Scrapy è un software open source utilizzato per estrarre dati dai siti Web. Il framework Scrapy è sviluppato in Python ed esegue il lavoro di scansione in modo rapido, semplice ed estensibile. Abbiamo creato una macchina virtuale (VM) in una scatola virtuale e su di essa è installato Ubuntu 14.04 LTS.
Installa Scrapy
Scrapy dipende da Python, dalle librerie di sviluppo e dal software pip. L'ultima versione di Python è preinstallata su Ubuntu. Quindi dobbiamo installare le librerie per sviluppatori pip e python prima dell'installazione di Scrapy.
Pip è il sostituto di easy_install per l'indicizzatore di pacchetti Python. Viene utilizzato per l'installazione e la gestione dei pacchetti Python.
Per installare il pacchetto pip, esegui:
$ sudo apt-get install python-pip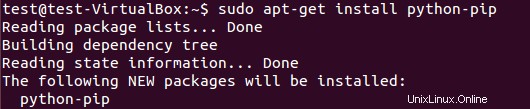
Dobbiamo installare le librerie di sviluppo Python usando il comando seguente. Se questo pacchetto non è installato, l'installazione di scrapy framework genera un errore sul file di intestazione python.h.
$ sudo apt-get install python-dev
Il framework Scrapy può essere installato sia dal pacchetto deb che dal codice sorgente. Tuttavia, abbiamo installato il pacchetto deb utilizzando pip (gestore di pacchetti Python).
$ sudo pip install scrapy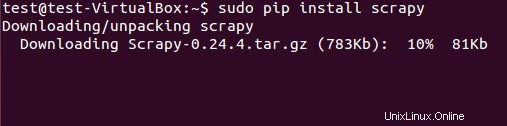
Un'installazione scadente richiede del tempo.

Estrazione dei dati utilizzando il framework Scrapy
(Tutorial di base)
Utilizzeremo Scrapy per l'estrazione dei nomi dei negozi (che forniscono le carte) degli articoli dal sito Web fatwallet.com. Prima di tutto, abbiamo creato un nuovo progetto scrapy “store_name” usando il seguente comando.
$ sudo scrapy startproject store_name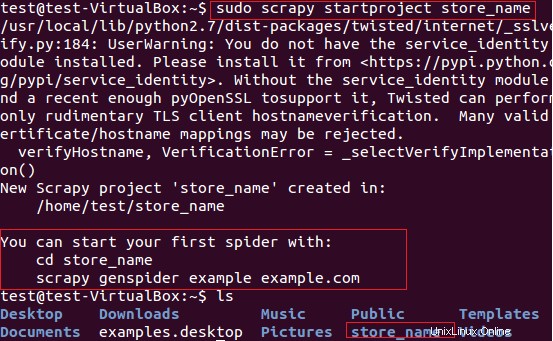
Il comando precedente crea una directory con il titolo "store_name" nel percorso corrente. Questa directory principale del progetto contiene file/cartelle mostrati nella seguente Figura 6.
$ sudo ls –lR store_name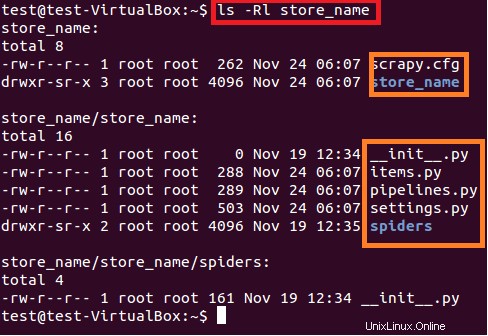
Di seguito viene fornita una breve descrizione di ciascun file/cartella:
- scrapy.cfg è il file di configurazione del progetto
- store_name/ è un'altra directory all'interno della directory principale. Questa directory contiene il codice Python del progetto.
- store_name/items.py contiene quegli elementi che verranno estratti dallo spider.
- store_name/pipelines.py è il file delle pipeline.
- L'impostazione del progetto store_name è nel file store_name/settings.py.
- e la directory store_name/spiders/, contiene spider per la scansione
Poiché siamo interessati ad estrarre i nomi dei negozi delle Carte dal sito fatwallet.com, abbiamo aggiornato il contenuto del file come mostrato di seguito.
import scrapy
class StoreNameItem(scrapy.Item):
name = scrapy.Field() # extract the names of Cards storeDopo questo, dobbiamo scrivere il nuovo spider nella directory store_name/spiders/ del progetto. Spider è una classe Python che consiste nei seguenti attributi obbligatori:
Nome del ragno (name )
- URL iniziale di spider per la scansione (start_urls)
E metodo di analisi che consiste in espressioni regolari per l'estrazione degli elementi desiderati dalla risposta della pagina. Il metodo di analisi è la parte importante del ragno.
Abbiamo creato lo spider "store_name.py" nella directory store_name/spiders/ e aggiunto il seguente codice python per l'estrazione del nome del negozio dal sito fatwallet.com. L'output dello spider è scritto nel file (StoreName.txt ).
from scrapy.selector import Selector
from scrapy.spider import BaseSpider
from scrapy.http import Request
from scrapy.http import FormRequest
import re
class StoreNameItem(BaseSpider):
name = "storename"
allowed_domains = ["fatwallet.com"]
start_urls = ["http://fatwallet.com/cash-back-shopping/"]
def parse(self,response):
output = open('StoreName.txt','w')
resp = Selector(response)
tags = resp.xpath('//tr[@class="storeListRow"]|\
//tr[@class="storeListRow even"]|\
//tr[@class="storeListRow even last"]|\
//tr[@class="storeListRow last"]').extract()
for i in tags:
i = i.encode('utf-8', 'ignore').strip()
store_name = ''
if re.search(r"class=\"storeListStoreName\">.*?<",i,re.I|re.S):
store_name = re.search(r"class=\"storeListStoreName\">.*?<",i,re.I|re.S).group()
store_name = re.search(r">.*?<",store_name,re.I|re.S).group()
store_name = re.sub(r'>',"",re.sub(r'<',"",store_name,re.I))
store_name = re.sub(r'&',"&",re.sub(r'&',"&",store_name,re.I))
#print store_name
output.write(store_name+""+"\n")
NOTA:lo scopo di questo tutorial è solo la comprensione di Scrapy Framework