Esiste una speciale mappatura della memoria privata anonima designata (tradizionalmente posizionata appena oltre data/bss, ma il moderno Linux regolerà effettivamente la posizione con ASLR). In linea di principio non è migliore di qualsiasi altra mappatura che potresti creare con mmap , ma Linux ha alcune ottimizzazioni che rendono possibile espandere la fine di questa mappatura (utilizzando il brk syscall) verso l'alto con costi di blocco ridotti rispetto a quanto mmap o mremap incorrerebbe. Questo lo rende interessante per malloc implementazioni da utilizzare durante l'implementazione dell'heap principale.
Puoi usare brk e sbrk te stesso per evitare il "maloc overhead" di cui tutti si lamentano sempre. Ma non puoi usare facilmente questo metodo insieme a malloc quindi è appropriato solo quando non devi free qualsiasi cosa. Perché non puoi. Inoltre, dovresti evitare qualsiasi chiamata alla libreria che potrebbe utilizzare malloc internamente. Cioè. strlen è probabilmente sicuro, ma fopen probabilmente non lo è.
Chiama sbrk proprio come chiameresti malloc . Restituisce un puntatore all'interruzione corrente e incrementa l'interruzione di quella quantità.
void *myallocate(int n){
return sbrk(n);
}
Sebbene non sia possibile liberare allocazioni individuali (perché non esiste un malloc-overhead , ricorda), puoi libera l'intero spazio chiamando brk con il valore restituito dalla prima chiamata a sbrk , riavvolgendo così il brk .
void *memorypool;
void initmemorypool(void){
memorypool = sbrk(0);
}
void resetmemorypool(void){
brk(memorypool);
}
Puoi persino impilare queste regioni, scartando la regione più recente riavvolgendo l'interruzione all'inizio della regione.
Un'altra cosa...
sbrk è utile anche nel code golf perché è più corto di 2 caratteri rispetto a malloc .
Esempio eseguibile minimo
Cosa fa la chiamata di sistema brk()?
Chiede al kernel di permetterti di leggere e scrivere su un pezzo contiguo di memoria chiamato heap.
Se non lo chiedi, potrebbe essere un segfault.
Senza brk :
#define _GNU_SOURCE
#include <unistd.h>
int main(void) {
/* Get the first address beyond the end of the heap. */
void *b = sbrk(0);
int *p = (int *)b;
/* May segfault because it is outside of the heap. */
*p = 1;
return 0;
}
Con brk :
#define _GNU_SOURCE
#include <assert.h>
#include <unistd.h>
int main(void) {
void *b = sbrk(0);
int *p = (int *)b;
/* Move it 2 ints forward */
brk(p + 2);
/* Use the ints. */
*p = 1;
*(p + 1) = 2;
assert(*p == 1);
assert(*(p + 1) == 2);
/* Deallocate back. */
brk(b);
return 0;
}
GitHub a monte.
Quanto sopra potrebbe non colpire una nuova pagina e non segfault anche senza il brk , quindi qui c'è una versione più aggressiva che alloca 16 MiB ed è molto probabile che segfault senza il brk :
#define _GNU_SOURCE
#include <assert.h>
#include <unistd.h>
int main(void) {
void *b;
char *p, *end;
b = sbrk(0);
p = (char *)b;
end = p + 0x1000000;
brk(end);
while (p < end) {
*(p++) = 1;
}
brk(b);
return 0;
}
Testato su Ubuntu 18.04.
Visualizzazione dello spazio degli indirizzi virtuali
Prima di brk :
+------+ <-- Heap Start == Heap End
Dopo brk(p + 2) :
+------+ <-- Heap Start + 2 * sizof(int) == Heap End
| |
| You can now write your ints
| in this memory area.
| |
+------+ <-- Heap Start
Dopo brk(b) :
+------+ <-- Heap Start == Heap End
Per comprendere meglio gli spazi degli indirizzi, dovresti familiarizzare con il paging:come funziona il paging x86?.
Perché abbiamo bisogno di entrambi brk e sbrk ?
brk potrebbe ovviamente essere implementato con sbrk + calcoli di offset, entrambi esistono solo per comodità.
Nel backend, il kernel Linux v5.0 ha un'unica chiamata di sistema brk utilizzato per implementare entrambi:https://github.com/torvalds/linux/blob/v5.0/arch/x86/entry/syscalls/syscall_64.tbl#L23
12 common brk __x64_sys_brk
È brk POSIX?
brk era POSIX, ma è stato rimosso in POSIX 2001, quindi la necessità di _GNU_SOURCE per accedere al wrapper glibc.
La rimozione è probabilmente dovuta all'introduzione di mmap , che è un superset che consente di allocare più intervalli e più opzioni di allocazione.
Penso che non ci siano casi validi in cui dovresti usare brk invece di malloc o mmap al giorno d'oggi.
brk rispetto a malloc
brk è una vecchia possibilità di implementare malloc .
mmap è il nuovo meccanismo rigorosamente più potente che probabilmente tutti i sistemi POSIX utilizzano attualmente per implementare malloc . Ecco un mmap minimo eseguibile esempio di allocazione della memoria.
Posso mescolare brk e malloc?
Se il tuo malloc è implementato con brk , non ho idea di come ciò possa non far saltare in aria le cose, dal momento che brk gestisce solo un singolo intervallo di memoria.
Tuttavia non sono riuscito a trovare nulla al riguardo nei documenti di glibc, ad esempio:
- https://www.gnu.org/software/libc/manual/html_mono/libc.html#Resizing-the-Data-Segment
Probabilmente le cose funzioneranno lì, suppongo, dal mmap è probabilmente usato per malloc .
Vedi anche:
- Cosa c'è di non sicuro/precedente in brk/sbrk?
- Perché chiamare sbrk(0) due volte dà un valore diverso?
Ulteriori informazioni
Internamente, il kernel decide se il processo può disporre di tanta memoria e assegna pagine di memoria per tale utilizzo.
Questo spiega come lo stack si confronta con l'heap:qual è la funzione delle istruzioni push/pop utilizzate sui registri nell'assembly x86?
Nel diagramma che hai postato, la "interruzione"—l'indirizzo manipolato da brk e sbrk —è la linea tratteggiata in cima all'heap.
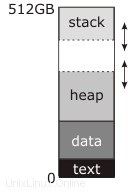
La documentazione che hai letto lo descrive come la fine del "segmento di dati" perché nelle librerie tradizionali (pre-shared-libraries, pre-mmap ) Unix il segmento di dati era continuo con l'heap; prima dell'avvio del programma, il kernel caricava i blocchi "testo" e "dati" nella RAM a partire dall'indirizzo zero (in realtà poco sopra l'indirizzo zero, in modo che il puntatore NULL non puntasse veramente a nulla) e impostava l'indirizzo di interruzione a la fine del segmento di dati. La prima chiamata a malloc userebbe quindi sbrk per spostare la separazione e creare l'heap in mezzo la parte superiore del segmento dati e il nuovo indirizzo di interruzione più alto, come mostrato nel diagramma, e il successivo utilizzo di malloc lo userebbe per rendere l'heap più grande se necessario.
Nel frattempo, lo stack inizia in cima alla memoria e cresce verso il basso. Lo stack non ha bisogno di chiamate di sistema esplicite per renderlo più grande; o inizia con tutta la RAM allocata che può mai avere (questo era l'approccio tradizionale) o c'è una regione di indirizzi riservati sotto lo stack, a cui il kernel alloca automaticamente la RAM quando nota un tentativo di scrivere lì (questo è l'approccio moderno). In ogni caso, potrebbe esserci o meno una regione di "guardia" nella parte inferiore dello spazio degli indirizzi che può essere utilizzata per lo stack. Se questa regione esiste (tutti i sistemi moderni lo fanno) è permanentemente non mappata; se uno dei due lo stack o l'heap tenta di crescere al suo interno, si ottiene un errore di segmentazione. Tradizionalmente, tuttavia, il kernel non tentava di imporre un confine; lo stack potrebbe crescere nell'heap, o l'heap potrebbe crescere nello stack, e in entrambi i casi scarabocchierebbero sui dati l'uno dell'altro e il programma andrebbe in crash. Se eri molto fortunato, si bloccava immediatamente.
Non sono sicuro da dove provenga il numero 512 GB in questo diagramma. Implica uno spazio di indirizzi virtuali a 64 bit, che è incoerente con la mappa di memoria molto semplice che hai lì. Un vero spazio di indirizzi a 64 bit è più simile a questo:

Legend: t: text, d: data, b: BSS
Questo non è in scala remota, e non dovrebbe essere interpretato esattamente come fa un dato sistema operativo (dopo averlo disegnato ho scoperto che Linux in realtà mette l'eseguibile molto più vicino all'indirizzo zero di quanto pensassi, e le librerie condivise a indirizzi sorprendentemente alti). Le regioni nere di questo diagramma non sono mappate (qualsiasi accesso provoca un segfault immediato) e sono gigantesche rispetto alle aree grigie. Le regioni grigio chiaro sono il programma e le sue librerie condivise (possono esserci dozzine di librerie condivise); ognuno ha un indipendente segmento di testo e dati (e segmento "bss", che contiene anche dati globali ma è inizializzato a tutti i bit zero anziché occupare spazio nell'eseguibile o nella libreria su disco). L'heap non è più necessariamente continuo con il segmento di dati dell'eseguibile:l'ho disegnato in questo modo, ma sembra che Linux, almeno, non lo faccia. Lo stack non è più ancorato alla parte superiore dello spazio degli indirizzi virtuali e la distanza tra l'heap e lo stack è così enorme che non devi preoccuparti di attraversarla.
L'interruzione è ancora il limite superiore dell'heap. Tuttavia, quello che non ho mostrato è che potrebbero esserci dozzine di allocazioni indipendenti di memoria là fuori da qualche parte nel buio, fatte con mmap invece di brk . (Il sistema operativo cercherà di tenerli lontani dal brk area in modo che non si scontrino.)