Introduzione
Spark Streaming è un'aggiunta all'API Spark per lo streaming live e l'elaborazione di dati su larga scala. Invece di gestire enormi quantità di dati grezzi non strutturati e ripulirli, Spark Streaming esegue l'elaborazione e la raccolta dei dati quasi in tempo reale.
Questo articolo spiega cos'è Spark Streaming, come funziona e fornisce un esempio di caso d'uso dei dati in streaming.

Prerequisiti
- Apache Spark installato e configurato (segui le nostre guide:Come installare Spark su Ubuntu, Come installare Spark su Windows 10)
- Ambiente configurato per Spark (useremo Pyspark nei notebook Jupyter).
- Stream di dati (useremo l'API di Twitter).
- Librerie Python tweepy , json e presa per lo streaming di dati da Twitter (usa pip per installarli).
Cos'è Spark Streaming?
Spark Streaming è una libreria Spark per l'elaborazione di flussi di dati quasi continui. L'astrazione principale è un Stream Discretizzato creato dall'API Spark DStream per dividere i dati in batch. L'API DStream è basata su Spark RDD (Resilient Distributed Datasets), che consente una perfetta integrazione con altri moduli Apache Spark come Spark SQL e MLlib.
Le aziende sfruttano la potenza di Spark Streaming in molti casi d'uso diversi:
- ETL in diretta streaming – Pulizia e combinazione dei dati prima della memorizzazione.
- Apprendimento continuo – Aggiornamento costante dei modelli di machine learning con nuove informazioni.
- Attivazione su eventi – Rilevamento delle anomalie in tempo reale.
- Arricchimento dei dati – Aggiunta di informazioni statistiche ai dati prima della memorizzazione.
- Sessioni complesse dal vivo – Raggruppamento dell'attività dell'utente per l'analisi.
L'approccio in streaming consente un'analisi del comportamento dei clienti più rapida, sistemi di raccomandazione più rapidi e rilevamento delle frodi in tempo reale. Per gli ingegneri, qualsiasi tipo di anomalia del sensore proveniente dai dispositivi IoT è visibile durante la raccolta dei dati.
Aspetti di Spark Streaming
Spark Streaming supporta nativamente carichi di lavoro batch e streaming, il che offre miglioramenti interessanti ai feed di dati. Questo aspetto unico soddisfa i seguenti requisiti dei moderni sistemi di streaming di dati:
- Bilanciamento dinamico del carico. Poiché i dati si dividono in micro-batch, il collo di bottiglia non è più un problema. L'architettura tradizionale elabora un record alla volta e, una volta che arriva una partizione ad alta intensità di calcolo, blocca tutti gli altri dati su quel nodo. Con Spark Streaming, le attività si dividono tra i lavoratori, alcune elaborano attività più lunghe e altre elaborano attività più brevi a seconda delle risorse disponibili.
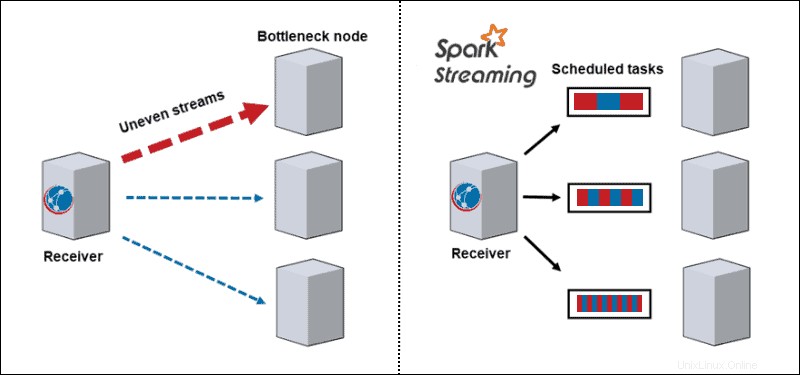
- Recupero fallito. Le attività non riuscite su un nodo vengono discretizzate e distribuite tra gli altri lavoratori. Mentre i nodi di lavoro eseguono il calcolo, il ritardatario ha il tempo di riprendersi.
- Analisi interattiva. I DStream sono una serie di RDD. I batch di dati in streaming archiviati nella memoria di lavoro eseguono query in modo interattivo.
- Analisi avanzata. Gli RDD generati da DStream vengono convertiti in DataFrame che eseguono query con SQL e si estendono a librerie, come MLlib, per creare modelli di machine learning e applicarli allo streaming di dati.
- Rendimento dello streaming migliorato. Lo streaming in batch aumenta le prestazioni di throughput, sfruttando latenze di poche centinaia di millisecondi.
Vantaggi e svantaggi dello streaming Spark
Ogni tecnologia, incluso Spark Streaming, presenta vantaggi e svantaggi:
| Pro | Contro |
| Prestazioni di velocità eccezionali per attività complesse | Grande consumo di memoria |
| Tolleranza ai guasti | Difficile da usare, eseguire il debug e imparare |
| Facilmente implementabile su cluster cloud | Non ben documentato e le risorse per l'apprendimento sono scarse |
| Supporto multilingue | Visualizzazione dei dati scadente |
| Integrazione per framework di big data come Cassandra e MongoDB | Lento con piccole quantità di dati |
| Possibilità di unire più tipi di database | Pochi algoritmi di apprendimento automatico |
Come funziona lo streaming di Spark?
Spark Streaming si occupa di analisi su larga scala e complesse quasi in tempo reale. La pipeline di elaborazione del flusso distribuito passa attraverso tre fasi:
1. Ricevi streaming di dati da sorgenti di streaming live.
2. Processo i dati su un cluster in parallelo.
3. Uscita i dati elaborati nei sistemi.
Architettura di Spark Streaming
L'architettura principale di Spark Streaming è nello streaming discretizzato di batch. Invece di passare attraverso la pipeline di elaborazione del flusso un record alla volta, i micro-batch vengono assegnati ed elaborati dinamicamente. Pertanto, i dati vengono trasferiti ai lavoratori in base alle risorse disponibili e alla località.
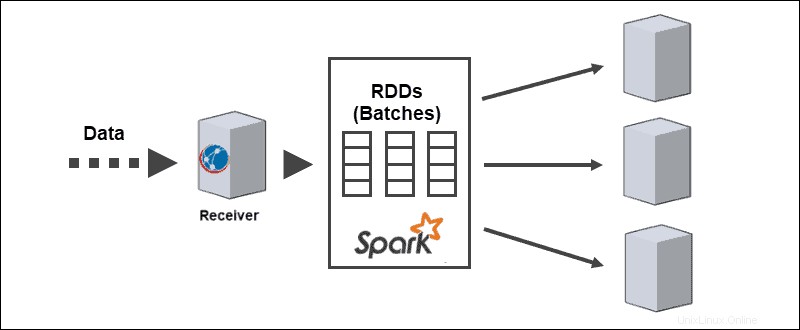
Quando i dati arrivano, il ricevitore li divide in partizioni di RDD. La conversione in RDD consente l'elaborazione di batch utilizzando codici Spark e librerie poiché gli RDD sono un'astrazione fondamentale dei set di dati Spark.
Sorgenti di streaming Spark
I flussi di dati richiedono dati ricevuti dalle origini. Spark streaming divide queste fonti in due categorie:
- Fonti di base. Le sorgenti direttamente disponibili nell'API Streaming core, come connessioni socket e file system compatibili con HDFS
- Fonti avanzate. Le origini richiedono il collegamento delle dipendenze e non sono disponibili nell'API principale di Streaming, come Kafka o Kinesis.
Ogni ingresso DStream si collega a un ricevitore. Per flussi di dati paralleli, la creazione di più DStream genera anche più ricevitori.
Attiva le operazioni di streaming
Spark Streaming include l'esecuzione di diversi tipi di operazioni:
1. Operazioni di trasformazione modificare i dati ricevuti dai DStream di input, simili a quelli applicati agli RDD. Le operazioni di trasformazione valutano pigramente e non vengono eseguite finché i dati non raggiungono l'output.
2. Operazioni di output inviare i DStream a sistemi esterni, come database o file system. Il passaggio a sistemi esterni attiva le operazioni di trasformazione.
3. Operazioni DataFrame e SQL si verificano durante la conversione di RDD in DataFrame e la registrazione come tabelle temporanee per eseguire query.
4. Operazioni MLlib vengono utilizzati per eseguire algoritmi di apprendimento automatico, tra cui:
- Algoritmi di streaming si applicano ai dati in tempo reale, come la regressione lineare in streaming o lo streaming di k-mean.
- Algoritmi offline per apprendere un modello offline con dati storici e applicare l'algoritmo allo streaming di dati online.
Esempio di Spark Streaming
L'esempio di streaming ha la struttura seguente:
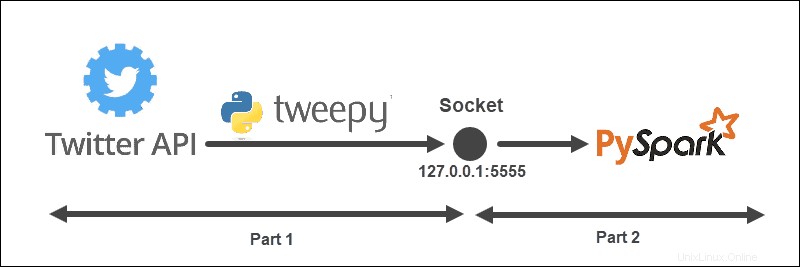
L'architettura è divisa in due parti e viene eseguita da due file:
- Esegui il primo file per stabilire una connessione con l'API di Twitter e creare un socket tra l'API di Twitter e Spark. Mantieni il file in esecuzione.
- Esegui il secondo file per richiedere e avviare lo streaming dei dati, stampando su console i Tweet elaborati. I dati inviati non elaborati vengono stampati nel primo file.
Crea un oggetto Listener Twitter
Il TweetListener oggetto ascolta i Tweet dallo stream di Twitter con StreamListener da tweepy . Quando viene effettuata una richiesta sul socket al server (locale), il TweetListener ascolta i dati ed estrae le informazioni sul Tweet (il testo del Tweet). Se l'oggetto Tweet esteso è disponibile, TweetListener recupera quello esteso campo, altrimenti il testo campo viene recuperato. Infine, l'ascoltatore aggiunge __end alla fine di ogni Tweet. Questo passaggio successivo ci aiuta a filtrare il flusso di dati in Spark.
import tweepy
import json
from tweepy.streaming import StreamListener
class TweetListener(StreamListener):
# tweet object listens for the tweets
def __init__(self, csocket):
self.client_socket = csocket
def on_data(self, data):
try:
# Load data
msg = json.loads(data)
# Read extended Tweet if available
if "extended_tweet" in msg:
# Add "__end" at the end of each Tweet
self.client_socket\
.send(str(msg['extended_tweet']['full_text']+" __end")\
.encode('utf-8'))
print(msg['extended_tweet']['full_text'])
# Else read Tweet text
else:
# Add "__end" at the end of each Tweet
self.client_socket\
.send(str(msg['text']+"__end")\
.encode('utf-8'))
print(msg['text'])
return True
except BaseException as e:
print("error on_data: %s" % str(e))
return True
def on_error(self, status):
print(status)
return TrueSe si verificano errori nella connessione, la console stampa le informazioni.
Raccogli le credenziali dello sviluppatore Twitter
Il portale per sviluppatori di Twitter contiene le credenziali OAuth per stabilire una connessione API con Twitter. Le informazioni si trovano nell'applicazione Chiavi e token scheda.
Per raccogliere i dati:
1. Genera la Chiave API e segreto che si trova nelle Chiavi del consumatore sezione del progetto e salvare le informazioni:
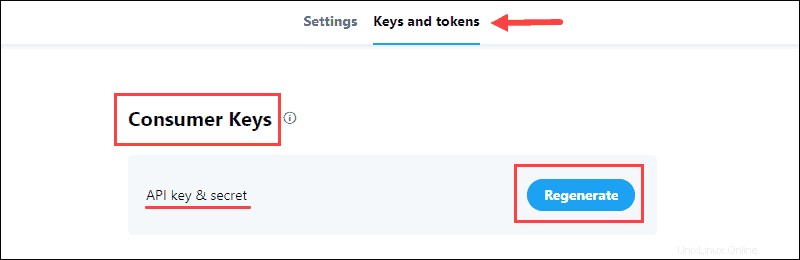
Le Chiavi del consumatore verifica su Twitter la tua identità, come un nome utente.
2. Genera il token di accesso e segreto dai Token di autenticazione sezione e salvare le informazioni:
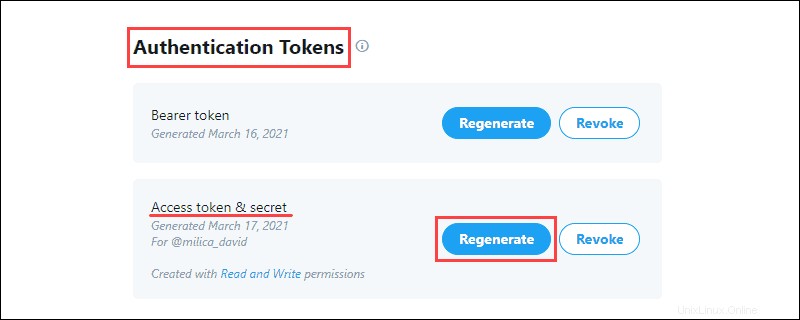
I Token di autenticazione consente di estrarre dati specifici da Twitter.
Invia dati dall'API di Twitter al socket
Utilizzando le credenziali dello sviluppatore, compila la API_KEY , API_SECRET , ACCESS_TOKEN e ACCESS_SECRET per accedere all'API di Twitter.
La funzione inviadati esegue il flusso di Twitter quando un client effettua una richiesta. La richiesta di flusso viene prima verificata, quindi viene creato un oggetto listener e i dati del flusso filtrano in base alla parola chiave e alla lingua.
Ad esempio:
from tweepy import Stream
from tweepy import OAuthHandler
API_KEY = "api_key"
API_SECRET = "api_secret"
ACCESS_TOKEN = "access_token"
ACCESS_SECRET = "access_secret"
def sendData(c_socket, keyword):
print("Start sending data from Twitter to socket")
# Authentication based on the developer credentials from twitter
auth = OAuthHandler(API_KEY, API_SECRET)
auth.set_access_token(ACCESS_TOKEN, ACCESS_SECRET)
# Send data from the Stream API
twitter_stream = Stream(auth, TweetListener(c_socket))
# Filter by keyword and language
twitter_stream.filter(track = keyword, languages=["en"])Crea socket TCP in ascolto sul server
L'ultima parte del primo file include la creazione di un socket in ascolto su un server locale. L'indirizzo e la porta sono associati e sono in ascolto per le connessioni dal client Spark.
Ad esempio:
import socket
if __name__ == "__main__":
# Create listening socket on server (local)
s = socket.socket()
# Host address and port
host = "127.0.0.1"
port = 5555
s.bind((host, port))
print("Socket is established")
# Server listens for connections
s.listen(4)
print("Socket is listening")
# Return the socket and the address of the client
c_socket, addr = s.accept()
print("Received request from: " + str(addr))
# Send data to client via socket for selected keyword
sendData(c_socket, keyword = ['covid'])
Una volta che il client Spark effettua una richiesta, il socket e l'indirizzo del client vengono stampati sulla console. Quindi, il flusso di dati viene inviato al client in base al filtro delle parole chiave selezionato.
Questo passaggio conclude il codice nel primo file. L'esecuzione stampa le seguenti informazioni:

Mantieni il file in esecuzione e procedi alla creazione di un client Spark.
Crea un ricevitore Spark DStream
In un altro file, crea un contesto Spark e un contesto di streaming locale con intervalli batch di un secondo. Il client legge dal nome host e dal socket della porta.
import findspark
findspark.init()
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
sc = SparkContext(appName="tweetStream")
# Create a local StreamingContext with batch interval of 1 second
ssc = StreamingContext(sc, 1)
# Create a DStream that conencts to hostname:port
lines = ssc.socketTextStream("127.0.0.1", 5555)Preelabora i dati
La preelaborazione degli RDD include la suddivisione delle righe di dati ricevute dove __end appare e trasformando il testo in minuscolo. I primi dieci elementi vengono stampati sulla console.
# Split Tweets
words = lines.flatMap(lambda s: s.lower().split("__end"))
# Print the first ten elements of each DStream RDD to the console
words.pprint()Dopo aver eseguito il codice, non accade nulla poiché la valutazione è pigra. Il calcolo inizia quando inizia il contesto di streaming.
Inizia lo streaming del contesto e del calcolo
L'avvio del contesto di streaming invia una richiesta all'host. L'host invia i dati raccolti da Twitter al client Spark e il client preelabora i dati. La console quindi stampa il risultato.
# Start computing
ssc.start()
# Wait for termination
ssc.awaitTermination()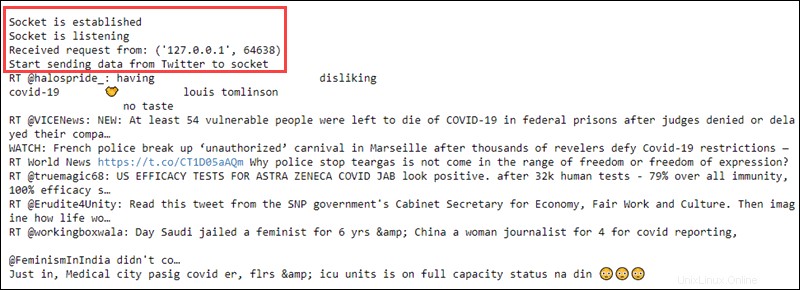
L'avvio del contesto di streaming stampa sul primo file una richiesta ricevuta e trasmette il testo dei dati grezzi:
Il secondo file legge i dati ogni secondo dal socket e la preelaborazione si applica ai dati. Le prime due righe sono vuote finché non viene stabilita la connessione:
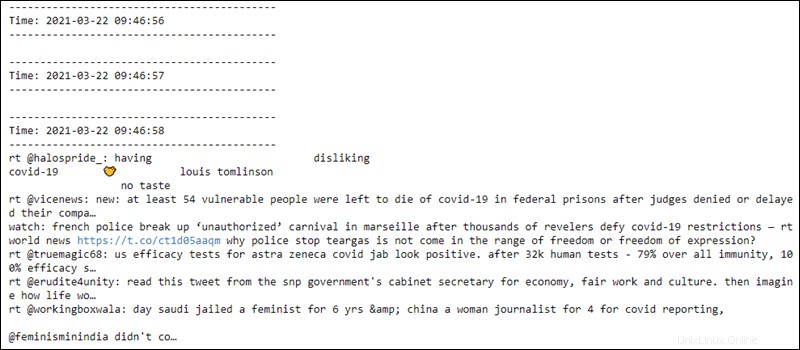
Il contesto di streaming è pronto per essere terminato in qualsiasi momento.