Introduzione
Imparare a creare un DataFrame Spark è uno dei primi passaggi pratici nell'ambiente Spark. Spark DataFrames consente di visualizzare la struttura dei dati e altre funzioni di manipolazione dei dati. Esistono metodi diversi a seconda dell'origine dati e del formato di archiviazione dei dati dei file.
Questo articolo spiega come creare manualmente un DataFrame Spark in Python utilizzando PySpark.

Prerequisiti
- Python 3 installato e configurato.
- PySpark installato e configurato.
- Un ambiente di sviluppo Python pronto per testare gli esempi di codice (stiamo utilizzando Jupyter Notebook).
Metodi per creare Spark DataFrame
Esistono tre modi per creare manualmente un DataFrame in Spark:
1. Crea un elenco e analizzalo come DataFrame utilizzando toDataFrame() metodo da SparkSession .
2. Converti un RDD in un DataFrame utilizzando toDF() metodo.
3. Importa un file in una SparkSession direttamente come DataFrame.
Gli esempi utilizzano dati di esempio e un RDD per la dimostrazione, sebbene i principi generali si applichino a strutture di dati simili.
Crea DataFrame da un elenco di dati
Per creare un DataFrame Spark da un elenco di dati:
1. Genera un elenco di dizionari di esempio con i dati dei giocattoli:
data = [{"Category": 'A', "ID": 1, "Value": 121.44, "Truth": True},
{"Category": 'B', "ID": 2, "Value": 300.01, "Truth": False},
{"Category": 'C', "ID": 3, "Value": 10.99, "Truth": None},
{"Category": 'E', "ID": 4, "Value": 33.87, "Truth": True}
]
2. Importa e crea una SparkSession :
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
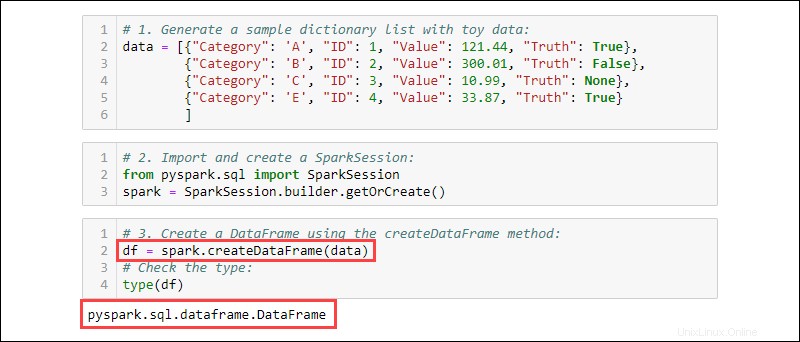
3. Crea un DataFrame utilizzando createDataFrame metodo. Controlla il tipo di dati per confermare che la variabile è un DataFrame:
df = spark.createDataFrame(data)
type(df)
Crea DataFrame da RDD
Un evento tipico quando si lavora in Spark consiste nel creare un DataFrame da un RDD esistente. Crea un RDD di esempio e poi convertilo in un DataFrame.
1. Crea un elenco di dizionari contenente dati sui giocattoli:
data = [{"Category": 'A', "ID": 1, "Value": 121.44, "Truth": True},
{"Category": 'B', "ID": 2, "Value": 300.01, "Truth": False},
{"Category": 'C', "ID": 3, "Value": 10.99, "Truth": None},
{"Category": 'E', "ID": 4, "Value": 33.87, "Truth": True}
]
2. Importa e crea uno SparkContext :
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName("projectName").setMaster("local[*]")
sc = SparkContext.getOrCreate(conf)
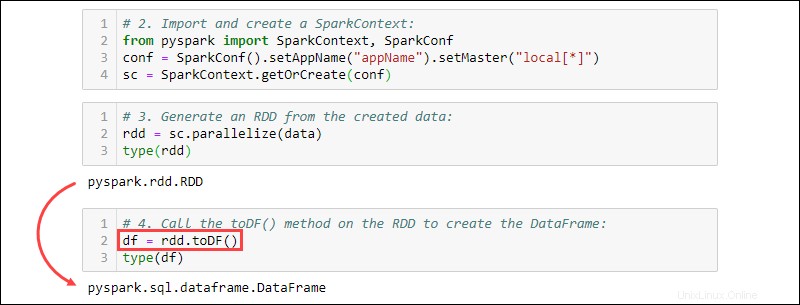
3. Genera un RDD dai dati creati. Controlla il tipo per confermare che l'oggetto è un RDD:
rdd = sc.parallelize(data)
type(rdd)
4. Chiama il toDF() metodo sull'RDD per creare il DataFrame. Testare il tipo di oggetto per confermare:
df = rdd.toDF()
type(df)
Crea DataFrame da origini dati
Spark può gestire un'ampia gamma di origini dati esterne per costruire DataFrame. La sintassi generale per leggere da un file è:
spark.read.format('<data source>').load('<file path/file name>')Il nome e il percorso dell'origine dati sono entrambi tipi String. Anche origini dati specifiche hanno una sintassi alternativa per importare file come DataFrame.
Creazione da file CSV
Crea un DataFrame Spark leggendo direttamente da un file CSV:
df = spark.read.csv('<file name>.csv')Leggi più file CSV in un DataFrame fornendo un elenco di percorsi:
df = spark.read.csv(['<file name 1>.csv', '<file name 2>.csv', '<file name 3>.csv'])
Per impostazione predefinita, Spark aggiunge un'intestazione per ogni colonna. Se un file CSV ha un'intestazione che desideri includere, aggiungi l'option metodo durante l'importazione:
df = spark.read.csv('<file name>.csv').option('header', 'true')
Le singole opzioni si accumulano chiamandole una dopo l'altra. In alternativa, utilizza le options metodo quando sono necessarie più opzioni durante l'importazione:
df = spark.read.csv('<file name>.csv').options(header = True)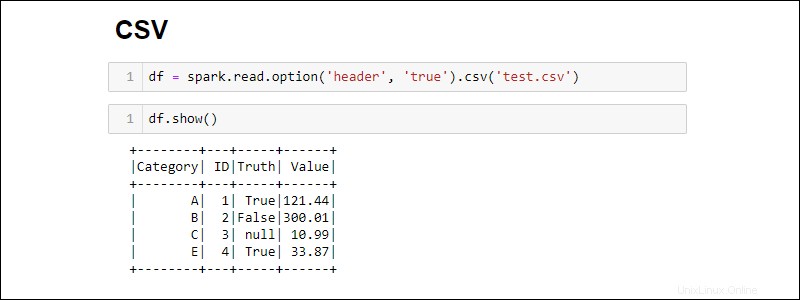
Nota che la sintassi è diversa durante l'utilizzo option rispetto a options .
Creazione da file TXT
Crea un DataFrame da un file di testo con:
df = spark.read.text('<file name>.txt')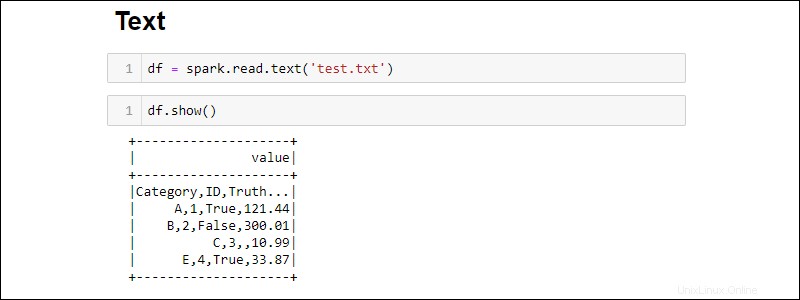
Il csv è un altro modo per leggere da un txt tipo di file in un DataFrame. Ad esempio:
df = spark.read.option('header', 'true').csv('<file name>.txt')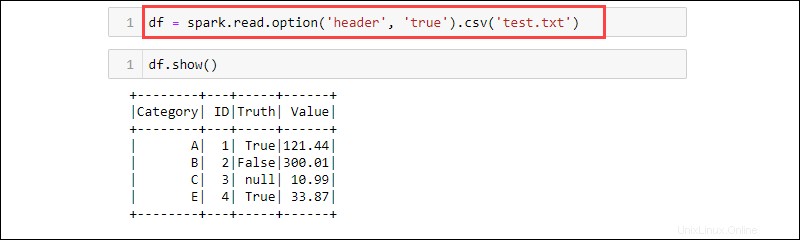
CSV è un formato testuale in cui il delimitatore è una virgola (,) e la funzione è quindi in grado di leggere i dati da un file di testo.
Creazione da file JSON
Crea un DataFrame Spark da un file JSON eseguendo:
df = spark.read.json('<file name>.json')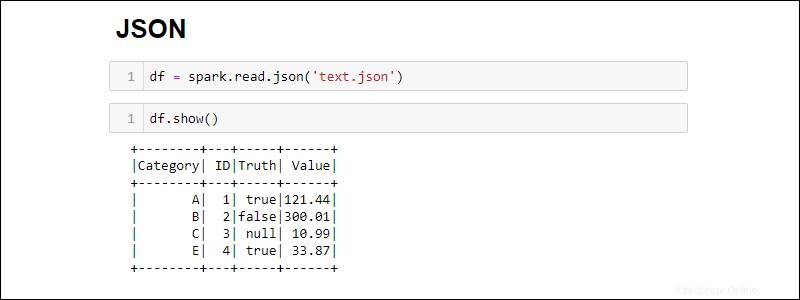
Creazione da un file XML
La compatibilità dei file XML non è disponibile per impostazione predefinita. Installa le dipendenze per creare un DataFrame da un'origine XML.
1. Scarica la dipendenza Spark XML. Salva il .jar nella cartella Spark jar.
2. Leggi un file XML in un DataFrame eseguendo:
df = spark.read\
.format('com.databricks.spark.xml')\
.option('rowTag', 'row')\
.load('test.xml')
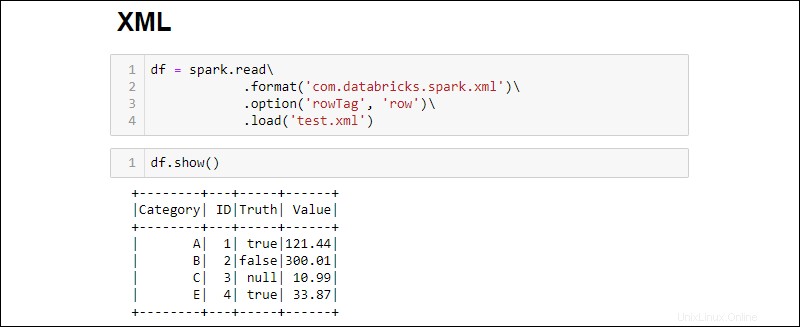
Modifica il rowTag opzione se ogni riga nel tuo XML il file è etichettato in modo diverso.
Crea DataFrame dal database RDBMS
La lettura da un RDBMS richiede un connettore del driver. L'esempio illustra come connettere ed estrarre dati da un database MySQL. Passaggi simili funzionano per altri tipi di database.
1. Scarica il connettore del driver Java MySQL. Salva il .jar nella cartella Spark jar.
2. Eseguire il server SQL e stabilire una connessione.
3. Stabilisci una connessione e recupera l'intera tabella del database MySQL in un DataFrame:
df = spark.read\
.format('jdbc')\
.option('url', 'jdbc:mysql://localhost:3306/db')\
.option('driver', 'com.mysql.jdbc.Driver')\
.option('dbtable','new_table')\
.option('user','root')\
.load()
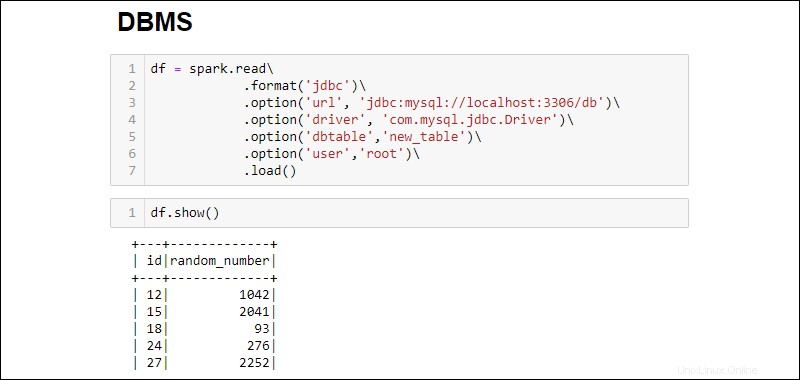
Le opzioni aggiunte sono le seguenti:
- L'URL è
localhost:3306se il server viene eseguito in locale. Altrimenti, recupera l'URL del tuo server di database. - Nome database estende l'URL per accedere a un database specifico sul server. Ad esempio, se un database è denominato
dbe il server viene eseguito localmente, l'URL completo per stabilire una connessione èjdbc:mysql://localhost:3306/db. - Nome tabella assicura che l'intera tabella del database venga inserita in DataFrame. Usa
.option('query', '<query>')invece di.option('dbtable', '<table name>')per eseguire una query specifica invece di selezionare un'intera tabella. - Utilizza il nome utente e password del database per stabilire la connessione. Quando si esegue senza una password, omettere l'opzione specificata.