Introduzione
MySQL è una popolare applicazione di database open source che archivia e struttura i dati in modo significativo e facilmente accessibile. Con applicazioni di grandi dimensioni, l'enorme quantità di dati può causare problemi di prestazioni.
Questa guida fornisce diversi suggerimenti per l'ottimizzazione su come migliorare le prestazioni di un database MySQL .

Prerequisiti
- Un sistema Linux con MySQL installato e funzionante, Centos o Ubuntu
- Un database esistente
- Credenziali di amministratore per il sistema operativo e il database
Regolazione delle prestazioni di MySQL del sistema
A livello di sistema, regolerai le opzioni hardware e software per migliorare le prestazioni di MySQL.
1. Bilancia le quattro risorse hardware principali

Archiviazione
Prenditi un momento per valutare il tuo spazio di archiviazione. Se utilizzi unità disco rigido tradizionali (HDD), puoi eseguire l'upgrade alle unità a stato solido (SSD) per migliorare le prestazioni.
Utilizza uno strumento come iotop o sar da sysstat pacchetto per monitorare le velocità di input/output del disco. Se l'utilizzo del disco è molto più elevato rispetto all'utilizzo di altre risorse, prendi in considerazione l'aggiunta di più spazio di archiviazione o l'aggiornamento a uno spazio di archiviazione più veloce.
Processore
I processori sono generalmente considerati la misura della velocità del tuo sistema. Usa il top di Linux comando per una ripartizione di come vengono utilizzate le risorse. Presta attenzione ai processi MySQL e alla percentuale di utilizzo del processore che richiedono.
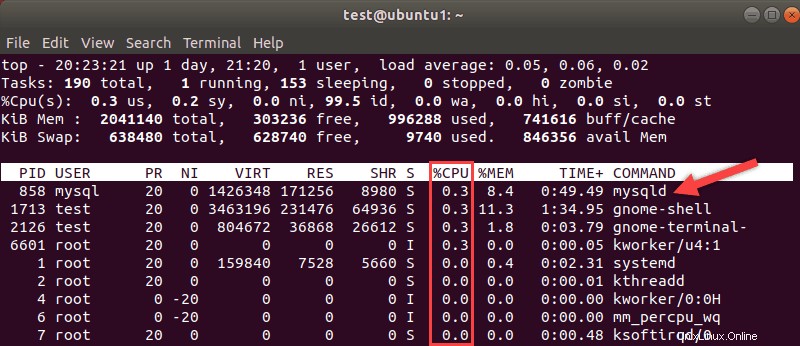
I processori sono più costosi da aggiornare, ma se la tua CPU è un collo di bottiglia, potrebbe essere necessario un aggiornamento.
Memoria
La memoria rappresenta la quantità totale di RAM nel server di archiviazione del database MySQL. Puoi regolare la cache di memoria (ne parleremo più avanti) per migliorare le prestazioni . Se non hai abbastanza memoria, o se la memoria esistente non è ottimizzata, puoi finire per danneggiare le tue prestazioni invece di migliorarle.
Come altri colli di bottiglia, se il tuo server è costantemente a corto di memoria, puoi eseguire l'aggiornamento aggiungendone altra. Se si esaurisce la memoria, il server memorizza nella cache i dati (come un disco rigido) per fungere da memoria. La memorizzazione nella cache del database rallenta le tue prestazioni.
Rete
È importante monitorare il traffico di rete per assicurarsi di disporre di un'infrastruttura sufficiente per gestire il carico.
Il sovraccarico della rete può causare latenza, caduta di pacchetti e persino interruzioni del server. Assicurati di disporre di una larghezza di banda di rete sufficiente per soddisfare i normali livelli di traffico del database.
2. Usa InnoDB, non MyISAM
Il mioISAM è un vecchio stile di database utilizzato per alcuni database MySQL. È una progettazione di database meno efficiente. Il nuovo InnoDB supporta funzionalità più avanzate e dispone di meccanismi di ottimizzazione integrati.
InnoDB utilizza un indice cluster e conserva i dati nelle pagine, che sono archiviate in blocchi fisici consecutivi. Se un valore è troppo grande per una pagina, InnoDB lo sposta in un'altra posizione, quindi indicizza il valore. Questa funzione aiuta a mantenere i dati rilevanti nello stesso posto sul dispositivo di archiviazione, il che significa che il disco rigido fisico impiega meno tempo per accedere ai dati.
3. Usa l'ultima versione di MySQL
L'utilizzo dell'ultima versione non è sempre possibile per i database precedenti e legacy. Ma quando possibile, dovresti controllare la versione di MySQL in uso e aggiornarla all'ultima.
Una parte dello sviluppo in corso include miglioramenti delle prestazioni. Alcune comuni regolazioni delle prestazioni potrebbero essere rese obsolete dalle versioni più recenti di MySQL. In generale, è sempre meglio utilizzare il miglioramento delle prestazioni MySQL nativo rispetto ai file di configurazione e di scripting.
Regolazione delle prestazioni del software MySQL
L'ottimizzazione delle prestazioni SQL è il processo per massimizzare la velocità delle query su un database relazionale. L'attività di solito coinvolge più strumenti e tecniche.
Questi metodi implicano:
- Modificare i file di configurazione di MySQL.
- Scrivere query di database più efficienti.
- Strutturare il database per recuperare i dati in modo più efficiente.
4. Prendi in considerazione l'utilizzo di uno strumento di miglioramento automatico delle prestazioni
Come con la maggior parte dei software, non tutti gli strumenti funzionano su tutte le versioni di MySQL. Esamineremo tre utilità per valutare il database MySQL e consigliare modifiche per migliorare le prestazioni.
Il primo è il tuning-primer. Questo strumento è un po' più vecchio, progettato per MySQL 5.5 – 5.7. Può analizzare il database e suggerire impostazioni per migliorare le prestazioni. Ad esempio, potrebbe suggerire di aumentare la query_cache_size parametro se sembra che il tuo sistema non possa elaborare le query abbastanza rapidamente da mantenere la cache vuota.
Il secondo strumento di ottimizzazione, utile per i database SQL più moderni, è MySQLTuner. Questo script (mysqltuner.pl ) è scritto in Perl. Come tuning-primer, analizza la configurazione del database alla ricerca di colli di bottiglia e inefficienze. L'output mostra metriche e consigli:
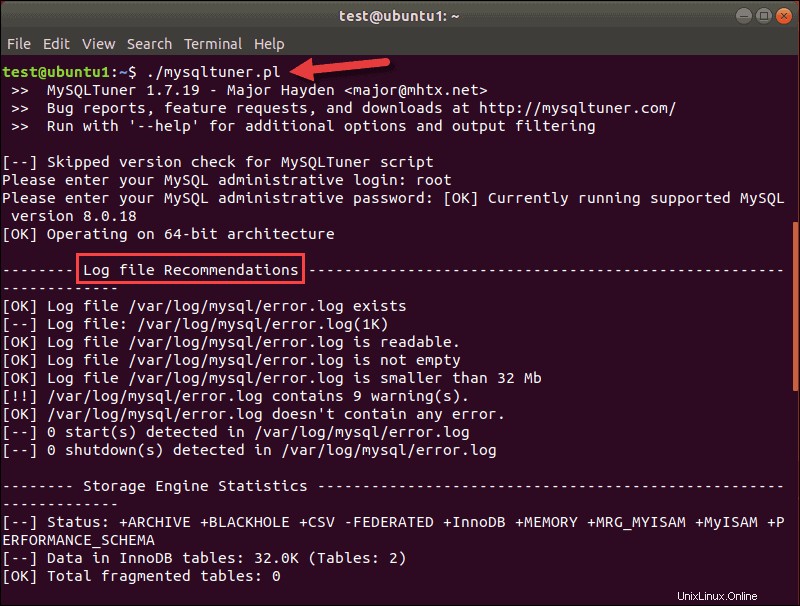
Nella parte superiore dell'output, puoi vedere la versione dello strumento MySQLTuner e il tuo database.
Lo script funziona con MySQL 8.x. I consigli sui file di registro sono i primi nell'elenco, ma se scorri fino in fondo, puoi vedere i consigli generali per migliorare le prestazioni di MySQL.
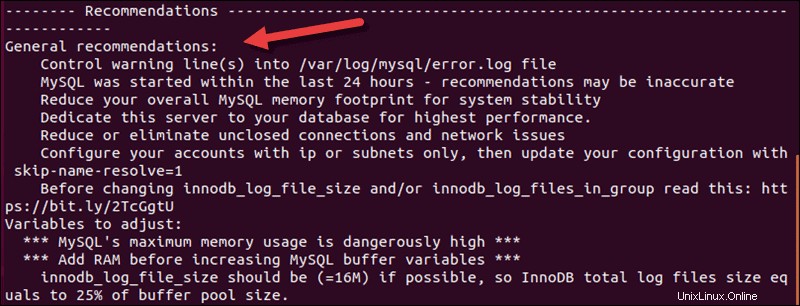
La terza utilità, che potresti già avere, è phpMyAdmin Advisor . Come le altre due utilità, valuta il database e consiglia le modifiche. Se stai già utilizzando phpMyAdmin, Advisor è uno strumento utile che puoi utilizzare all'interno della GUI.
5. Ottimizza le query
Una query è una richiesta codificata per cercare nel database i dati che corrispondono a un determinato valore. Esistono alcuni operatori di query che, per loro stessa natura, richiedono molto tempo per essere eseguiti. Le tecniche di ottimizzazione delle prestazioni SQL aiutano a ottimizzare le query per tempi di esecuzione migliori.
Il rilevamento di query con tempi di esecuzione scarsi è una delle principali attività di ottimizzazione delle prestazioni. Le query comunemente implementate su set di dati di grandi dimensioni sono lente e occupano i database. Le tabelle non sono quindi disponibili per altre attività.
Ad esempio, un database OLTP richiede transazioni veloci e un'efficace elaborazione delle query. L'esecuzione di una query inefficiente blocca l'utilizzo del database e blocca gli aggiornamenti delle informazioni.
Se il tuo ambiente si basa su query automatizzate come i trigger , potrebbero avere un impatto sulle prestazioni. Controlla e termina i processi MySQL che potrebbero accumularsi nel tempo.
6. Utilizzare gli indici ove appropriato
Molte query di database utilizzano una struttura simile a questa:
SELECT … WHEREQueste query implicano la valutazione, il filtraggio e il recupero dei risultati. Puoi ristrutturarli aggiungendo un piccolo set di indici per le relative tabelle. La query può essere indirizzata all'indice per velocizzare la query.
7. Funzioni nei predicati
Evitare di utilizzare una funzione nel predicato di una query. Ad esempio:
SELECT * FROM MYTABLE WHERE UPPER(COL1)='123'Copy
Il UPPER la notazione crea una funzione, che deve operare durante il SELECT operazione. Questo raddoppia il lavoro svolto dalla query e dovresti evitarlo se possibile.
8. Evita % jolly in un predicato
Durante la ricerca tra dati testuali, i caratteri jolly aiutano a fare una ricerca più ampia. Ad esempio, per selezionare tutti i nomi che iniziano con ch , crea un indice nella colonna del nome ed esegui:
SELECT * FROM person WHERE name LIKE "ch%"La query esegue la scansione degli indici, riducendo il costo della query:

Tuttavia, eseguire una ricerca di nomi utilizzando i caratteri jolly all'inizio aumenta notevolmente il costo della query poiché una scansione di indicizzazione non si applica alle estremità delle stringhe:
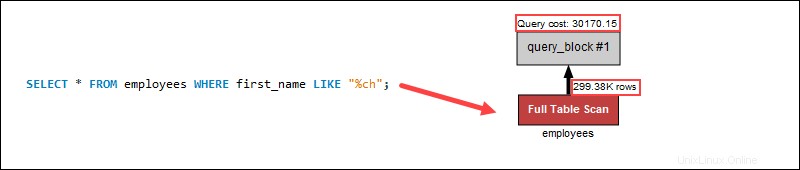
Un carattere jolly all'inizio di una ricerca non applica l'indicizzazione. Al contrario, una scansione completa della tabella esegue la ricerca in ogni riga singolarmente, aumentando il costo della query nel processo. Nella query di esempio, l'utilizzo di un carattere jolly alla fine aiuta a ridurre il costo della query a causa del minor numero di righe della tabella.
Un modo per cercare le estremità delle stringhe è invertire la stringa, indicizzare le stringhe invertite e guardare i caratteri iniziali. Posizionando il carattere jolly alla fine ora si cerca l'inizio della stringa invertita, rendendo la ricerca più efficiente.
9. Specifica le colonne nella funzione SELECT
Un'espressione comunemente usata per le query analitiche ed esplorative è SELECT * . La selezione di più del necessario comporta un'inutile perdita di prestazioni e ridondanza. Se specifichi le colonne di cui hai bisogno, la tua query non dovrà eseguire la scansione di colonne irrilevanti.
Se tutte le colonne sono necessarie, non c'è altro modo per farlo. Tuttavia, la maggior parte dei requisiti aziendali non richiede tutte le colonne disponibili all'interno di un set di dati. Considera invece di selezionare colonne specifiche.
Per riassumere, evita di usare:
SELECT * FROM tableProva invece:
SELECT column1, column2 FROM table10. Usa ORDER BY in modo appropriato
Il ORDER BY espressione ordina i risultati in base alla colonna specificata. Può essere utilizzato per ordinare per due colonne contemporaneamente. Questi dovrebbero essere ordinati nello stesso ordine, crescente o decrescente.
Se provi a ordinare colonne diverse in un ordine diverso, le prestazioni rallenteranno. Puoi combinare questo con un indice per velocizzare l'ordinamento.
11. GROUP BY Invece di SELECT DISTINCT
Il SELEZIONARE DISTINTO query è utile quando si cerca di eliminare i valori duplicati. Tuttavia, l'istruzione richiede una grande quantità di potenza di elaborazione.
Quando possibile, evita di utilizzare SELECT DISTINCT , poiché è molto inefficiente e talvolta confonde. Ad esempio, se una tabella elenca informazioni sui clienti con la seguente struttura:
| id | cognome | indirizzo | città | stato | zip | |
|---|---|---|---|---|---|---|
| 0 | Giovanni | Fabio | Via dei fiori 652 | Los Angeles | CA | 90017 |
| 1 | Giovanni | Fabio | 1215 Ocean Boulevard | Los Angeles | CA | 90802 |
| 2 | Marta | Matteo | 3104 Pico Boulevard | Los Angeles | CA | 90019 |
| 3 | Marta | Jones | 2712 Viale Venezia | Los Angeles | CA | 90019 |
L'esecuzione della query seguente restituisce quattro risultati:
SELECT DISTINCT name, address FROM person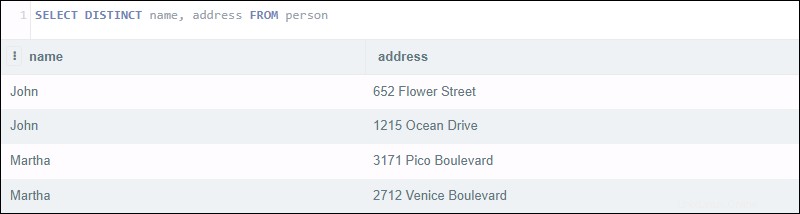
La dichiarazione sembra che dovrebbe restituire un elenco di nomi distinti insieme al loro indirizzo. Invece, la query esamina entrambi la colonna nome e indirizzo. Sebbene ci siano due coppie di clienti con lo stesso nome, i loro indirizzi sono diversi.
Per filtrare i nomi duplicati e restituire gli indirizzi, prova a utilizzare il GROUP BY dichiarazione:
SELECT name, address FROM person GROUP BY name
Il risultato restituisce il primo nome distinto insieme all'indirizzo, rendendo l'istruzione meno ambigua. Per raggruppare per indirizzi univoci, il GROUP BY il parametro cambierebbe semplicemente in indirizzo e restituirebbe lo stesso risultato di DISTINCT dichiarazione più veloce.
Per riassumere, evita di usare:
SELECT DISTINCT column1, column2 FROM tableProva invece a utilizzare:
SELECT column1, column2 FROM table GROUP BY column112. UNISCITI, DOVE, UNIONE, DISTINTO
Prova a usare un inner join quando possibile. Un outer join esamina i dati aggiuntivi al di fuori delle colonne specificate. Va bene se hai bisogno di quei dati, ma è uno spreco di prestazioni includere dati che non saranno richiesti.
Utilizzando INNER JOIN è l'approccio standard per unire le tabelle. La maggior parte dei motori di database accetta l'utilizzo di WHERE anche. Ad esempio, le due query seguenti generano lo stesso risultato:
SELECT * FROM table1 INNER JOIN table2 ON table1.id = table2.idRispetto a:
SELECT * FROM table1, table2 WHERE table1.id = table2.idIn teoria, hanno anche la stessa autonomia.
La scelta se utilizzare JOIN o WHERE query dipendono dal motore di database. Sebbene la maggior parte dei motori abbia lo stesso runtime per i due metodi, in alcuni sistemi di database uno funziona più velocemente dell'altro.
Il UNION e DISTINCT i comandi sono talvolta inclusi nelle query. Come un outer join, va bene usare queste espressioni se sono necessarie. Tuttavia, aggiungono ulteriore ordinamento e lettura del database. Se non ti servono, è meglio trovare un'espressione più efficiente.
13. Usa la funzione SPIEGAZIONE
I moderni database MySQL includono un EXPLAIN funzione.
Aggiungendo il EXPLAIN espressione all'inizio di una query leggerà e valuterà la query. Se sono presenti espressioni inefficienti o strutture confuse, EXPLAIN può aiutarti a trovarli. È quindi possibile modificare la formulazione della query per evitare scansioni involontarie delle tabelle o altri colpi di prestazioni.
14. Configurazione del server MySQL
Questa configurazione comporta la modifica del tuo /etc/mysql/my.cnf file. Procedi con cautela e apporta piccole modifiche alla volta.
query_cache_size – Specifica la dimensione della cache delle query MySQL in attesa di essere eseguite. La raccomandazione è di iniziare con valori piccoli intorno a 10 MB e quindi aumentare fino a non più di 100-200 MB. Con troppe query memorizzate nella cache, puoi riscontrare una cascata di query "In attesa di blocco della cache". Se le tue query continuano a eseguire il backup, una procedura migliore consiste nell'usare EXPLAIN per valutare ogni query e trovare modi per renderla più efficiente.
max_connection – Si riferisce al numero di connessioni consentite nel database. Se ricevi errori citando "Troppe connessioni, ” aumentare questo valore può aiutare.
innodb_buffer_pool_size – Questa impostazione alloca la memoria di sistema come cache di dati per il database. Se disponi di grandi quantità di dati, aumenta questo valore. Prendi nota della RAM richiesta per eseguire altre risorse di sistema.
innodb_io_capacity – Questa variabile imposta la velocità di input/output dal dispositivo di archiviazione. Questo è direttamente correlato al tipo e alla velocità dell'unità di archiviazione. Un HDD da 5400 rpm avrà una capacità molto inferiore rispetto a un SSD di fascia alta o Intel Optane. Puoi regolare questo valore per adattarlo meglio al tuo hardware.