Introduzione
Apache Hive è uno strumento di data warehousing utilizzato per eseguire query e analizzare dati strutturati in Apache Hadoop. Utilizza un linguaggio simile a SQL chiamato HiveQL.
In questo articolo, scopri come creare una tabella in Hive e caricare i dati. Ti mostreremo anche i comandi HiveQL cruciali per visualizzare i dati.

Prerequisiti
- Un sistema che esegue Linux
- Un account utente con sudo o root privilegi
- Accesso a una finestra di terminale/riga di comando
- Lavorare Hadoop installazione
- Alveare funzionante installazione
Crea e carica una tabella nell'alveare
Una tabella in Hive è un insieme di dati che utilizza uno schema per ordinare i dati in base a determinati identificatori.
La sintassi generale per la creazione di una tabella in Hive è:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
(col_name data_type [COMMENT 'col_comment'],, ...)
[COMMENT 'table_comment']
[ROW FORMAT row_format]
[FIELDS TERMINATED BY char]
[STORED AS file_format];
Segui i passaggi seguenti per creare una tabella in Hive.
Fase 1:crea un database
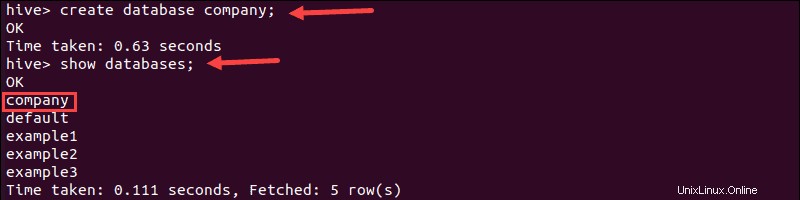
1. Crea un database denominato "azienda" eseguendo create comando:
create database company;Il terminale stampa un messaggio di conferma e il tempo necessario per eseguire l'azione.
2. Successivamente, verifica che il database sia stato creato eseguendo show comando:
show databases;3. Trova il database "azienda" nell'elenco:
4. Aprire il database “azienda” utilizzando il seguente comando:
use company;
Fase 2:crea una tabella in Hive
Il database "azienda" non contiene tabelle dopo la creazione iniziale. Creiamo una tabella i cui identificatori corrispondano al file .txt da cui vuoi trasferire i dati.
1. Crea un file "employees.txt" in /hdoop directory. Il file deve contenere dati sui dipendenti:

2. Disporre i dati dal file "employees.txt" in colonne. I nomi delle colonne nel nostro esempio sono:
- ID
- Nome
- Paese
- Dipartimento
- Stipendio
3. Utilizzare i nomi delle colonne durante la creazione di una tabella. Crea la tabella eseguendo il comando seguente:
create table employees (id int, name string, country string, department string, salary int)
4. Creare uno schema logico che disponga i dati dal file .txt alle colonne corrispondenti. Nel file "employees.txt", i dati sono separati da un '-' . Per creare un tipo di schema logico:
row format delimited fields terminated by '-';Il terminale stampa un messaggio di conferma:

5. Verifica se la tabella è stata creata eseguendo lo show comando:
show tables;
Fase 3:carica i dati da un file
Hai creato una tabella, ma è vuota perché i dati non vengono caricati dal file "employees.txt" che si trova in /hdoop directory.
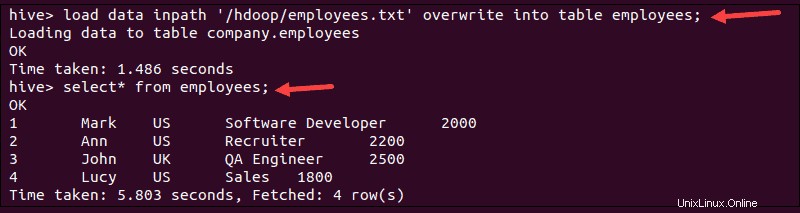
1. Carica i dati eseguendo il load comando:
load data inpath '/hdoop/employees.txt' overwrite into table employees;
2. Verifica se i dati sono stati caricati eseguendo select comando:
select * from employees;Il terminale stampa i dati importati da employees.txt file:
Visualizza i dati dell'alveare
Sono disponibili diverse opzioni per visualizzare i dati dalla tabella. Utilizzando le seguenti opzioni, puoi manipolare grandi quantità di dati in modo più efficiente.
Visualizza colonne
Visualizza le colonne di una tabella eseguendo desc comando:
desc employees;L'output mostra i nomi e le proprietà delle colonne:

Visualizza i dati selezionati
Supponiamo che tu voglia visualizzare i dipendenti e i loro paesi di origine. Seleziona e visualizza i dati eseguendo select comando:
select name,country from employees;L'output contiene l'elenco dei dipendenti e dei loro paesi:
