Ho scritto io stesso un one-liner in perl, che fa proprio questo, e stampa anche il carattere originale. (Si aspetta il file da STDIN)
perl -C7 -ne 'for(split(//)){print sprintf("U+%04X", ord)." ".$_."\n"}'
Tuttavia, dovrebbe esserci un modo migliore di questo.
Avevo bisogno del punto di codice per alcune faccine comuni e mi è venuto in mente questo:
echo -n "" | # -n ignore trailing newline \
iconv -f utf8 -t utf32be | # UTF-32 big-endian happens to be the code point \
xxd -p | # -p just give me the plain hex \
sed -r 's/^0+/0x/' | # remove leading 0's, replace with 0x \
xargs printf 'U+%04X\n' # pretty print the code point
che stampa
U+1F60A
che è il punto di codice per "FACCIA SORRIDENTE CON OCCHI SORRIDENTI".
Ispirato dalla risposta di Neftas, ecco una soluzione leggermente più semplice che funziona con le stringhe, piuttosto che con un singolo carattere:
iconv -f utf8 -t utf32le | hexdump -v -e '8/4 "0x%04x " "\n"' | sed -re"s/0x / /g"
# ^
# The number `8` above determines the number of columns in the output. Modify as needed.
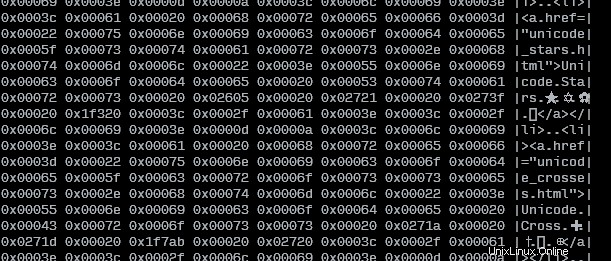
Ho anche creato uno script Bash che legge da stdin, o da un file, e che mostra il testo originale accanto ai valori unicode:
COLWIDTH=8
SHOWTEXT=true
tmpfile=$(mktemp)
cp "${1:-/dev/stdin}" "$tmpfile"
left=$(set -o pipefail; iconv -f utf8 -t utf32le "$tmpfile" | hexdump -v -e $COLWIDTH'/4 "0x%05x " "\n"' | sed -re"s/0x / /g")
if [ $? -gt 0 ]; then
echo "ERROR: Could not convert input" >&2
elif $SHOWTEXT; then
right=$(tr [:space:] . < "$tmpfile" | sed -re "s/.{$COLWIDTH}/|&|\n/g" | sed -re "s/^.{1,$((COLWIDTH+1))}\$/|&|/g")
pr -mts" " <(echo "$left") <(echo "$right")
else
echo "$left"
fi
rm "$tmpfile"