Sì, Linux usa il paging quindi tutti gli indirizzi sono sempre virtuali. (Per accedere alla memoria a un indirizzo fisico noto, Linux mantiene tutta la memoria fisica 1:1 mappata a un intervallo di spazio di indirizzi virtuali del kernel, quindi può semplicemente indicizzare in quell'"array" usando l'indirizzo fisico come offset. Complicazioni modulo per 32 -bit su sistemi con più RAM fisica rispetto allo spazio degli indirizzi del kernel.)
Questo spazio di indirizzi lineare costituito da pagine è suddiviso in quattro segmenti
No, Linux utilizza un modello di memoria flat. La base e il limite per tutti e 4 questi descrittori di segmento sono 0 e -1 (illimitati). cioè si sovrappongono tutti completamente, coprendo l'intero spazio degli indirizzi lineari virtuali a 32 bit.
Quindi la parte rossa è composta da due segmenti
__KERNEL_CSe__KERNEL_DS
No, è qui che hai sbagliato. I registri di segmento x86 non utilizzato per la segmentazione; sono bagaglio legacy x86 che viene utilizzato solo per la modalità CPU e la selezione del livello di privilegio su x86-64 . Invece di aggiungere nuovi meccanismi per questo e eliminare completamente i segmenti per la modalità lunga, AMD ha appena castrato la segmentazione in modalità lunga (base fissata a 0 come tutti quelli usati in modalità a 32 bit comunque) e ha continuato a utilizzare i segmenti solo per scopi di configurazione della macchina che non lo sono particolarmente interessante a meno che tu non stia effettivamente scrivendo codice che passa alla modalità a 32 bit o altro.
(Tranne che puoi impostare una base diversa da zero per FS e/o GS, e Linux lo fa per l'archiviazione thread-local. Ma questo non ha nulla a che fare con come copy_from_user() è implementato, o altro. Deve solo controllare quel valore del puntatore, non con riferimento a nessun segmento o al CPL / RPL di un descrittore di segmento.)
Nella modalità legacy a 32 bit, è possibile scrivere un kernel che utilizza un modello di memoria segmentata, ma nessuno dei sistemi operativi tradizionali lo ha effettivamente fatto. Alcune persone vorrebbero che fosse diventata una cosa, però, ad es. vedi questa risposta che lamenta x86-64 che rende impossibile un sistema operativo in stile Multics. Ma questo non è come funziona Linux.
Linux è un https://wiki.osdev.org/Higher_Half_Kernel, dove i puntatori del kernel hanno un intervallo di valori (la parte rossa) e gli indirizzi dello spazio utente sono nella parte verde. Il kernel può semplicemente dereferenziare gli indirizzi dello spazio utente se le tabelle delle pagine dello spazio utente corrette sono mappate, non ha bisogno di tradurle o fare nulla con i segmenti; questo è ciò che significa avere un modello di memoria piatto . (Il kernel può usare le voci della tabella delle pagine "utente", ma non viceversa). Per x86-64 in particolare, vedi https://www.kernel.org/doc/Documentation/x86/x86_64/mm.txt per la mappa di memoria effettiva.
L'unico motivo per cui queste 4 voci GDT devono essere tutte separate è per motivi a livello di privilegio e che i descrittori dei segmenti di dati rispetto a quelli di codice hanno formati diversi. (Una voce GDT contiene più della semplice base/limite; queste sono le parti che devono essere diverse. Vedi https://wiki.osdev.org/Global_Descriptor_Table)
E in particolare https://wiki.osdev.org/Segmentation#Notes_Regarding_C che descrive come e perché il GDT viene tipicamente utilizzato da un sistema operativo "normale" per creare un modello di memoria flat, con una coppia di descrittori di codice e dati per ogni livello di privilegio .
Per un kernel Linux a 32 bit, solo gs ottiene una base diversa da zero per l'archiviazione locale del thread (quindi indirizzando modalità come [gs: 0x10] accederà a un indirizzo lineare che dipende dal thread che lo esegue). Oppure in un kernel a 64 bit (e spazio utente a 64 bit), Linux usa fs . (Perché x86-64 ha reso GS speciale con il swapgs istruzioni, destinate all'uso con syscall affinché il kernel trovi lo stack del kernel.)
Ma comunque, la base diversa da zero per FS o GS non proviene da una voce GDT, sono impostate con wrgsbase istruzione. (O su CPU che non lo supportano, con una scrittura su un MSR).
ma cosa sono quei flag, vale a dire
0xc09b,0xa09be così via ? Tendo a credere che siano i selettori di segmenti
No, i segment selector sono indici nella GDT. Il kernel sta definendo il GDT come un array C, usando la sintassi dell'inizializzatore designato come [GDT_ENTRY_KERNEL32_CS] = initializer_for_that_selector .
(In realtà i 2 bit bassi di un selettore, cioè il valore del registro del segmento, sono l'attuale livello di privilegio. Quindi GDT_ENTRY_DEFAULT_USER_CS dovrebbe essere `__USER_CS>> 2.)
mov ds, eax attiva l'hardware per indicizzare il GDT, non ricerca lineare per i dati corrispondenti in memoria!
Formato dati GDT:
Stai guardando il codice sorgente Linux x86-64, quindi il kernel sarà in modalità lunga, non in modalità protetta. Possiamo dirlo perché ci sono voci separate per USER_CS e USER32_CS . Il descrittore del segmento di codice a 32 bit avrà il suo L po' cancellato. L'attuale descrizione del segmento CS è ciò che mette una CPU x86-64 in modalità compat a 32 bit rispetto alla modalità lunga a 64 bit. Per entrare nello spazio utente a 32 bit, un iret o sysret imposterà CS:RIP su un selettore di segmento a 32 bit in modalità utente.
penso puoi anche avere la CPU in modalità compat a 16 bit (come la modalità compat non la modalità reale, ma la dimensione dell'operando e la dimensione dell'indirizzo predefinite sono 16). Linux non lo fa, però.
Ad ogni modo, come spiegato in https://wiki.osdev.org/Global_Descriptor_Table and Segmentation,
Ogni descrittore di segmento contiene le seguenti informazioni:
- L'indirizzo di base del segmento
- La dimensione dell'operazione predefinita nel segmento (16 bit/32 bit)
- Il livello di privilegio del descrittore (Ring 0 -> Ring 3)
- La granularità (il limite del segmento è in unità byte/4kb)
- Il limite del segmento (l'offset legale massimo all'interno del segmento)
- La presenza del segmento (è presente o meno)
- Il tipo di descrittore (0 =sistema; 1 =codice/dati)
- Il tipo di segmento (Codice/Dati/Lettura/Scrittura/Accesso/Conforme/Non conforme/Expand-Up/Expand-Down)
Questi sono i bit extra. Non sono particolarmente interessato a quali bit sono quali perché (credo di) capire l'immagine di alto livello di cosa servono le diverse voci GDT e cosa fanno, senza entrare nei dettagli di come è effettivamente codificato.
Ma se controlli i manuali x86 o il wiki di osdev e le definizioni per quelle macro init, dovresti scoprire che risultano in una voce GDT con L bit impostato per segmenti di codice a 64 bit, azzerato per segmenti di codice a 32 bit. E ovviamente il tipo (codice vs. dati) e il livello di privilegio differiscono.
Esclusione di responsabilità
Pubblico questa risposta per chiarire questo argomento da qualsiasi malinteso (come sottolineato da @PeterCordes).
Paginazione
La gestione della memoria in Linux (modalità protetta x86) utilizza il paging per mappare gli indirizzi fisici su un flat virtualizzato spazio indirizzi lineare, da 0x00000000 a 0xFFFFFFFF (su 32 bit), noto come modello di memoria flat . Linux, insieme alla MMU (Memory Management Unit) della CPU, manterrà ogni indirizzo virtuale e logico mappato 1:1 all'indirizzo fisico corrispondente. La memoria fisica è solitamente suddivisa in pagine da 4 KiB, per consentire una più facile gestione della memoria.
Gli indirizzi virtuali del kernel può essere un kernel logico contiguo indirizzi mappati direttamente in pagine fisiche contigue; altri indirizzi virtuali del kernel sono completamente indirizzi virtuali mappati in pagine fisiche non contigue utilizzate per allocazioni di buffer di grandi dimensioni (che superano l'area contigua su sistemi con memoria ridotta) e/o memoria PAE (solo 32 bit). Anche le porte MMIO (I/O mappate in memoria) sono mappate utilizzando gli indirizzi virtuali del kernel.
Ogni indirizzo dereferenziato deve essere un indirizzo virtuale. Sia che si tratti di un indirizzo logico o completamente virtuale, la RAM fisica e le porte MMIO vengono mappate nello spazio degli indirizzi virtuali prima dell'uso.
Il kernel ottiene un pezzo di memoria virtuale usando kmalloc() , puntato da un indirizzo virtuale, ma soprattutto, che è anche un indirizzo logico del kernel, nel senso che ha una mappatura diretta a contiguo pagine fisiche (quindi adatte per DMA). D'altra parte, il vmalloc() routine restituirà una parte di completamente memoria virtuale, puntata da un indirizzo virtuale, ma solo contigua sullo spazio degli indirizzi virtuali e mappata a pagine fisiche non contigue.
Gli indirizzi logici del kernel utilizzano una mappatura fissa tra lo spazio degli indirizzi fisico e quello virtuale. Ciò significa che le regioni virtualmente contigue sono per natura anche fisicamente contigue. Questo non è il caso degli indirizzi completamente virtuali, che puntano a pagine fisiche non contigue.
Gli indirizzi virtuali dell'utente - a differenza degli indirizzi logici del kernel - non usano una mappatura fissa tra indirizzi virtuali e fisici, i processi userland fanno pieno uso della MMU:
- Sono mappate solo le parti utilizzate della memoria fisica;
- La memoria non è contigua;
- La memoria può essere sostituita;
- La memoria può essere spostata;
Più in dettaglio, le pagine di memoria fisica di 4 KiB sono mappate agli indirizzi virtuali nella tabella delle pagine del sistema operativo, ciascuna mappatura nota come PTE (Page Table Entry). La MMU della CPU manterrà quindi una cache di ogni PTE utilizzato di recente dalla tabella delle pagine del sistema operativo. Questa area di memorizzazione nella cache è nota come TLB (Translation Lookaside Buffer). Il cr3 register viene utilizzato per individuare la tabella delle pagine del sistema operativo.
Ogni volta che un indirizzo virtuale deve essere tradotto in uno fisico, verrà cercato il TLB. Se viene trovata una corrispondenza (TLB hit ), l'indirizzo fisico viene restituito e vi si accede. Tuttavia, se non c'è corrispondenza (TLB miss ), il gestore delle miss TLB cercherà la tabella delle pagine per vedere se esiste una mappatura (page walk ). Se ne esiste uno, viene riscritto nel TLB e l'istruzione in errore viene riavviata, questa traduzione successiva troverà quindi un hit nel TLB e l'accesso alla memoria continuerà. Questo è noto come minore errore di pagina.
A volte, il sistema operativo potrebbe dover aumentare la dimensione della RAM fisica spostando le pagine nel disco rigido. Se un indirizzo virtuale si risolve in una pagina mappata nel disco rigido, la pagina deve essere caricata nella RAM fisica prima dell'accesso. Questo è noto come maggiore difetto di pagina. Il gestore degli errori di pagina del sistema operativo dovrà quindi trovare una pagina libera in memoria.
Il processo di traduzione potrebbe non riuscire se non è disponibile alcuna mappatura per l'indirizzo virtuale, il che significa che l'indirizzo virtuale non è valido. Questo è noto come non valido eccezione di errore di pagina e un segfault verrà inviato al processo dal gestore degli errori di pagina del sistema operativo.
Segmentazione della memoria
Modalità reale
La modalità reale utilizza ancora uno spazio di indirizzi di memoria segmentato a 20 bit, con 1 MiB di memoria indirizzabile (0x00000 - 0xFFFFF ) e accesso software diretto illimitato a tutta la memoria indirizzabile, indirizzi bus, porte PMIO (Port-Mapped I/O) e hardware periferico. La modalità reale non offre nessuna protezione della memoria , nessun livello di privilegio e nessun indirizzo virtualizzato. In genere, un registro di segmento contiene il valore del selettore di segmento e l'operando di memoria è un valore di offset relativo alla base del segmento.
Per aggirare la segmentazione (i compilatori C di solito supportano solo il modello di memoria flat), i compilatori C usavano il far non ufficiale tipo di puntatore per rappresentare un indirizzo fisico con un segment:offset notazione di indirizzo logico. Ad esempio, l'indirizzo logico 0x5555:0x0005 , dopo aver calcolato 0x5555 * 16 + 0x0005 restituisce l'indirizzo fisico a 20 bit 0x55555 , utilizzabile in un far pointer come mostrato di seguito:
char far *ptr; /* declare a far pointer */
ptr = (char far *)0x55555; /* initialize a far pointer */
Ad oggi, la maggior parte delle moderne CPU x86 si avvia ancora in modalità reale per compatibilità con le versioni precedenti e successivamente passa alla modalità protetta.
Modalità protetta
In modalità protetta, con il modello di memoria flat , la segmentazione è inutilizzata . I quattro segmenti, vale a dire __KERNEL_CS , __KERNEL_DS , __USER_CS , __USER_DS tutti hanno i loro indirizzi di base impostati su 0. Questi segmenti sono solo bagaglio legacy dal precedente modello x86 in cui è stata utilizzata la gestione della memoria segmentata. In modalità protetta, poiché tutti gli indirizzi di base dei segmenti sono impostati su 0, gli indirizzi logici sono equivalenti agli indirizzi lineari.
La modalità protetta con il modello di memoria flat significa nessuna segmentazione. L'unica eccezione in cui un segmento ha il proprio indirizzo di base impostato su un valore diverso da 0 è quando è coinvolta l'archiviazione locale del thread. Il
FS(eGSa 64 bit) vengono utilizzati registri di segmento a questo scopo.
Tuttavia, i registri di segmento come SS (registro del segmento dello stack), DS (registro del segmento di dati) o CS (code segment register) sono ancora presenti e utilizzati per memorizzare selettori di segmenti a 16 bit , che contengono indici per segmentare i descrittori nella LDT e GDT (Local &Global Descriptor Table).
Ogni istruzione che tocca la memoria implicitamente utilizza un registro di segmento. A seconda del contesto, viene utilizzato un particolare registro di segmento. Ad esempio, il JMP l'istruzione utilizza CS mentre PUSH utilizza SS . I selettori possono essere caricati nei registri con istruzioni come MOV , l'unica eccezione è il CS register che viene modificato solo da istruzioni che influenzano il flusso di esecuzione , come CALL o JMP .
Il CS register è particolarmente utile perché tiene traccia del CPL (Current Privilege Level) nel suo segment selector, conservando così il livello di privilegio per il segmento attuale. Questo valore CPL a 2 bit è sempre equivalente al livello di privilegio corrente della CPU.
Protezione della memoria
Paginazione
Il livello di privilegio della CPU, noto anche come bit di modalità o anello di protezione , da 0 a 3, limita alcune istruzioni che possono sovvertire il meccanismo di protezione o causare caos se consentito in modalità utente, quindi sono riservate al kernel. Un tentativo di eseguirli al di fuori dell'anello 0 provoca una protezione generale eccezione di errore, stesso scenario quando si verifica un errore di accesso al segmento non valido (privilegio, tipo, limite, diritti di lettura/scrittura). Allo stesso modo, qualsiasi accesso alla memoria e ai dispositivi MMIO è limitato in base al livello di privilegio e ogni tentativo di accedere a una pagina protetta senza il livello di privilegio richiesto causerà un'eccezione di page fault.
Il bit di modalità passerà automaticamente dalla modalità utente alla modalità supervisore ogni volta che si verifica una richiesta di interruzione (IRQ), sia il software (ad es. syscall ) o hardware, si verifica.
Su un sistema a 32 bit, è possibile indirizzare efficacemente solo 4GiB di memoria e la memoria è suddivisa in una forma 3GiB/1GiB. Linux (con il paging abilitato) utilizza uno schema di protezione noto come metà kernel superiore dove lo spazio di indirizzamento piatto è diviso in due intervalli di indirizzi virtuali:
-
Indirizzi nell'intervallo
0xC0000000 - 0xFFFFFFFFsono gli indirizzi virtuali del kernel (area rossa). L'intervallo di 896 MiB0xC0000000 - 0xF7FFFFFFmappa direttamente gli indirizzi logici del kernel 1:1 con gli indirizzi fisici del kernel nella memoria insufficiente contigua pagine (utilizzando il__pa()e__va()macro). Il restante intervallo di 128 MiB0xF8000000 - 0xFFFFFFFFviene quindi utilizzato per mappare indirizzi virtuali per allocazioni di buffer di grandi dimensioni, porte MMIO (I/O mappato in memoria) e/o memoria PAE nella memoria elevata non contigua pagine (utilizzandoioremap()eiounmap()). -
Indirizzi nell'intervallo
0x00000000 - 0xBFFFFFFFsono indirizzi virtuali dell'utente (area verde), dove risiedono codice utente, dati e librerie. La mappatura può trovarsi in pagine con poca memoria e con molta memoria non contigue.
La memoria elevata è presente solo su sistemi a 32 bit. Tutta la memoria allocata con
kmalloc()ha una logica indirizzo virtuale (con mappatura fisica diretta); memoria allocata davmalloc()ha un completamente indirizzo virtuale (ma nessuna mappatura fisica diretta). I sistemi a 64 bit hanno un'enorme capacità di indirizzamento, quindi non necessitano di memoria elevata, poiché ogni pagina di RAM fisica può essere indirizzata in modo efficace.
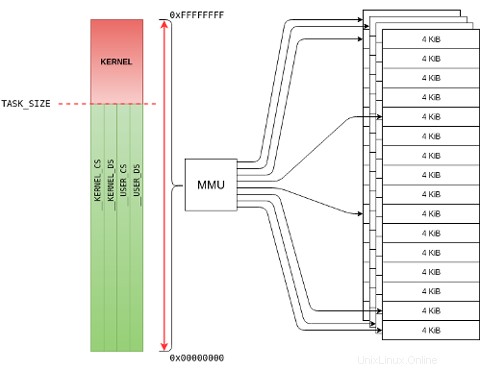
Il confine l'indirizzo tra la metà superiore del supervisore e la metà inferiore dell'area utente è noto come TASK_SIZE_MAX nel kernel Linux. Il kernel verificherà che ogni indirizzo virtuale a cui si accede da qualsiasi processo userland risieda al di sotto di tale limite, come mostrato nel codice seguente:
static int fault_in_kernel_space(unsigned long address)
{
/*
* On 64-bit systems, the vsyscall page is at an address above
* TASK_SIZE_MAX, but is not considered part of the kernel
* address space.
*/
if (IS_ENABLED(CONFIG_X86_64) && is_vsyscall_vaddr(address))
return false;
return address >= TASK_SIZE_MAX;
}
Se un processo userland tenta di accedere a un indirizzo di memoria superiore a TASK_SIZE_MAX , il do_kern_addr_fault() routine chiamerà il __bad_area_nosemaphore() routine, segnalando infine l'attività in errore con un SIGSEGV (usando get_current() per ottenere il task_struct ):
/*
* To avoid leaking information about the kernel page table
* layout, pretend that user-mode accesses to kernel addresses
* are always protection faults.
*/
if (address >= TASK_SIZE_MAX)
error_code |= X86_PF_PROT;
force_sig_fault(SIGSEGV, si_code, (void __user *)address, tsk); /* Kill the process */
Le pagine hanno anche un bit di privilegio, noto come U flag ser/Supervisor, utilizzato per SMAP (Supervisor Mode Access Prevention) oltre a R ead/Write utilizzato da SMEP (Supervisor Mode Execution Prevention).
Segmentazione
Le architetture precedenti che utilizzano la segmentazione di solito eseguono la verifica dell'accesso al segmento utilizzando il bit di privilegio GDT per ogni segmento richiesto. Il bit di privilegio del segmento richiesto, noto come DPL (Descriptor Privilege Level), viene confrontato con il CPL del segmento corrente, assicurando che CPL <= DPL . Se true, l'accesso alla memoria viene quindi consentito al segmento richiesto.