Domanda :Ho un file sul mio sistema Linux con molte righe. Come faccio a contare il numero totale di righe nel file?
Utilizzo di "wc -l"
Esistono diversi modi per contare le righe in un file. Ma uno dei modi più semplici e ampiamente utilizzati è usare "wc -l". L'utilità wc visualizza il numero di righe, parole e byte contenuti in ciascun file di input o input standard (se non viene specificato alcun file) nell'output standard.
La sintassi è:
# wc -l [filename]
Quindi considera il file mostrato di seguito:
$ cat file01.txt this is a sample file with some sample data
1. Il comando "wc -l" quando viene eseguito su questo file, restituisce il conteggio delle righe insieme al nome del file.
$ wc -l file01.txt
5 file01.txt 2. Per omettere il nome del file dal risultato, utilizzare:
$ wc -l < file01.txt
5 3. È sempre possibile fornire l'output del comando al comando wc utilizzando pipe. Ad esempio:
$ cat file01.txt | wc -l
5 Puoi avere qualsiasi comando qui invece di cat. L'output di qualsiasi comando può essere reindirizzato al comando wc per contare le righe nell'output.
Utilizzo di awk
Se vuoi usare awk per trovare il conteggio delle righe, usa il comando awk di seguito:
$ awk 'END{print NR}' [filename] Esempio di output:
$ awk 'END{print NR}' file01.txt
5 Utilizzo di sed
Usa la seguente sintassi del comando sed per trovare il conteggio delle righe usando GNU sed:
$ sed -n '$=' [filename]
Esempio di output:
$ sed -n '$=' file01.txt 5
Utilizzo di grep
Il nostro buon vecchio amico "grep" può anche essere usato per contare il numero di righe in un file. Questi esempi servono solo per farti sapere che ci sono diversi modi per contare le righe senza usare "wc -l". Ma se richiesto userò sempre "wc -l" invece di queste opzioni poiché è troppo facile da ricordare.
$ grep -c ".*" [filename]
Esempio di output:
$ grep -c ".*" file01.txt 5
Con GNU grep, puoi usare la seguente sintassi grep:
$ grep -Hc ".*" [filename]
Ecco un'altra versione del comando grep per trovare il conteggio delle righe.
$ grep -c ^ file01.txt 5
Esempio di output:
$ grep -Hc ".*" file01.txt file01.txt:5
Altri comandi
Insieme ai comandi precedenti, è utile conoscere alcuni comandi usati raramente per trovare il conteggio delle righe in un file.
1. Utilizzare il comando nl (filtro di numerazione delle righe) per ottenere la numerazione di ciascuna riga. La sintassi del comando è:
$ nl [filename]
Esempio di output:
$ nl file01.txt
1 this is a sample
2 file
3 with
4 some sample
5 data Un modo non così diretto per ottenere il conteggio delle righe. Ma puoi usare awk o sed per ottenere il conteggio dall'ultima riga. Ad esempio:
$ nl file01.txt | tail -1 | awk '{print $1}'
5 2. Puoi anche usare vi e vim con il comando ":set number" per impostare il numero su ciascuna riga come mostrato di seguito. Se il file è molto grande, puoi usare "Shift+G" per andare all'ultima riga e ottenere il conteggio delle righe.
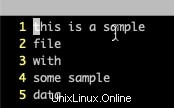
3. Usa il comando cat con -n passare per ottenere ogni riga numerata. Ancora una volta, qui puoi ottenere il conteggio delle righe dall'ultima riga.
$ cat -n file01.txt
1 this is a sample
2 file
3 with
4 some sample
5 data $ cat -n file01.txt | tail -1 | awk '{print $1}'
5 4. Puoi anche usare perl one lines per trovare il numero di righe:
$ perl -lne 'END { print $. }' file01.txt
5