione di file di registro da diverse origini, la sincronizzazione di dati in sistemi distribuiti, l'addestramento di modelli in tempo reale aiuta nell'apprendimento automatico, e altro ancora...
Apache Kafka offre queste quattro interfacce principali (API – Application Programming Interfaces). Scopri di più su ciascuna API nella pagina della documentazione ufficiale:
- API di amministrazione
- API del produttore
- API del consumatore
- API Stream
- Collega API
Di cosa hai bisogno per seguire questo tutorial:
- Rocky o AlmaLinux 8 o qualsiasi altro server basato su RHEL, se possibile, pulirne uno.
- Un utente con accesso sudo.
Passaggi per installare Apache Kafka su Rocky Linux 8
La guida fornita è applicabile a tutti i sistemi Linux basati su RHEL 8, inclusi CentOS 8 e Oracle Linux 8, per installare Kafka, se necessario.
1. Sistema di aggiornamento
Bene, prima di procedere ulteriormente, esegui il comando di aggiornamento del sistema per assicurarti che tutti i pacchetti installati siano aggiornati. Per questo esegui il comando seguente, questo aggiornerà anche la cache del repository.
aggiornamento sudo dnf
2. Installa Java
Apache Kafka ha bisogno di Java per funzionare, quindi prima dobbiamo installarlo nel nostro ambiente locale e deve essere uguale o maggiore di Java 8. Bene, non abbiamo bisogno di aggiungere un terzo repository perché il pacchetto per ottenere JAVA è già lì sul repository di base del sistema, quindi, usiamo il comando dato.
Per Java 11
sudo dnf install java-11-openjdk
Beh, per l'ultima versione come 16 usa i comandi seguenti:
sudo dnf install epel-release
sudo dnf install java-latest-openjdk
3. Scarica l'ultimo Apache Kafka su Rocky Linux 8 o Almalinux
Apache Kafka è disponibile come file tarball sul sito ufficiale. Quindi, vai al sito Web ufficiale e scarica l'ultima versione. Puoi anche copiare qualsiasi link mirror e utilizzare il wget comando da scaricare utilizzando la riga di comando, come abbiamo fatto qui:
sudo dnf install wget nano
wget https://dlcdn.apache.org/kafka/3.0.0/kafka_2.13-3.0.0.tgz
Estrai il file scaricato
tar -xf kafka_*tgz
Per vedere il file:
ls
Spostalo in /usr/local/ solo per assicurarci di non eliminare accidentalmente la cartella Kafka.
sudo mv kafka_2.13-3.0.0/ /usr/local/kafka
4. Crea un servizio di sistema per Zookeeper e Kafka
Sebbene solo per il test sia possibile eseguire direttamente lo script di servizio Zookeeper e Kafka, manualmente, tuttavia, per il server di produzione dobbiamo eseguirlo in background. Quindi, crea unità systemd per entrambi gli script.
Crea file di sistema Zookeeper
Come da sito ufficiale in futuro, Kafka non avrà bisogno di Zookeeper, tuttavia, mentre scriviamo questo articolo ne abbiamo bisogno. Quindi, crea prima un file di servizio per Zookeeper.
sudo nano /etc/systemd/system/zookeeper.service
Copia e incolla le righe sotto indicate:
[Unità]Description=Apache Zookeeper serverDocumentation=http://zookeeper.apache.orgRequires=network.target remote-fs.targetAfter=network.target remote-fs.target[Service]Type=simpleExecStart=/usr/bin /bash /usr/local/kafka/bin/zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.propertiesExecStop=/usr/bin/bash /usr/local/kafka/bin/zookeeper-server- stop.shRestart=on-abnormal[Install]WantedBy=multi-user.target
Salva e chiudi il file premendo Ctr+O , premi Invio tasto, quindi esci utilizzando Ctrl+X .
Ora, crea il file systemd Kafka
sudo nano /etc/systemd/system/kafka.service
Incolla le seguenti righe. Nota – Modificare Java_Home , nel caso in cui tu stia utilizzando un'altra versione. Per trovarlo puoi usare il comando – sudo find /usr/ -name *jdk
[Unità]Description=Apache Kafka ServerDocumentation=http://kafka.apache.org/documentation.htmlRequires=zookeeper.service[Service]Type=simpleEnvironment="JAVA_HOME=/usr/lib/jvm/jre-11- openjdk"ExecStart=/usr/bin/bash /usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.propertiesExecStop=/usr/bin/bash /usr/local/ kafka/bin/kafka-server-stop.sh[Install]WantedBy=multi-user.target
Salva il file con Ctrl+O premi Invio tasto, quindi usa CTRL+X per uscire lo stesso.
Ricarica il demone
Per riflettere le modifiche sopra apportate nel sistema e utilizzare i file di servizio, ricaricare il demone di sistema una volta.
sudo systemctl daemon-reload
5. Avvia Zookeeper e Kafka Server su Rocky Linux
Ora avviamo e abilitiamo entrambi i servizi server per assicurarci che si attivino anche dopo il riavvio del sistema.
sudo systemctl start zookeepersudo systemctl start kafka
sudo systemctl abilita zookeepersudo systemctl abilita kafka
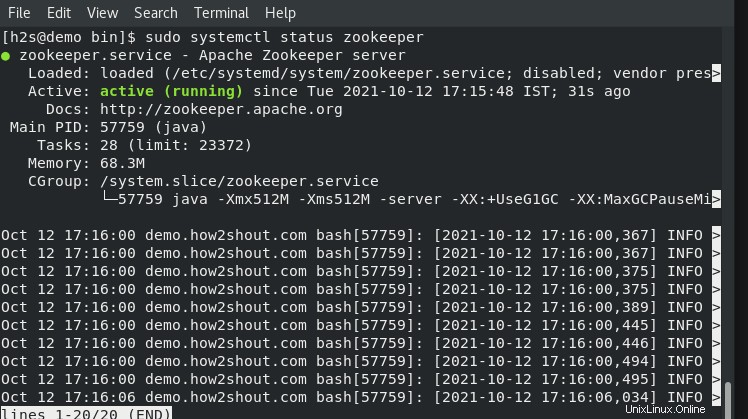
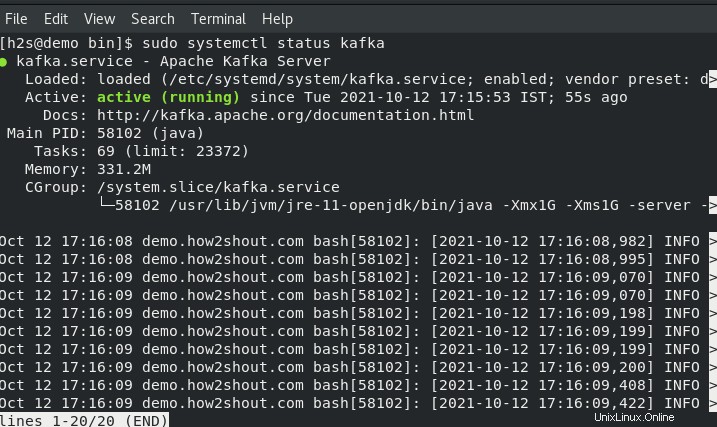
Controlla lo stato dei servizi:
sudo systemctl status zookeeper
 sudo systemctl status kafka
sudo systemctl status kafka
6. Crea argomenti di prova su Kafka – Rocky o AlmaLinux
Kafka ci consente di leggere, scrivere, archiviare ed elaborare eventi sulle varie macchine, tuttavia, per archiviare questi eventi abbiamo bisogno di un posto o di una cartella e quello chiamato "Argomenti “. Quindi sul tuo terminale del server crea almeno un argomento usando il seguente comando, usando lo stesso in seguito puoi creare tutti gli argomenti che vuoi.
Diciamo che il nome del nostro primo argomento è:testeven . Quindi per creare la stessa corsa:
Vai alla tua directory Kafka.
cd /usr/local/kafka/
E usa lo script Argomenti:
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic testvent

Dopo aver creato tutti gli argomenti che vuoi, per elencarli tutti possiamo usare il seguente comando:
bin/kafka-topics.sh --list --bootstrap-server localhost:9092
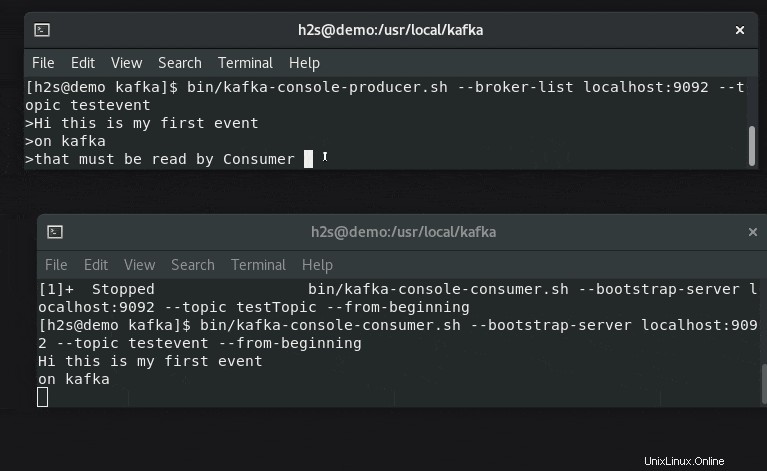
7. Scrivi un evento utilizzando Kafka Producer e leggi con il consumatore
Kafka offre due API:Produttore e Consumatore , per entrambi offre un client a riga di comando. Il produttore è responsabile della creazione di eventi e il consumatore li utilizza per visualizzare o leggere i dati generati dal produttore.
Apri due schede o sessioni di terminale per comprendere il generatore di eventi e la configurazione del lettore in tempo reale.
#Su un primo terminale:
Per testare creiamo degli eventi usando lo script Producer:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic testevento
Digita del testo che desideri trasmettere in streaming e visualizzare sul lato consumer.
#Sull'altro terminale
Corri, il comando riportato di seguito insieme al nome dell'argomento per controllare i messaggi o i dati degli eventi generati in tempo reale:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testevento --dall'inizio