Introduzione
Nel mercato odierno, anche una breve interruzione del servizio può portare a perdere la fiducia dei clienti e, infine, a perdite finanziarie. Ciò è particolarmente vero per le aziende che lavorano in un settore come SaaS.
L'utilizzo del ripristino di emergenza come servizio nel processo aziendale è essenziale se si desidera garantire disponibilità elevata e continuità aziendale. Failover e failback sono alcuni dei metodi di ripristino di emergenza più comunemente utilizzati.
In questo tutorial spiegheremo cosa sono il failover e il failback, come funzionano e cosa li rende diversi.

Failover vs failback:riepilogo
Che si tratti di un'interruzione imprevista, di un disastro naturale o di una manutenzione pianificata, a volte l'ambiente di produzione è temporaneamente non disponibile. Failover e failback sono meccanismi di ripristino di emergenza che aiutano a mantenere la continuità aziendale in caso di interruzione improvvisa.
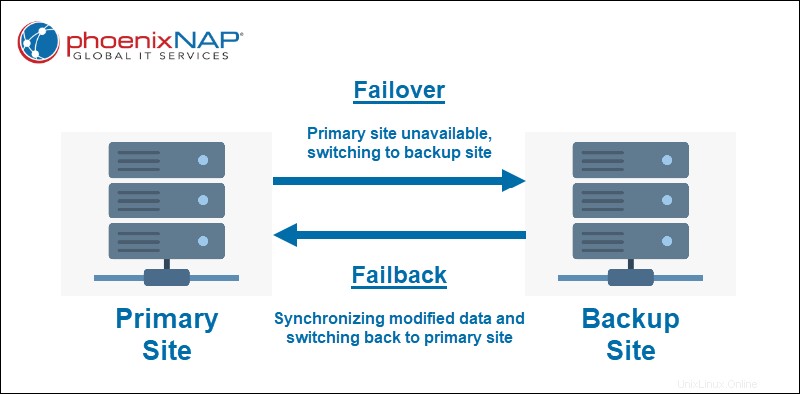
Failover è il processo di passaggio a una struttura di ripristino di backup designata. Si tratta in genere di un sito di ripristino che contiene una copia replicata di tutti i sistemi e dei dati dal sito di produzione principale. Tutte le modifiche apportate durante un failover vengono salvate nella memoria virtuale.
Failback è un meccanismo di continuità aziendale utilizzato quando il sito di produzione principale è nuovamente operativo. La produzione viene restituita al sito originale (o nuovo) durante un failback e tutte le modifiche salvate nell'archivio virtuale vengono sincronizzate.
Cos'è un failover?
Failover è il processo di passaggio senza interruzioni da un sito di produzione principale a un sito di ripristino di backup. Si verifica un failover quando il sito principale si guasta a causa di un disastro imprevisto o in caso di manutenzione pianificata.
Affinché un failover funzioni, è necessario che sia presente un server bare metal di backup o una macchina virtuale che funga da sistema del sito di ripristino, pronto a sostituire il sito primario in caso di errore. Poiché il failover è un passaggio essenziale nel ripristino di emergenza, i sistemi di backup stessi devono essere immuni ai guasti.
Il failover e il ripristino di emergenza in generale sono necessari per i sistemi che richiedono una disponibilità costante. A livello di server, l'ambiente di backup tiene traccia degli "impulsi" del server primario ed esegue un failover automatico se rileva un'interruzione.
Come funziona un failover?
Esistono due modi per configurare un sistema di failover:un attivo-attivo e attivo-passivo (o standby attivo). Entrambe le configurazioni richiedono almeno due nodi (server o VM) per funzionare correttamente.
In un attivo-attivo configurazione, più nodi sono in esecuzione contemporaneamente. Ciò consente loro di condividere il carico di lavoro e impedire il sovraccarico di qualsiasi nodo. Se un nodo smette di funzionare, il suo carico di lavoro viene assorbito dagli altri nodi attivi finché non si riattiva.
Un attivo-passivo (active-standby) include anche più nodi, ma non tutti sono attivi contemporaneamente. Quando un nodo attivo smette di funzionare, viene attivato un nodo passivo che funge da nodo di failover. Quando il nodo primario è di nuovo funzionante, il nodo di backup riporta le operazioni al nodo primario e diventa nuovamente passivo.
Indipendentemente dal metodo di failover, entrambe le configurazioni richiedono che ogni nodo abbia una configurazione identica. Ciò garantisce coerenza e stabilità durante il passaggio da un sito all'altro.
Cos'è un failback?
Failback è il processo di ritorno al sito principale dopo che l'interruzione pianificata o non pianificata è stata risolta. Il failback di solito segue il failover come parte di un piano di ripristino di emergenza.
Il failback non è l'unico modo per finalizzare un failover. Quando si lavora con macchine virtuali, è possibile eseguire un failback permanente, rendendo la macchina virtuale di backup il nuovo sito principale.
Come funziona un failback?
Durante uno stato di failover, gli amministratori interagiscono con un sito di backup. Eventuali modifiche apportate in quel periodo vengono salvate come dati di modifica .
Quando si verifica un failback, la sincronizzazione dei siti primari e di ripristino comporta la copia di dati di modifica dal recupero al sito primario. Ciò evita la necessità di una copia completa del sistema, risparmiando tempo e migliorando l'affidabilità.
L'esecuzione riuscita di un failback richiede una certa preparazione. Considera i seguenti passaggi prima di tornare al sito principale:
- Verifica la qualità e la larghezza di banda della rete della connessione al sito principale.
- Controlla tutti i dati nel sito di backup per potenziali errori. Ciò è particolarmente importante per i file e la documentazione critici.
- Verifica accuratamente tutti i sistemi primari prima di avviare un failback.
- Prepara e implementa un piano di failback che riduca al minimo i tempi di inattività e i disagi per gli utenti.