
Parte 1:Introduzione alla terminologia
Prefazione
Non è una situazione insolita, per i primi utilizzatori di concetti e tecnologie di nuova introduzione, essere totalmente confusi quando questi possono cambiare radicalmente le modalità di sviluppo e fornitura dei servizi. Soprattutto quando tutti parlano di qualcosa come Docker e di quanto sia fantastico e rivoluzionario. Questa confusione si verifica quando proviamo le cose all'inizio e ci precipitiamo direttamente a testarle senza afferrare l'intero concetto e il background di questa tecnologia appena introdotta.
Questo è il motivo per cui potresti aver abbandonato l'intera tendenza dei container Linux, o perché hai letto alcuni articoli controversi di affermatori e oppositori. In questa prima parte, di una serie di articoli, faremo del nostro meglio per chiarire le cose e mettere tutto nella giusta prospettiva per qualsiasi sviluppatore, amministratore di sistema, ingegnere di Q/A o anche appassionato che ha solo bisogno della giusta ispirazione per utilizzare i container Linux e risolvere i loro problemi IT speciali.
Inizieremo dall'inizio, con alcune necessarie descrizioni degli eventi storici e dei concetti e poi mostrerò come possiamo iniziare a lavorare con i container Docker. In questo modo potrai capire "cosa ha portato alla creazione dei contenitori", "quali sono gli elementi costitutivi" e "come funzionano".
Come sono nati i container
Per molti anni i server sono stati utilizzati così come sono, con un'unica configurazione hardware, contenente un unico sistema operativo (OS in breve), per fornire migliaia di siti Web e alcune prime versioni di software aziendali sulla stessa macchina.
Per ottenere il ridimensionamento necessario, le aziende dovevano acquistare nuovo hardware e pianificare attentamente i passaggi per eventuali nuove implementazioni. In questo periodo di tempo, l'automazione era agli albori e la maggior parte delle configurazioni veniva eseguita a mano.
Virtualizzazione
Poi è arrivata la virtualizzazione che ha permesso alle persone di utilizzare lo stesso server hardware in modo da poter generare più server virtuali per scopi diversi e venderli singolarmente. Ciò non solo ha ridotto enormemente i costi di proprietà dell'hardware del server, ma ha anche fornito i mezzi per automatizzare e gestire facilmente centinaia di istanze del server.
La virtualizzazione, in realtà, consiste nell'assemblare componenti hardware come CPU, RAM, dischi, schede di rete ecc. che vengono emulati da un software speciale. È come costruire un PC, con i suoi componenti principali sopra menzionati, all'interno di un sistema operativo e assemblarli per funzionare come se fosse un vero PC. In questo modo il PC virtuale diventa un "ospite" all'interno di un PC vero e proprio che con il suo sistema operativo viene chiamato host.
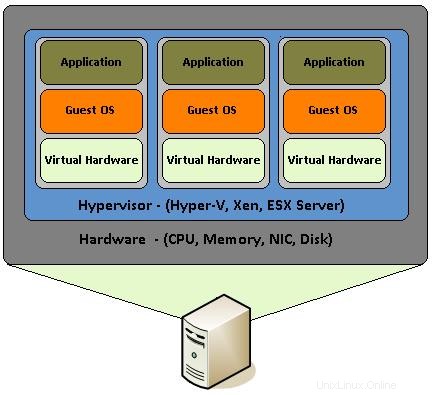
Sebbene la virtualizzazione hardware sia stata introdotta circa 10 anni fa, ha ottenuto il suo uso diffuso su vari tipi di server da parte di sviluppatori e amministratori di sistema, utilizzando la funzionalità KVM (Kernel-based Virtual Machine) integrata nel kernel Linux dal 2007. Con "VT" di Intel -x" e le estensioni "AMD-V" di AMD che aiutano a creare un numero qualsiasi di sistemi operativi virtualizzati (limitati solo dalle risorse hardware), ogni sviluppatore potrebbe creare a buon mercato più macchine virtuali (VM in breve) con sistemi operativi, anche con versioni diverse di loro. In questo modo sono in grado di testare le loro applicazioni senza la necessità di acquistare un nuovo rig o più di essi, a seconda del sistema operativo di cui hanno bisogno.
Uno dei grandi vantaggi della virtualizzazione è la possibilità di creare snapshot. Uno snapshot è lo stato di una macchina virtuale in un momento esatto. Puoi pensarlo come uno stato "congelato" della macchina virtuale in un determinato momento. In questo modo uno sviluppatore o un amministratore di sistema può creare una macchina virtuale, installare un particolare sistema operativo e gli strumenti di cui ha bisogno e creare un'istantanea dell'intera cosa. Quindi può iniziare a testare, configurare o eseguire qualsiasi attività che deve svolgere e quindi tornare all'istantanea precedente all'istante, in qualsiasi momento.
Anche le Macchine Virtuali possono essere migrate da una macchina host all'altra e continuare il loro stato di lavoro senza alcuna configurazione speciale. Questo perché l'intera macchina virtuale è in realtà dei file enormi che di solito sono chiamati immagini. Puoi pensare alle immagini, come il tuo file ISO preferito delle distribuzioni Linux. Poiché il file ISO contiene tutti i componenti essenziali per eseguire effettivamente un intero sistema operativo da un USB/DVD live, allo stesso modo un'immagine di macchina virtuale contiene il sistema operativo e i componenti hardware virtuali.
Tutto quanto sopra, ha creato un intero settore di società di hosting di Virtual Private Server (VPS) in cui i clienti potevano lanciare immediatamente immagini preconfigurate di server per qualsiasi scopo. Questi provider VPS di solito dispongono di 10 o 20 snapshot di VM su un server host principale che vengono clonati più volte su richiesta del cliente per fornire loro i server virtuali di cui hanno bisogno
Contenitori
Come puoi immaginare, una macchina virtuale è un intero sistema operativo in esecuzione all'interno di un sistema operativo host. I sistemi operativi guest, sebbene isolati, condividono e utilizzano le risorse hardware della macchina host. A volte, esistono più sistemi operativi guest che eseguono lo stesso intero stack di un sistema operativo specifico.
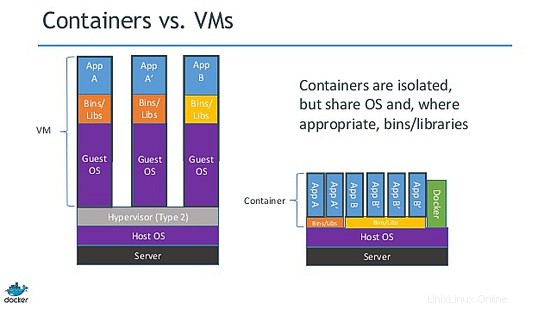
Questa situazione ha creato un'opportunità per gli sviluppatori e gli hacker del kernel Linux di elaborare un'idea chiamata virtualizzazione dei processi leggeri. Quindi, invece di utilizzare un intero sistema operativo, potrebbero ridurre i componenti "non necessari" del sistema operativo virtuale per crearne una versione minima. Ciò ha portato alla creazione di LXC (Linux Containers).
Prima di approfondire, dovremmo menzionare che la virtualizzazione dei processi leggeri non è una novità. Solaris ha Zones, BSD ha jail e ci sono altre tecnologie simili come OpenVZ. Il problema è che cambiano spesso nome o scopo quando lo stesso concetto di base viene utilizzato su altri progetti. È vero che non tutti sono uguali, ma i principi fondamentali sono più o meno gli stessi. Tutti vogliono isolare, distribuire e creare un modo usa e getta per fornire servizi software senza il fastidio di ricostruire tutto e ogni volta dal basso verso l'alto.
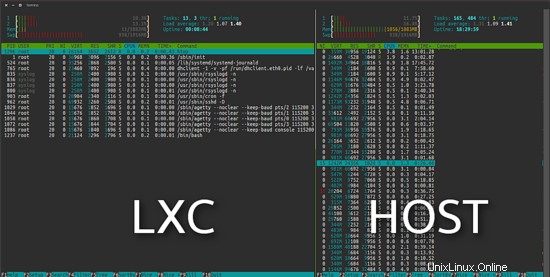
Il progetto LXC differisce dalle suddette macchine virtuali in quanto è un ambiente di virtualizzazione a livello di sistema operativo e non un ambiente di virtualizzazione hardware. Entrambi fanno la stessa cosa, ma LXC fornisce la virtualizzazione a livello di sistema operativo attraverso un ambiente virtuale che ha il proprio processo e spazio di rete, invece di creare una macchina virtuale a tutti gli effetti. Di conseguenza, un sistema operativo virtuale LXC richiede risorse minime e si avvia in pochi secondi.
Come puoi vedere nell'immagine seguente, Ubuntu virtuale LXC a sinistra utilizza 11 MB in un'installazione predefinita.
Docker
Come al solito, le cose non si sono fermate semplicemente rimuovendo le parti non necessarie di un sistema operativo. Varie tecnologie hanno preso vita spingendo ulteriormente i confini della virtualizzazione dei processi leggeri. Nel 2013, gli sviluppatori di dotCloud (una società che in seguito ha cambiato nome in Docker Inc.) hanno introdotto Docker.
Docker è un motore open source il cui obiettivo principale è automatizzare la distribuzione di applicazioni all'interno di contenitori software e l'automazione della virtualizzazione a livello di sistema operativo su Linux. Un contenitore Docker, a differenza di una macchina virtuale e lxc, non richiede o include un sistema operativo separato. Al contrario, si basa sulla funzionalità del kernel Linux e utilizza l'isolamento delle risorse.
I contenitori Docker vengono creati da immagini Docker (ricorda gli snapshot). Puoi immaginare un contenitore docker come lo stato live di un'applicazione Web in esecuzione da un file ISO. Ma questa volta l'iso, che nel nostro esempio è l'equivalente dell'immagine docker, contiene solo l'applicazione e le sue dipendenze.
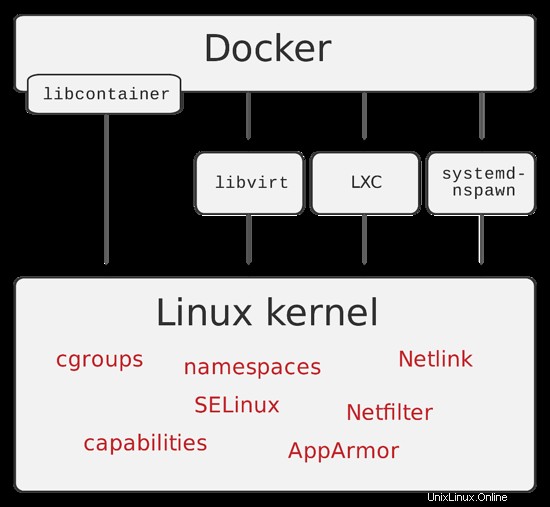
Una grande caratteristica di Docker, di cui parleremo nella seconda parte, è il file Docker. Un file docker è la ricetta che contiene tutti i passaggi necessari per creare un'immagine docker. Ci sono letteralmente tonnellate di file docker "pronti per l'uso" che puoi personalizzare e usali così come sono.
Riepilogo
Come puoi immaginare, lo scopo del passaggio da server a tutti gli effetti, alla virtualizzazione del sistema operativo e quindi ai container è quello di rimuovere l'onere di creare, distribuire e mantenere un intero sistema operativo quando ciò di cui hanno solo bisogno è solo il livello dell'applicazione.
Con questa premessa, abbiamo cercato di presentarvi alcuni eventi fondamentali che ci hanno portato alla realizzazione dei container Docker. Ho anche cercato di semplificare alcuni dei suoi concetti, in modo che tu possa capire le differenze tra le varie tecnologie di virtualizzazione e dove sono applicabili.
La seconda parte che verrà pubblicata la prossima settimana, mostrerà esattamente come possiamo installare e utilizzare i container Docker in modo pratico, quindi resta sintonizzato.