La parola è un metodo popolare e intelligente nei tempi moderni per interagire con i dispositivi elettronici. Come sappiamo, ci sono molti strumenti di riconoscimento vocale open source disponibili su diverse piattaforme. Dall'inizio di questa tecnologia, è stata migliorata contemporaneamente nella comprensione della voce umana. Questo è il motivo; ora ha coinvolto molti professionisti rispetto a prima. Il progresso tecnico è abbastanza forte da renderlo più chiaro alla gente comune.
Strumenti di riconoscimento vocale open source
Lo strumento di riconoscimento vocale open source non è molto disponibile come il tipico software che utilizziamo nella nostra vita quotidiana nella piattaforma Linux. Dopo un lungo percorso di ricerca, abbiamo trovato per te alcune applicazioni ben fornite con una breve descrizione. Diamo un'occhiata ai punti seguenti!
1. Kaldi
Kaldi è un tipo speciale di software di riconoscimento vocale, avviato come parte di un progetto presso la John Hopkins University. Questo toolkit viene fornito con un design estensibile e scritto in linguaggio di programmazione C++. Fornisce un ambiente flessibile e confortevole ai suoi utenti con molte estensioni per aumentare la potenza di Kaldi.
Caratteristiche degne di nota di Kaldi
- Un'applicazione di riconoscimento vocale open source gratuita e flessibile, con licenza Apache.
- Funziona su più piattaforme, tra cui GNU/Linux, BSD e Microsoft Windows.
- Fornisce supporto per installare e configurare l'applicazione sul tuo sistema.
- Oltre al sistema di riconoscimento vocale, supporta anche reti neurali profonde e trasformazioni lineari.
2. CMUSphinx
CMUS Sphinx viene fornito con un gruppo di sistemi arricchiti di funzionalità con diversi pacchetti predefiniti relativi al riconoscimento vocale. È un programma open source, sviluppato presso la Carnegie Mellon University. Otterrai questo strumento di riconoscimento indipendente dal parlante in diverse lingue, tra cui francese, inglese, tedesco, olandese e altro ancora.

Caratteristiche degne di nota di CMUSphinx
- È un sistema di riconoscimento vocale facile da usare e veloce con un'interfaccia intuitiva.
- Viene fornito con un design flessibile e un sistema efficiente, anche in piattaforme con poche risorse.
- Fornisce strumenti per l'addestramento di modelli acustici attraverso il suo pacchetto Sphinxtrain.
- Aiuta a eseguire diversi tipi di attività attraverso i suoi utili pacchetti, tra cui individuazione di parole chiave, valutazione della pronuncia, allineamento e altro.
- È uno strumento multipiattaforma che supporta sia i sistemi Windows che Linux.
3. Discorso profondo
DeepSpeech è un motore di riconoscimento vocale open source per convertire il tuo discorso in testo. È un'applicazione gratuita di Mozilla. Per eseguire il progetto DeepSearch sul tuo dispositivo, avrai bisogno di Python 3.r o successivo. Inoltre, ha bisogno di un file di estensione Git, ovvero Git Large File Storage. Viene utilizzato per la versione di file di grandi dimensioni mentre lo esegui sul tuo sistema.
Caratteristiche degne di nota di DeepSpeech
- DeepSpeech utilizza il framework TensorFlow per rendere più confortevole la trasformazione della voce.
- Supporta la GPU NVIDIA, che aiuta a eseguire un'inferenza più rapida.
- Puoi utilizzare l'inferenza DeepSearch in tre modi diversi; Il pacchetto Python, il pacchetto Node.JS o il client della riga di comando.
- Ogni volta che desideri eseguire questo software sul tuo sistema, dovrai attivare l'ambiente virtuale tramite il comando Python.
- È necessario un ambiente Linux o Mac per eseguire questa applicazione.
4. Wav2Lettera++
WavLetter++ è uno strumento di riconoscimento vocale moderno e popolare, sviluppato dal team di Facebook AI Research. È un altro programma open source con licenza BCD. Questo software di riconoscimento vocale superveloce è stato creato in C++ e introdotto con molte funzionalità. Fornisce la possibilità di modellazione del linguaggio, traduzione automatica, sintesi vocale e altro ancora ai suoi utenti in un ambiente flessibile.
Caratteristiche degne di nota di Wav2Letter++
- Contiene una community attiva su piattaforme popolari come Facebook e il gruppo Google per assistere i suoi utenti in tutto il mondo.
- WavLetter++ è un toolkit veloce e flessibile che utilizza la libreria tensoriale ArrayFire per la massima efficienza.
- Ti consente di lavorare con un framework ad alte prestazioni come wav2letter++, che aiuta a fare una ricerca e una messa a punto del modello di successo.
- Inoltre, fornisce una documentazione completa attraverso le sezioni del tutorial.
- Nella cartella delle ricette troverai le ricette dettagliate per WSJ, Timit e Librispeech.
5. Giulio
Julius è relativamente un vecchio software di riconoscimento vocale open source sviluppato da Lee Akinobu. Questo strumento è scritto nel linguaggio di programmazione C dagli sviluppatori di Kawahara Lab, Università di Kyoto. È un'applicazione di riconoscimento vocale ad alte prestazioni con un ampio vocabolario. Puoi usarlo sia in inglese che in giapponese. Può essere un'ottima scelta se si desidera utilizzarlo per scopi accademici e di ricerca.
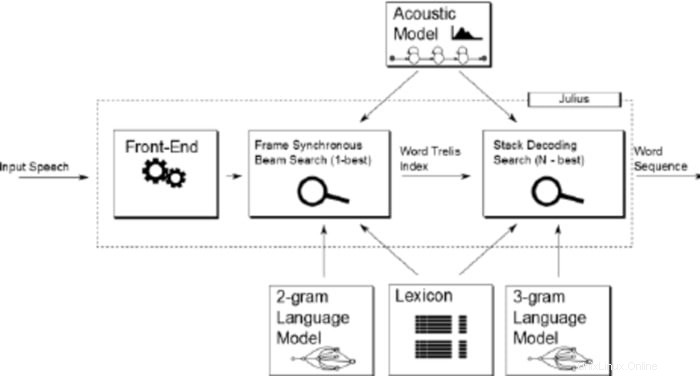
Caratteristiche degne di nota di Julius
- Julius è un'applicazione altamente configurabile che può impostare diversi parametri di ricerca per ottimizzarne le prestazioni.
- Questo strumento si basa su una strategia a 2 passaggi che fornisce prestazioni in tempo reale e di alta qualità.
- È un progetto multipiattaforma che funziona su sistemi Linux, BSD, Windows e Android.
- Integrato con Julian, un parser di riconoscimento basato sulla grammatica.
- Oltre a supportare la grammatica basata su regole, fornisce anche output grafico di Word, punteggio di affidabilità, rifiuto di input basato su GMM e molte altre funzionalità.
6. Simone
Simon viene fornito con un software di riconoscimento vocale moderno e facile da usare, sviluppato da Peter Grasch. È un altro programma open source sotto la GNU General Public License. Sei libero di usare Simon su entrambi i sistemi Linux e Windows. Inoltre, offre la flessibilità di lavorare con qualsiasi lingua desideri.
Caratteristiche degne di nota di Simon
- Utilizzando la sua calcolatrice a comando vocale, Simon offre la possibilità di eseguire varie operazioni aritmetiche.
- Compatibile con Skype e altri popolari programmi VOIP per stabilire un facile sistema di comunicazione con amici e parenti.
- Consente agli utenti di guardare presentazioni e video, ascoltare musica e altro ancora con pochi semplici comandi vocali.
- Inoltre, è uno strumento essenziale per leggere i giornali e navigare in Internet.
7. Mycroft
Mycroft viene fornito con un assistente vocale open source facile da usare per convertire la voce in testo. È considerato uno degli strumenti di riconoscimento vocale Linux più popolari nei tempi moderni, scritto in Python. Consente agli utenti di utilizzare al meglio questo strumento in un progetto scientifico o in un'applicazione software aziendale. Inoltre, può essere utilizzato come un pratico assistente, in grado di dirti l'ora, la data, il meteo e altro ancora.
Caratteristiche degne di nota di Mycroft
- Integrato con i social media e le piattaforme professionali più popolari, tra cui Facebook, Github, LinkedIn e altro ancora.
- È possibile eseguire questa applicazione su diverse piattaforme software e hardware. Può essere un desktop o un Raspberry Pi.
- Oltre ad essere un assistente vocale intelligente, fornisce la funzione di registrazione audio, apprendimento automatico, libreria software e altro ancora.
- Consente agli utenti di convertire il linguaggio naturale in dati leggibili dalla macchina tramite Adapt, un analizzatore di intenti di Mycroft.
8. OpenMindSpeech
Open Mind Speech è uno degli strumenti essenziali di riconoscimento vocale di Linux che mira a convertire gratuitamente il tuo discorso in testo. Fa parte di Open Mind Initiative, gestisce il suo funzionamento, soprattutto per gli sviluppatori. Questo programma è stato introdotto con nomi diversi come VoiceControl, SpeechInput e FreeSpeech prima di ottenere il nome attuale.
Caratteristiche degne di nota di OpenMindSpeech
- Utilizza l'ambiente Overflow nell'operazione di riconoscimento vocale per rendere flessibili le complesse applicazioni.
- Open Mind Speech è principalmente compatibile con piattaforme basate su Linux e UNIX.
- Utilizzando Internet, può raccogliere dati vocali da e-cittadini, che sono i contributori di dati grezzi.
9. Controllo vocale
Speech Control è un'applicazione di riconoscimento vocale gratuita, adatta a qualsiasi distribuzione Ubuntu. Viene fornito con un'interfaccia utente grafica basata su Qt. Anche se è ancora nella sua fase iniziale di sviluppo, puoi usarlo per il tuo semplice progetto.
Caratteristiche degne di nota di SpeechControl
- Speech Control è un programma open source sotto la General Public License (GPL).
- Ha lo scopo di funzionare come un assistente virtuale che fornisce indicazioni sulle attività ripetitive per eseguire il processo senza intoppi.
- È adatto principalmente per piattaforme basate su Linux.
- Inoltre, fornisce una documentazione per l'utente di facile comprensione con i dettagli del progetto.
10. Deepspeech.pytorch
Deepspeech.pytorch è un'altra applicazione di riconoscimento vocale open source menzionabile che è in definitiva l'implementazione di DeepSpeech2 per PyTorch. Contiene una serie di potenti reti basate sull'architettura DeepSpeech2. Con molte risorse utili, può essere utilizzato come uno degli strumenti di riconoscimento vocale Linux essenziali per la ricerca e lo sviluppo di progetti.
Caratteristiche degne di nota di Deepspeech.pytorch
- Supporta l'aumento del rumore che aiuta ad aumentare la robustezza al momento del caricamento dell'audio.
- Per inviare la richiesta di post al server, fornisce uno script server di base.
- Supporta diversi set di dati per il download, tra cui TEDLIUM, AN4, Voxforge e LibriSpeech.
- Consente di aggiungere rumore ai dati di addestramento attraverso l'iniezione di rumore.
- Supporta Visdom e Tensorboard per la visualizzazione della formazione sulla sperimentazione scientifica.
Pensieri finali
Quindi, abbiamo raggiunto il punto finale sugli strumenti di riconoscimento vocale open source per Linux. Spero che tu abbia informazioni complete su questo argomento. Le applicazioni sopra menzionate sono gratuite, facili da usare e pronte per far parte del tuo progetto accademico o personale.
Quale preferisci di più? Se hai altre scelte, non esitare a farcelo sapere. Per favore, condividi questo articolo con la tua comunità, se ti è stato utile. Fino ad allora, divertiti. Grazie!