Sono stato incuriosito dalla tua domanda e mi sono lasciato trasportare. Questa soluzione genererà un bel file PDF con un indice cliccabile e un codice evidenziato a colori. Troverà tutti i file nella directory corrente e nelle sottodirectory e creerà una sezione nel file PDF per ciascuno di essi (vedere le note di seguito per come rendere più specifico il comando find).
Richiede che tu abbia installato quanto segue (le istruzioni di installazione sono per i sistemi basati su Debian ma queste dovrebbero essere disponibili nei repository della tua distribuzione):
-
pdflatex,colorelistingssudo apt-get install texlive-latex-extra latex-xcolor texlive-latex-recommendedQuesto dovrebbe anche installare un sistema LaTeX di base se non ne hai uno installato.
Una volta installati, usa questo script per creare un documento LaTeX con il tuo codice sorgente. Il trucco sta nell'usare il listings (parte di texlive-latex-recommended ) e color (installato da latex-xcolor ) Pacchetti LaTeX. Il \usepackage[..]{hyperref} è ciò che rende cliccabili gli elenchi nel sommario.
#!/usr/bin/env bash
tex_file=$(mktemp) ## Random temp file name
cat<<EOF >$tex_file ## Print the tex file header
\documentclass{article}
\usepackage{listings}
\usepackage[usenames,dvipsnames]{color} %% Allow color names
\lstdefinestyle{customasm}{
belowcaptionskip=1\baselineskip,
xleftmargin=\parindent,
language=C++, %% Change this to whatever you write in
breaklines=true, %% Wrap long lines
basicstyle=\footnotesize\ttfamily,
commentstyle=\itshape\color{Gray},
stringstyle=\color{Black},
keywordstyle=\bfseries\color{OliveGreen},
identifierstyle=\color{blue},
xleftmargin=-8em,
}
\usepackage[colorlinks=true,linkcolor=blue]{hyperref}
\begin{document}
\tableofcontents
EOF
find . -type f ! -regex ".*/\..*" ! -name ".*" ! -name "*~" ! -name 'src2pdf'|
sed 's/^\..//' | ## Change ./foo/bar.src to foo/bar.src
while read i; do ## Loop through each file
name=${i//_/\\_} ## escape underscores
echo "\newpage" >> $tex_file ## start each section on a new page
echo "\section{$i}" >> $tex_file ## Create a section for each filename
## This command will include the file in the PDF
echo "\lstinputlisting[style=customasm]{$i}" >>$tex_file
done &&
echo "\end{document}" >> $tex_file &&
pdflatex $tex_file -output-directory . &&
pdflatex $tex_file -output-directory . ## This needs to be run twice
## for the TOC to be generated
Esegui lo script nella directory che contiene i file sorgente
bash src2pdf
Questo creerà un file chiamato all.pdf nella directory corrente. Ho provato questo con un paio di file sorgente casuali che ho trovato sul mio sistema (in particolare, due file dalla fonte di vlc-2.0.0 ) e questo è uno screenshot delle prime due pagine del PDF risultante:
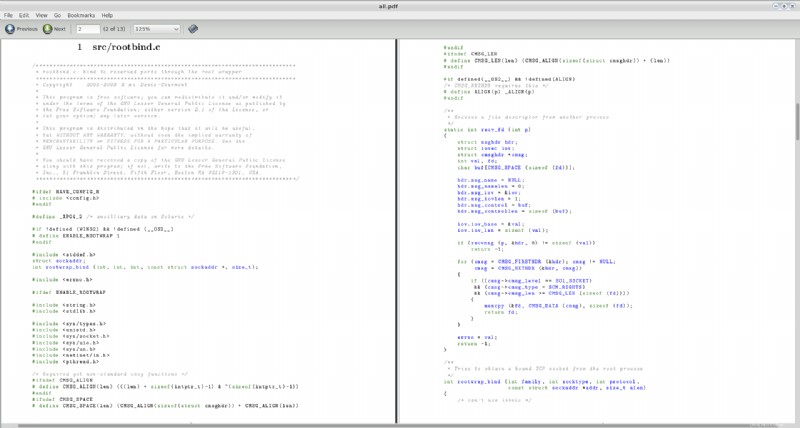
Un paio di commenti:
- Lo script non funzionerà se i nomi dei file del codice sorgente contengono spazi. Dato che stiamo parlando di codice sorgente, presumo che non lo facciano.
- Ho aggiunto
! -name "*~"per evitare file di backup. -
Ti consiglio di utilizzare un
findpiù specifico comando per trovare i tuoi file, altrimenti qualsiasi file casuale verrà incluso nel PDF. Se tutti i tuoi file hanno estensioni specifiche (.ce.had esempio), dovresti sostituirefindnello script con qualcosa di similefind . -name "*\.c" -o -name "\.h" | sed 's/^\..//' | - Gioca con il
listingsopzioni, puoi modificarlo in modo che sia esattamente come lo desideri.
(da StackOverflow)
for i in *.src; do echo "$i"; echo "---"; cat "$i"; echo ; done > result.txt
Questo risulterà un result.txt contenente:
- Nome file
- separatore (---)
- Contenuto del file .src
- Ripeti dall'alto finché tutti i file *.src non sono stati completati
Se il tuo codice sorgente ha un'estensione diversa, basta modificarlo secondo necessità. Puoi anche modificare il bit echo per aggiungere le informazioni necessarie (magari echo "filename $1" o cambiare il separatore, o aggiungere un separatore di fine file).
il collegamento ha altri metodi, quindi usa quello che ti piace di più. Trovo che questo sia il più flessibile, anche se presenta una leggera curva di apprendimento.
Il codice funzionerà perfettamente da un terminale bash (appena testato su VirtualBox Ubuntu)
Se non ti interessa il nome del file e ti interessa solo il contenuto dei file uniti insieme:
cat *.src > result.txt
funzionerà perfettamente.
Un altro metodo suggerito era:
grep "" *.src > result.txt
Che aggiungerà il prefisso a ogni singola riga con il nome del file, che può essere utile per alcune persone, personalmente trovo troppe informazioni, quindi perché il mio primo suggerimento è il ciclo for sopra.
Ringraziamo le persone del forum di StackOverflow.
EDIT:mi sono appena reso conto che stai cercando specificamente HTML o PDF come risultato finale, alcune soluzioni che ho visto sono stampare il file di testo in PostScript e quindi convertire il postscript in PDF. Alcuni codici che ho visto:
groff -Tps result.txt > res.ps
allora
ps2pdf res.ps res.pdf
(Richiede che tu abbia ghostscript)
Spero che questo aiuti.
So di essere mooolto in ritardo, ma qualcuno che cerca una soluzione potrebbe trovarlo utile.
Sulla base della risposta di @terdon, ho creato uno script BASH che fa il lavoro:https://github.com/eljuanchosf/source-code-to-pdf