Al sistema operativo Linux piace vantarsi della propria potenza di calcolo e abilità. Il suo approccio algoritmico a cose come l'elaborazione dei file, specialmente nell'ambito della gestione dei file, produce importanti pietre miliari per gli utenti Linux che cercano di padroneggiare le impronte dell'amministrazione Linux.
Un aspetto dell'elaborazione dei file nell'ambiente del sistema operativo Linux che dobbiamo considerare molto è l'identificazione delle righe più lunghe all'interno di un file modificabile supportato da Linux.
Implicazione pratica di linee lunghe in un file
Considera lo scenario in cui lavori in un'azienda o hai a che fare con un progetto che elabora enormi file di registro. Questi file potrebbero essere visualizzati come singole righe di testo quando in realtà possono incapsulare migliaia di documenti JSON.
Se la dimensione di queste righe di testo è molto/insolitamente lunga, potrebbe essere necessario elaborarle tramite un server proxy per reindirizzare correttamente i file a un server di destinazione come un server di ricerca elastico.
Tuttavia, passaggi così attenti all'elaborazione dei file potrebbero portare a errori di elaborazione dei file non intenzionali quando in realtà hai solo a che fare con righe molto lunghe nei tuoi file. Diagnosticare un tale errore è impossibile senza conoscere la minaccia in gioco.
Questo tutorial seguirà i passaggi necessari per identificare le righe più lunghe all'interno di un file di destinazione in un ambiente con sistema operativo Linux.
Dichiarazione del problema
Per rendere questo articolo più divertente e coinvolgente, creeremo un file di testo di riferimento con diverse righe variabili e in seguito implementeremo soluzioni Linux valide per scoprire le righe più lunghe.
$ sudo nano sample_file.txt
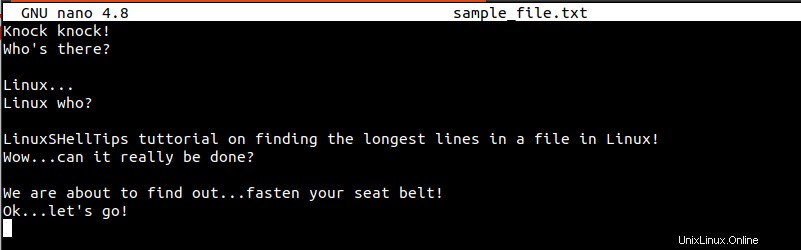
Cercheremo di identificare le righe più lunghe nel file sopra (sample_file.txt ) tramite utili comandi Linux.
1. Trova la riga più lunga in un file usando il comando Awk
Idealmente, potremmo anteporre tutte le righe nel file precedente utilizzando un awk di una riga comando per determinare le loro lunghezze esatte come mostrato di seguito.
$ awk '{printf "%2d| %s\n",length,$0}' sample_file.txt
Secondo l'acquisizione dello schermo sopra, 73 è la lunghezza della linea maggiore.
Stampa la riga più lunga in un file utilizzando i comandi wc e grep
Combinando questi due comandi, puoi usare regex dal comando grep e max-line-length dal comando wc. Il WC il comando accetta -L opzione di comando per determinare la lunghezza massima della riga come mostrato di seguito.
$ grep -E "^.{$(tr '\t' ' ' Il comando precedente dovrebbe stampare le righe più lunghe sul file file_campione.txt .

Poiché avevamo due linee identiche con la lunghezza massima di 73 , il comando precedente ha stampato i due Linee. Se fosse solo una riga con la lunghezza di riga maggiore di 73, verrebbe stampata solo quella riga.
Ora siamo a nostro agio nel trovare le righe più lunghe in un file in Linux.