Il data mining è il processo di analisi di grandi quantità di dati per ottenere informazioni utili. Ha applicazioni incredibilmente diverse nei campi della ricerca accademica e degli affari. I ricercatori usano il data mining per dedurre nuove soluzioni ai problemi di ricerca computazionale, mentre le aziende dipendono da esso per ottenere il sopravvento sui ricavi aziendali. Aziende come Amazon utilizzano diverse tecniche di data mining per migliorare il loro motore di raccomandazione dei prodotti, mentre i giganti della ricerca come Google e Microsoft le sfruttano per classificare i risultati dei loro motori di ricerca in modo efficace. Grazie alla crescente domanda di Data Science in generale, negli ultimi decenni è stata distribuita una pletora di robusto software di data mining per Linux. Resta con noi per saperne di più sui 20 migliori software di data mining di Linux.
Software di data mining ricco di funzionalità
Il data mining copre molti argomenti di Data Science, tra cui la raccolta di dati, l'analisi statistica, i concetti di intelligenza artificiale e, naturalmente, la programmazione. A causa del loro enorme dominio, gli strumenti di data mining sono disponibili in diversi gusti, sviluppati per eseguire cose diverse. Pertanto, i nostri esperti hanno scelto una gamma versatile di software di data mining per Linux che, utilizzati in modo creativo, possono soddisfare perfettamente le esigenze dei moderni ingegneri di dati.
1. Minatore rapido
L'apice del moderno software di data mining di Linux, Rapid Miner è molto al di sopra degli altri quando si tratta di discutere di piattaforme di data mining affidabili. Conosciuta in precedenza come YALE, è una suite di data mining potente e flessibile dotata di una notevole quantità di robuste funzionalità per migliorare le tue abilità di mining al livello successivo. Rapid Miner è sviluppato sulla base del linguaggio di programmazione Java e fa esattamente ciò che implica il suo nome:consolidare i tuoi progetti di data mining.
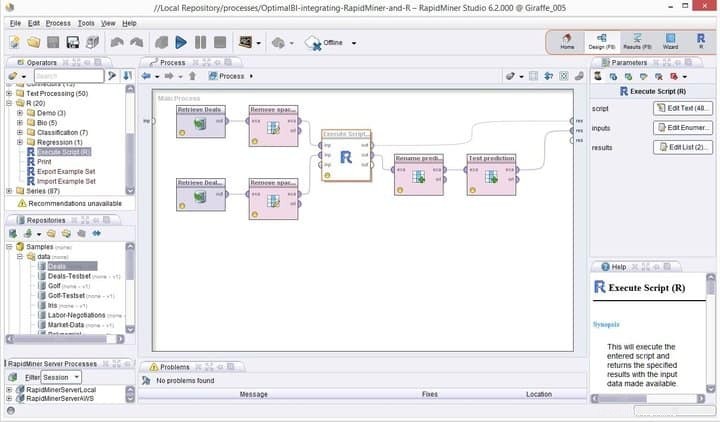
Caratteristiche di Rapid Miner
- Rapid Miner viene fornito con un'interfaccia grafica minimale ma intuitiva, con una versione a riga di comando aggiuntiva per i fanatici del terminale.
- Questo ambiente visivo robusto e flessibile per l'analisi predittiva consente agli utenti di analizzare i big data senza una programmazione esplicita.
- È disponibile un enorme elenco di estensioni flessibili, che ti consentono funzionalità aggiuntive rispetto a ciò che ottieni durante la prima installazione.
- Puoi integrare molto facilmente questo potente software di data mining per Linux in progetti di data mining personalizzati.
2. R
R potrebbe essere un nome familiare per i laureati CS con un'adeguata conoscenza della programmazione. Ma ha molto più valore per uno scienziato di dati. In breve, R è un ambiente completo per l'analisi statistica di dati e grafici. È una piattaforma di data mining altamente flessibile che offre potenti tecniche analitiche come modellazione, test statistici, analisi di serie temporali, classificazione, clustering e molti altri. Se sei un professionista con capacità di programmazione superiori, R potrebbe rivelarsi l'arma migliore del tuo arsenale.
Caratteristiche di R
- R offre una soluzione solida ed efficace per l'archiviazione e la gestione di enormi quantità di dati aziendali.
- Una pletora di strumenti di analisi dei dati integrati e coerenti garantisce che gli ingegneri possano sfruttare R per un'ampia gamma di progetti di data mining.
- È facile eseguire il debug dei problemi all'interno di progetti di data mining esistenti grazie alle solide capacità di riproduzione degli errori di R.
- R è ampiamente utilizzato per progetti di data mining su larga scala e presenta un enorme elenco di soluzioni predefinite da appassionati di open source.
3. Arancione
Se sei un data scientist con un background in CS, potresti già avere familiarità con Orange. Per il resto di voi, pensatelo come un robusto software di data mining per Linux costruito su Python. In generale, Orange offre un set flessibile e gratificante di librerie Python in grado di gestire le moderne tecniche di data mining come classificazione, modellazione, regressione, clustering insieme a strumenti per la visualizzazione e la preelaborazione dei dati.
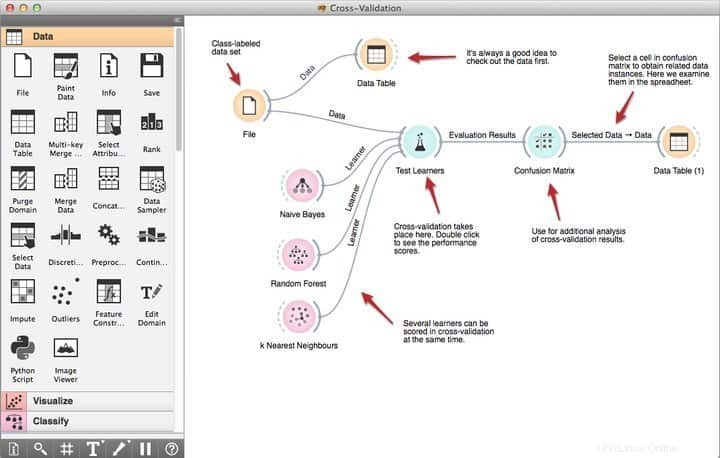
Caratteristiche di Orange
- Il suo potente strumento di programmazione visiva chiamato Orange Canvas consente ai principianti di creare soluzioni rapide di data mining utilizzando le sue capacità produttive di gestione del flusso di lavoro.
- Viene fornito con un robusto set di strumenti di visualizzazione premium per alberi decisionali, sottoinsieme di attributi, bagging, boosting e molti altri.
- Secondo i loro requisiti, Orange rientra nella licenza GNU GPL, consentendo così ai programmatori di modificare o personalizzare questo software di data mining gratuito.
- Puoi scegliere subito Orange e integrarlo con i tuoi progetti di data mining esistenti per ottenere funzionalità aggiuntive, tra cui oltre 100 widget predefiniti.
4. MOA
MOA, abbreviazione di Massive Online Analysis, fa esattamente quello che dice il suo nome. È un innovativo software di data mining per Linux con un'enfasi primaria sull'estrazione di flussi di dati di grandi dimensioni. MOA mira a dotare gli aspiranti data scientist di una piattaforma di data mining potente ma flessibile che consentirà loro di testare efficacemente vari algoritmi di data mining su flussi di dati in continua evoluzione. MOA viene fornito con una solida raccolta di metodi di apprendimento automatico standard, tra cui classificazione, regressione, clustering, rilevamento di valori anomali e sistemi di raccomandazione.
Caratteristiche di MOA
- MOA offre tre diverse opzioni di interfaccia, tra cui un'interfaccia GUI, una basata su console e un'API flessibile basata su Java per l'integrazione online.
- Confeziona algoritmi di rilevamento delle modifiche flessibili per determinare quante più informazioni possibili dai flussi di dati in tempo reale.
- Questo software di data mining open source è adatto a coloro che desiderano sfruttare i dati in tempo reale per i propri processi di mining.
- MOA dispone di una licenza GNU GPL open source e quindi non richiede formalità legali per la personalizzazione o la modifica.
5. RADICE
Puoi fare affidamento su una piattaforma di data mining sviluppata dal CERN, vero? ROOT è un software di data mining Linux immensamente potente per risolvere le sfide del mondo reale che coinvolgono enormi quantità di dati fisici ad alta energia. Ben presto ha guadagnato popolarità tra i data scientist che lavorano in diverse aree ed è attualmente ampiamente utilizzato per il data mining e l'analisi dei dati astronomici. Se sei un laureato in scienze con un profondo interesse per la fisica delle particelle, questa è la vera piattaforma per te.
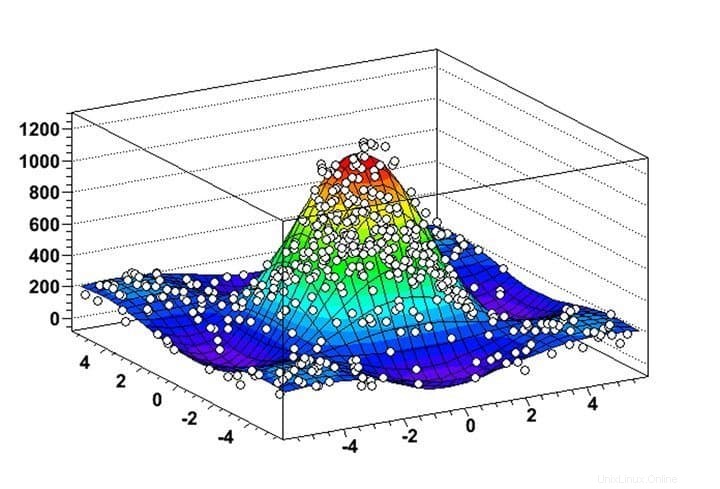
Caratteristiche di ROOT
- ROOT consente una visualizzazione estremamente utile delle distribuzioni dei dati e degli algoritmi di mining attraverso le sue funzionalità di istogrammi e grafici altamente flessibili.
- Puoi analizzare oggetti 2D come linee, poligoni, frecce, grafici e istogrammi insieme a oggetti grafici 3D in questo software di data mining per Linux.
- ROOT fornisce diversi strumenti computazionali a quattro vettori e capacità di manipolazione delle immagini per l'analisi pratica di set di dati del mondo reale.
- Il software è scritto principalmente in C++ ma utilizza Python e R per massimizzare le sue funzionalità di data mining.
6. DataMelt
Uno dei migliori software di data mining Linux per ricercatori e ingegneri, DataMelt offre un set completo di funzionalità potenti ma flessibili per l'analisi di grandi set di dati. È senza dubbio tra le piattaforme di data mining più convenienti per i principianti che non vedono l'ora di dare impulso alla loro carriera nel campo della scienza dei dati. Precedentemente noto come SCaVis, questo enigmatico software di data mining unisce enormi pacchetti software open source in un'interfaccia coerente.
Caratteristiche di DataMelt
- DataMelt implementa una parte sostanziale dei suoi strumenti di manipolazione e tracciamento dei dati in Java e utilizza Jython per scopi di scripting.
- Potenti macro Python sono state utilizzate per consentire ai data scientist di visualizzare dati, istogrammi e strutture 3D del mondo reale.
- L'ambiente di sviluppo integrato (IDE) integrato utilizza librerie JAIDA FreeHEP flessibili e consente l'evidenziazione della sintassi, il completamento del codice, l'analizzatore di programmi e una shell Jython.
- La licenza open source di questo software di data mining per Linux consente ai data scientist di estendere il software secondo necessità.
7. Sonaglio
Rattle (lo strumento analitico R per imparare facilmente) è un software di data mining gratuito che fornisce una potente interfaccia alle funzionalità di data mining e classificazione binaria di R. Fornisce inoltre una pratica suite di business intelligence nota come RStat per aziende e professionisti di data scientist. Rattle consente agli utenti di importare set di dati da file CSV o ODBC ed esplorarli per modellare le proprie soluzioni di data mining.
Caratteristiche di Rattle
- Rattle consente ai data scientist di sviluppare e analizzare modelli di dati complessi ed esportarli come PMML (predictive modeling markup language) o come punteggi.
- È un software di data mining Linux completo che può essere facilmente utilizzato per il data mining su larga scala da aziende, governi e istituti di ricerca.
- I dati possono essere caricati da un vasto numero di fonti, inclusi file CSV, TXT, Excel, ARFF, ODBC e RData, oltre a Corpus e Script.
- Le tecniche di apprendimento automatico offerte da questa piattaforma di data mining includono alberi decisionali, foreste casuali, macchine vettoriali di supporto, regressione logistica, rete neurale e altro.
8. ELKI
ELKI è un software di data mining Linux immensamente potente scritto nel linguaggio di programmazione Java. Ha lo scopo di rendere il data mining accessibile alle persone che non sono in possesso di certificazioni professionali di data science. È una delle piattaforme di data mining più utilizzate nelle fondazioni di ricerca e insegnamento grazie alla sua impressionante raccolta di solide funzionalità di data mining. ELKI viene fornito con il supporto integrato per quasi tutti gli algoritmi di data mining più diffusi, inclusi clustering, classificazione, gestione degli indici di database e rilevamento dei valori anomali.
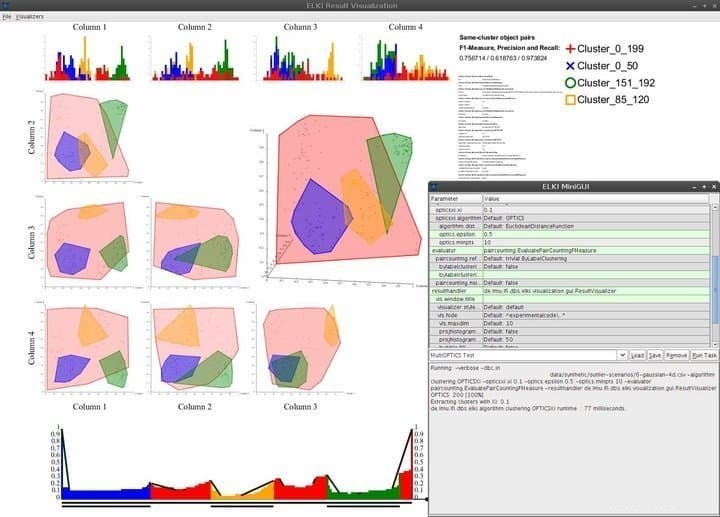
Caratteristiche di ELKI
- ELKI è dotato di un'interfaccia utente minimale ma elegante che fornisce solo le capacità di navigazione necessarie richieste.
- Le capacità di visualizzazione includono, a titolo esemplificativo ma non esaustivo, istogrammi, curve ROC, grafici OPTICS, coordinate parallele, celle Voronoi, forme alfa e altro ancora.
- ELKI impiega diverse strategie di suddivisione R-tree e di caricamento in blocco per strutturare efficacemente gli indici.
- Questo software di data mining per Linux consente ai data scientist di esplorare e valutare i dati geografici utilizzando solide funzionalità di rilevamento degli outlier spaziali.
9. KNIME
KNIME è senza dubbio uno dei software di data mining open source più innovativi su cui potremmo mettere le mani. Fornisce una piattaforma di data mining molto completa e flessibile, che vanta funzionalità coerenti per attività di integrazione, elaborazione, analisi, reporting e valutazione dei dati. KNIME consente la creazione di flussi di lavoro visivi chiamati pipeline per consentire ai data scientist di indagare su complessi set di dati in tempo reale. Il software stesso è altamente scalabile e può essere integrato in progetti futuri senza alcun ostacolo.
Caratteristiche di KNIME
- L'interfaccia grafica di questo software di data mining gratuito è molto intuitiva e comprende le capacità di navigazione specifiche richieste nel data mining moderno.
- KNIME si trova in cima all'ambiente di sviluppo interattivo Eclipse e sfrutta le sue robuste API per garantire l'estensibilità agli appassionati di open source.
- Viene fornita una comoda interfaccia utente basata su console per consentire l'esecuzione in batch tramite script automatizzati.
- KNIME supporta un'ampia gamma di tecniche di data mining, tra cui clustering, induzione di regole, regole di associazione, reti bayesiane, reti neurali e molte altre.
10. Weka
Weka, abbreviazione di Waikato Environment for Knowledge Analysis, è un avvincente software di data mining per Linux. Offre un ampio set di software di apprendimento automatico scritto in Java, inclusi algoritmi per tecniche di data mining convenzionali come alberi decisionali, macchine vettoriali di supporto, classificatori basati su istanze, clustering, reti di Bayes, reti neurali e molti altri. Weka è dotato di funzionalità di integrazione bidirezionale con MOA e quindi può essere ampiamente utilizzato in aree in cui l'elaborazione di flussi di dati in tempo reale è obbligatoria.
Caratteristiche di Weka
- Le potenti capacità di visualizzazione ed elaborazione dei dati di Weka rendono la valutazione di set di dati su larga scala molto più semplice rispetto alla maggior parte dei software di data mining gratuiti.
- L'interfaccia utente grafica (GUI) integrata è molto intuitiva e rende l'applicazione degli algoritmi di apprendimento automatico relativamente comoda.
- The flexible API makes embedding Weka into existing or future data mining projects completely hassle-free.
- Weka’s robust environment allows rewarding data preprocessing abilities to make the most out of industrial or research data.
11. KEEL
KEEL stands for Knowledge Extraction based on Evolutionary Learning, and as the name implies, it is a Linux data mining software for assessing evolutionary algorithms. It is a powerful data mining platform that provides advanced functionalities to help engineers bring new data mining solutions while providing researchers with a mesmerizing platform for scientific undertakings. KEEL is written using the powerful interpreted programming language Java and ships with an open-source GNU GPL license.
Features of KEEL
- The user interface of KEEL is simple in visual, yet it provides all the navigational power required to manage the software effectively.
- It comes with a pre-built set of extensive evolutionary algorithms to predict models, preprocessing methods, and postprocessing procedures.
- KEEL offers over 100 different algorithms for data transformation, discretization, feature selection, noise filtering, and many more.
- It’s among those few data mining software for Linux that comes with extremely accurate data reduction methodologies, alongside functions for extracting rules based on patterns.
12. Apache Mahout
Apache Mahout is one of the most used data mining platforms by professional data scientists due to its substantial empowering features. It is primarily an open source collection of frequently used machine learning techniques and their implementations to help cluster, classify, and frequent pattern recognition in large-scale datasets. Many notable tech giants leverage Apache Mahout for real-time data mining, including Adobe, AOL, Drupal, and Twitter, due to the flexibility it offers.
Features of Apache Mahout
- This data mining software for Linux integrates to the Apache Hadoop stack very well, thus offering an excellent platform for people looking for distributed data mining solutions.
- Data scientists can leverage Mahout on top of Apache Spark as the back-end for implementing flexible and highly scalable data mining projects.
- Mahout comes with native support for CPU/GPU/CUDA acceleration, thus allowing you to leverage the maximum processing power you could get.
13. Sisense
Sisense is arguably among the best data mining software for Linux beginners. It provides data scientists with the specific features they require for diving into massive datasets and discover crucial insights like customer’s shopping habits, search rankings, and other business analytics. Sisense offers a compelling dashboard, making it reasonably straightforward to explore and visualize large amounts of unprocessed data. If you’re coming into data mining from a non-technical background, Sisense might be the best data mining platform for you.
Features of Sisense
- Sisense allows data science professionals to connect with any number of data sources – both structured and unstructured.
- The user interface is very intuitive, and the dashboard provides a highly interactive workflow for visualizing large-scale disparate data sources.
- Sisense can be readily employed in enterprises, government institutions, healthcare management, supply chains, manufacturing, and other types of corporations.
- Sisense allows for a handy drag-and-drop feature empowering data scientists in managing their projects with superior productivity.
14. Databionic
The Databionic ESOM tools offer a plethora of rewarding and flexible data mining techniques such as clustering, visualization, and classification with Emergent Self-Organizing Maps (ESOM) that enable data scientists to analyze large-scale data for business analytics. Developed in Germany, Databionic provides almost every necessary functionalities you’d look for in a modern-day Linux data mining software. It comes under a free and open source GNU GPL license and encourages professionals to tweak the software as they see fit.
Features of Databionic
- This data mining software for Linux is written using the Java programming language and offers maximum portability and extensibility.
- A compelling set of pre-built initialization methods and training algorithms are shipped with Databionic to ease your data mining projects.
- Databionic enables you to effectively visualize high-dimensional and disparate datasets with U-Matrix, P-Matrix, Component Planes, and SDH.
- Users can quickly build personalized ESOM classifiers for automating their data mining tasks with Databionic.
15. Anaconda
Anaconda is an extremely innovative, powerful, and open source data mining software powered by Python, the holy grail of data science programming languages. Industry leaders, including CISCO, Bloomberg, and BMW, utilize this awe-inspiring data mining platform to stay on top of their fellow competitors and curate new analytics solutions. Anaconda is often a mandatory requirement for companies hiring data scientists due to its extensive usage in the field.
Features of Anaconda
- Anaconda allows data scientists to harness the might of data science, machine learning, and AI – all from a single platform and deploy projects with a single click of the mouse.
- This free data mining software comes with an extensive set of pre-built data science packages for Python, R, and Scala.
- Anaconda ships with a BSD license, allowing developers to leverage it to build robust data mining solutions without any legal hassle.
- It is relatively simple to integrate this modern-day data mining software for Linux with other data science software in your arsenal.
16. Shogun
Shogun is, as the developers call it – a unified and efficient machine learning library aimed at solving real-world problems involving big data, and of course – data mining. It is one of the best data mining software for Linux that provides top-notch functionalities and makes sure they can be leveraged as the users want them to. If you’re looking for robust open source data mining software, Shogun might be the perfect tool for you.
Features of Shogun
- Shogun features an extensive range of data mining features, including but not limited to classification, regression, dimensionality reduction, support vector machines, and such.
- It offers a full-fledged implementation of powerful hidden Markov models for enhancing your data mining capabilities right out of the box.
- The user interface is fully hackable and can integrate with futuristic projects too well, thanks to its robust APIs.
- Shogun performs relatively much better than regular Linux data mining software, owing to its gratitude to C++.
17. GNU Octave
GNU Octave is an extremely powerful yet user-friendly scientific computing solution that features a robust high-level programming language similar to MATLAB in many ways. It has widespread usage in the areas of numerical computing and syncs perfectly with most MATLAB implementations. Data scientists can leverage this mesmerizing data science platform for analyzing diverse ranges of real-time data and dig out potentially rewarding insights from them.
Features of GNU Octave
- GNU Octave aims primarily at solving linear and nonlinear numerical problems and runs seamlessly on Linux, macOS, BSD, and Windows.
- The syntax of its high-level programming language is very identical to MATLAB and can operate on both vectors and matrices.
- The powerful mathematics-oriented data visualization capabilities of this Linux data mining software helps in analyzing large amounts of data without requiring external tools.
- The software comes with a GUI interface and a command-line variant for enhancing productivity to the highest level.
18. Apache UIMA
Apache UIMA is highly modular informatics management and analysis system that has gained immense popularity among data scientists due to its compelling data mining functionalities. UIMA stands for Unstructured Information Management Architecture and, as the name already suggests, is an analytic tool for exploring unstructured data. This data mining software for Linux provides a select set of flexible features to discover useful insights from large volumes of disparate data.
Features of Apache UIMA
- It is a Java-based data mining framework for analyzing and evaluating massive datasets involving real-time unstructured data.
- UIMA is hugely scalable and can be used as network services and processing pipelines.
- This Linux data mining software facilitates the analysis of multimedia contents such as audio and video data.
- The software suite comes under an Apache license and is thus free to use and modify by users.
19. Turi Create
Turi is arguably among the most excellent data mining software for Linux we’ve tested during our compilation of this guide. Known previously as Graphlab Create, Turi offers a plethora of robust data science functionalities to build highly modular, scalable data mining solutions. Turi boasts a wide range of diverse, high-performance, distributed computation features and can greatly simplify the development of custom data-mining programs.
Features of Turi Create
- This Linux data mining software is based on graphs and focuses more on tasks than algorithms.
- Although the software doesn’t require any external graphic processing unit (GPU), using one can significantly boost performance.
- Apart from standard text and image data, Turi has built-in support for audio, video, and sensor data.
- It is written using the C++ programming language and is one of the fastest data mining software we’ve tested.
20. ROSETTA
Marketed by the devs as a rough set toolkit for analysis of data, ROSETTA is a general-purpose tool for discernibility-based modeling, with very compelling use cases in the field of data mining. It is a powerful framework for analyzing tabular data and offers some very robust knowledge discovery functionalities. You can utilize ROSETTA in preprocessing large-scale datasets, computing attribute sets, generating rules, and many more.
Features of ROSETTA
- This data mining software for Linux comes with an incredibly intuitive GUI interface with very productive navigational abilities in place.
- Users can integrate this data mining platform with database management systems (DBMSs) via ODBC relatively easily.
- ROSETTA comes with in-built support for both unsupervised and supervised machine learning models.
- The robust set of advanced filtering methods make postprocessing reasonably simple.
Ending Thoughts
Due to its diverse application in real life, data mining software for Linux tends to vary in flavor and functionality. Some of the most popular data mining tools include Rapid Miner, R, Orange, ELKI, MOA, Weka, ROOT, and DataMelt. So, when selecting the right Linux data mining software, you’ve to choose programs that meet your requirements. Hopefully, we could provide you the essential insights on some of the most widely used data mining tools. You should now be able to select the one that does the job for you perfectly. Thanks for your patience, and don’t forget to check us out for regular posts on exciting Linux software and tutorials.