Introduzione
MySQL è un'applicazione di database che memorizza i dati in righe e colonne di tabelle diverse per evitare duplicazioni. Possono verificarsi valori duplicati, che possono influire sulle prestazioni di MySQL.
Questa guida ti mostrerà come trovare valori duplicati in un database MySQL .

Prerequisiti
- Un'installazione esistente di MySQL
- Credenziali dell'account utente root per MySQL
- Una riga di comando/finestra del terminale
Impostazione di una tabella campioni (opzionale)
Questo passaggio ti aiuterà a creare una tabella di esempio con cui lavorare. Se hai già un database su cui lavorare, vai alla sezione successiva.
Apri una finestra di terminale e passa alla shell MySQL:
mysql –u root –pElenca i database esistenti:
SHOW databases;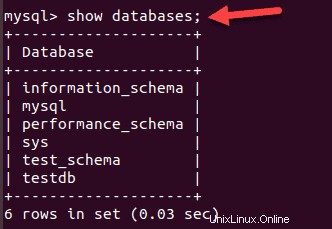
Crea un nuovo database che non esiste già:
CREATE database sampledb;Seleziona la tabella che hai appena creato:
USE sampledb;Crea una nuova tabella con i seguenti campi:
CREATE TABLE dbtable (
id INT PRIMARY KEY AUTO_INCREMENT,
date_x VARCHAR(10) NOT NULL,
system_x VARCHAR(50) NOT NULL,
test VARCHAR(50) NOT NULL
);Inserisci righe nella tabella:
INSERT INTO dbtable (date_x,system_x,test)
VALUES ('01/03/2020','system1','hard_drive'),
('01/04/2020','system2','memory'),
('01/10/2020','system2','processor'),
('01/14/2020','system3','hard drive'),
('01/10/2020','system2','processor'),
('01/20/2020','system4','hard drive'),
('01/24/2020','system5','memory'),
('01/29/2020','system6','hard drive'),
('02/02/2020','system7','motherboard'),
('02/04/2020','system8','graphics card'),
('02/02/2020','system7','motherboard'),
('02/08/2020','system9','hard drive');Esegui la seguente query SQL:
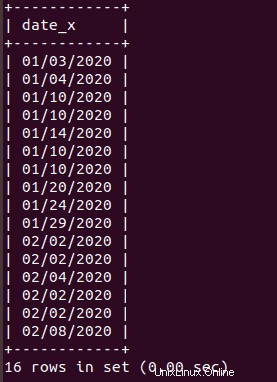
SELECT * FROM dbtable
ORDER BY date_x;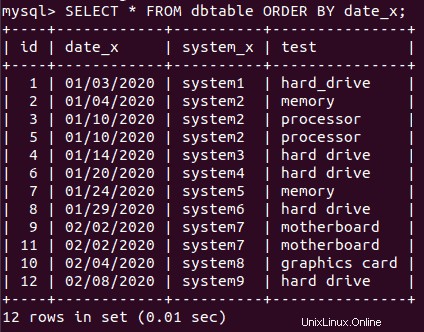
Trovare duplicati in MySQL
Trova valori duplicati in una singola colonna
Usa il GROUP BY funzione per identificare tutte le voci identiche in una colonna. Continua con un COUNT() HAVING funzione per elencare tutti i gruppi con più di una voce.
SELECT
test,
COUNT(test)
FROM
dbtable
GROUP BY test
HAVING COUNT(test) > 1;
Trova valori duplicati in più colonne
Potresti voler elencare i duplicati esatti, con le stesse informazioni in tutte e tre le colonne.
SELECT
date_x, COUNT(date_x),
system_x, COUNT(system_x),
test, COUNT(test)
FROM
dbtable
GROUP BY
date_x,
system_x,
test
HAVING COUNT(date_x)>1
AND COUNT(system_x)>1
AND COUNT(test)>1;

Questa query funziona selezionando e testando il >1 condizione su tutte e tre le colonne. Il risultato è che nell'output vengono restituite solo le righe con valori duplicati.
Controlla duplicati in più tabelle con INNER JOIN
Usa la funzione INNER JOIN per trovare duplicati che esistono in più tabelle.
Esempio di sintassi per un INNER JOIN la funzione è simile a questa:
SELECT column_name
FROM table1
INNER JOIN table2
ON table1.column_name = table2.column name;
Per testare questo esempio, hai bisogno di una seconda tabella che contenga alcune informazioni duplicate da sampledb tabella che abbiamo creato sopra.
SELECT dbtable.date_x
FROM dbtable
INNER JOIN new_table
ON dbtable.date_x = new_table.date_x;
Verranno visualizzate tutte le date duplicate esistenti tra i dati esistenti e la nuova_tabella .