Non ci sono problemi di imprecisione o affidabilità qui, stai solo confrontando due numeri diversi:dimensione logica e dimensione fisica.
Ecco l'illustrazione di Wikipedia per i file sparsi:
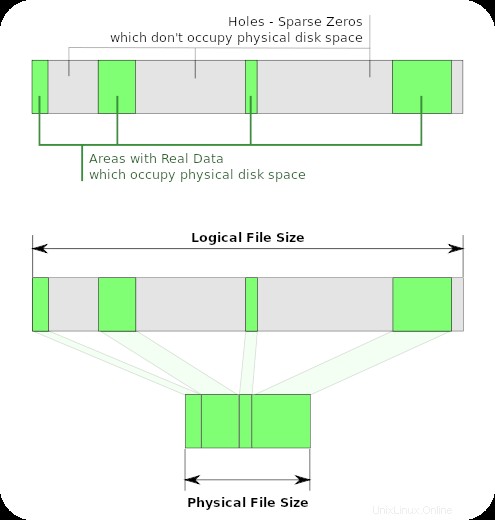
ls mostra le aree grigie+verdi, la lunghezza logica del file. du (senza --apparent-size ) mostra solo le aree verdi, poiché sono quelle che occupano spazio.
Puoi creare un file sparse con dd count=0 bs=1M seek=100 of=myfile .
ls mostra 100MiB perché questa è la lunghezza del file:
$ ls -lh myfile
-rw-r----- 1 me me 100M Jul 15 10:57 myfile
du mostra 0, perché è la quantità di dati allocati:
$ du myfile
0 myfile
ls -l --block-size=M
ti darà un elenco di formato lungo (necessario per vedere effettivamente la dimensione del file) e arrotonda le dimensioni del file fino al MiB più vicino .
Se vuoi MB (10^6 byte) anziché MiB (2^20 byte) unità, usa --block-size=MB invece.
Se non vuoi il M suffisso allegato alla dimensione del file, puoi usare qualcosa come --block-size=1M . Grazie Stéphane Chazelas per aver suggerito questo.
Questo è descritto nella pagina man per ls; man ls e cerca SIZE . Consente unità diverse da MB/MiB anche, e dall'aspetto (non l'ho provato) anche dimensioni di blocco arbitrarie (quindi potresti vedere la dimensione del file come numero di blocchi da 412 byte, se lo desideri).
Nota che il --block-size parametro è un'estensione GNU in cima a ls di Open Group , quindi potrebbe non funzionare se non si dispone di un'area utente GNU (cosa che fa la maggior parte delle installazioni Linux). Ls da GNU coreutils 8.5 supporta --block-size come descritto sopra.
Esistono diverse nozioni sulla dimensione del file, come spiegato nella risposta di quell'altro guiy e nella figura della pagina wiki sui file sparsi.
Tuttavia, potresti voler utilizzare entrambi i comandi ls(1) e stat(1).
Se codifichi in C, prendi in considerazione l'utilizzo di stat(2) &lseek(2) syscalls.
Vedi anche i riferimenti in questa risposta.