Per lavorare con successo con l'editor sed di Linux e il comando awk negli script della shell, devi comprendere le espressioni regolari o in breve regex. Poiché ci sono molti motori per regex, useremo la shell regex e vedremo la potenza bash nel lavorare con regex.
Innanzitutto, dobbiamo capire cos'è la regex; poi vedremo come usarlo.
Cos'è l'espressione regolare
Per alcune persone, quando vedono le espressioni regolari per la prima volta, hanno detto cosa sono questi vomiti ASCII!!
Bene, un'espressione regolare o regex, in generale, è un modello di testo che definisci che un programma Linux come sed o awk lo usa per filtrare il testo.
Abbiamo visto alcuni di questi schemi durante l'introduzione dei comandi Linux di base e abbiamo visto come il comando ls utilizza i caratteri jolly per filtrare l'output.
Tipi di regex
Molte applicazioni diverse utilizzano diversi tipi di regex in Linux, come l'espressione regolare inclusa nei linguaggi di programmazione (Java, Perl, Python) e programmi Linux come (sed, awk, grep,) e molte altre applicazioni.
Un modello regex utilizza un motore di espressioni regolari che traduce tali modelli.
Linux ha due motori di espressioni regolari:
- L'espressione regolare di base (BRE) motore.
- L'Espressione regolare estesa (ERE) motore.
La maggior parte dei programmi Linux funziona bene con le specifiche del motore BRE, ma alcuni strumenti come sed comprendono alcune delle regole del motore BRE.
Il motore POSIX ERE viene fornito con alcuni linguaggi di programmazione. Fornisce più modelli, come la corrispondenza di cifre e parole. Il comando awk usa il motore ERE per elaborare i suoi modelli di espressioni regolari.
Poiché ci sono molte implementazioni di espressioni regolari, è difficile scrivere modelli che funzionino su tutti i motori. Quindi, ci concentreremo sulla regex più comune e dimostreremo come usarla in sed e awk.
Definisci modelli BRE
Puoi definire un modello per abbinare il testo in questo modo:
$ echo "Testing regex using sed" | sed -n '/regex/p'
$ echo "Testing regex using awk" | awk '/regex/{print $0}'

Potresti notare che alla regex non importa dove si verifica il pattern o quante volte nel flusso di dati.
La prima regola da sapere è che i modelli di espressioni regolari fanno distinzione tra maiuscole e minuscole.
$ echo "Welcome to LikeGeeks" | awk '/Geeks/{print $0}' $ echo "Welcome to Likegeeks" | awk '/Geeks/{print $0}'

La prima regex riesce perché la parola "Geeks" esiste in maiuscolo, mentre la seconda riga ha esito negativo perché utilizza lettere minuscole.
Puoi usare spazi o numeri nel tuo schema in questo modo:
$ echo "Testing regex 2 again" | awk '/regex 2/{print $0}'

Caratteri speciali
i modelli regex utilizzano alcuni caratteri speciali. E non puoi includerli nei tuoi schemi e, se lo fai, non otterrai il risultato atteso.
Questi caratteri speciali sono riconosciuti da regex:
.*[]^${}\+?|() È necessario eseguire l'escape di questi caratteri speciali utilizzando il carattere barra rovesciata (\).
Ad esempio, se vuoi abbinare un simbolo del dollaro ($), esegui l'escape con un carattere barra rovesciata come questo:
$ cat myfile There is 10$ on my pocket
$ awk '/\$/{print $0}' myfile
Se devi far corrispondere la barra rovesciata (\) stessa, devi eseguirne l'escape in questo modo:
$ echo "\ is a special character" | awk '/\\/{print $0}'

Sebbene la barra in avanti non sia un carattere speciale, viene comunque visualizzato un errore se lo usi direttamente.
$ echo "3 / 2" | awk '///{print $0}'

Quindi devi scappare in questo modo:
$ echo "3 / 2" | awk '/\//{print $0}'

Ancora personaggi
Per individuare l'inizio di una riga in un testo, utilizzare il carattere di accento circonflesso (^).
Puoi usarlo in questo modo:
$ echo "welcome to likegeeks website" | awk '/^likegeeks/{print $0}' $ echo "likegeeks website" | awk '/^likegeeks/{print $0}'

Il carattere di accento circonflesso (^) corrisponde all'inizio del testo:
$ awk '/^this/{print $0}' myfile

E se lo usi a metà del testo?
$ echo "This ^ caret is printed as it is" | sed -n '/s ^/p'

Viene stampato come se fosse un carattere normale.
Quando usi awk, devi evitarlo in questo modo:
$ echo "This ^ is a test" | awk '/s \^/{print $0}'

Si tratta di guardare l'inizio del testo, e di guardare la fine?
Il simbolo del dollaro ($) controlla la fine di una riga:
$ echo "Testing regex again" | awk '/again$/{print $0}'

Puoi utilizzare sia il segno di accento circonflesso che il segno del dollaro sulla stessa riga in questo modo:
$ cat myfile this is a test This is another test And this is one more
$ awk '/^this is a test$/{print $0}' myfile
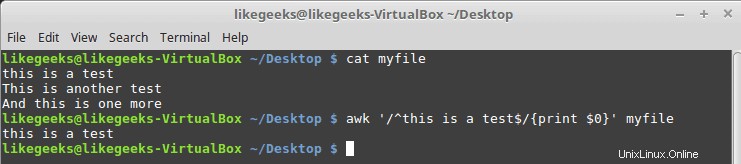
Come puoi vedere, stampa solo la linea che ha lo schema corrispondente.
Puoi filtrare le righe vuote con il seguente schema:
$ awk '!/^$/{print $0}' myfile Qui introduciamo la negazione che puoi fare con il punto esclamativo!
Il modello cerca righe vuote in cui nulla tra l'inizio e la fine della riga e nega che per stampare solo le righe abbiano testo.
Il carattere punto
Usiamo il carattere punto per trovare una corrispondenza con qualsiasi carattere eccetto la nuova riga (\n).
Guarda il seguente esempio per farti un'idea:
$ cat myfile this is a test This is another test And this is one more start with this
$ awk '/.st/{print $0}' myfile
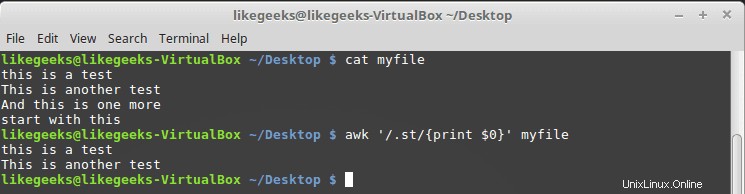
Puoi vedere dal risultato che stampa solo le prime due righe perché contengono il motivo m mentre la terza riga non ha quel motivo e la quarta riga inizia con m, quindi anche questo non corrisponde al nostro motivo.
Classi di personaggi
Puoi abbinare qualsiasi carattere con il carattere speciale punto, ma se abbini solo un set di caratteri, puoi utilizzare una classe di caratteri.
La classe di caratteri corrisponde a un insieme di caratteri se ne trova uno, il modello corrisponde.
Possiamo definire le classi di caratteri usando parentesi quadre [] in questo modo:
$ awk '/[oi]th/{print $0}' myfile
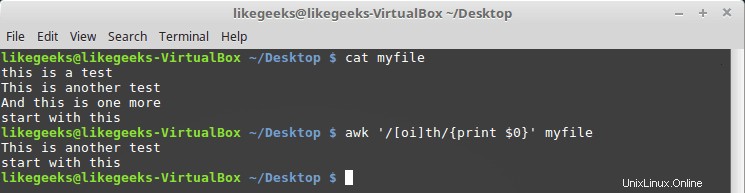
Qui cerchiamo tutti i caratteri che hanno o carattere o i prima di esso.
Questo è utile quando cerchi parole che possono contenere maiuscole o minuscole e non ne sei sicuro.
$ echo "testing regex" | awk '/[Tt]esting regex/{print $0}' $ echo "Testing regex" | awk '/[Tt]esting regex/{print $0}'

Naturalmente, non si limita ai personaggi; puoi usare i numeri o quello che vuoi. Puoi utilizzarlo come vuoi purché tu abbia l'idea.
Negazione delle classi di caratteri
Che ne dici di cercare un personaggio che non è nella classe del personaggio?
Per ottenere ciò, fai precedere l'intervallo di classi di caratteri con un accento circonflesso come questo:
$ awk '/[^oi]th/{print $0}' myfile
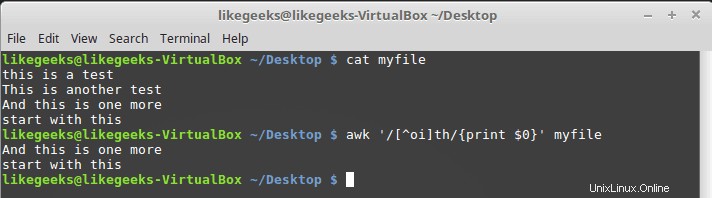
Quindi tutto è accettabile tranne o e i.
Utilizzo degli intervalli
Per specificare un intervallo di caratteri, puoi utilizzare il simbolo (-) in questo modo:
$ awk '/[e-p]st/{print $0}' myfile
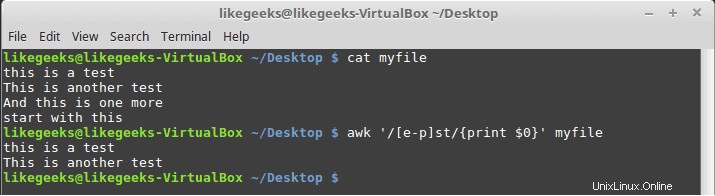
Corrisponde a tutti i caratteri compresi tra e e p quindi seguiti da st come mostrato.
Puoi anche utilizzare gli intervalli per i numeri:
$ echo "123" | awk '/[0-9][0-9][0-9]/'
$ echo "12a" | awk '/[0-9][0-9][0-9]/'

Puoi utilizzare intervalli multipli e separati come questo:
$ awk '/[a-fm-z]st/{print $0}' myfile
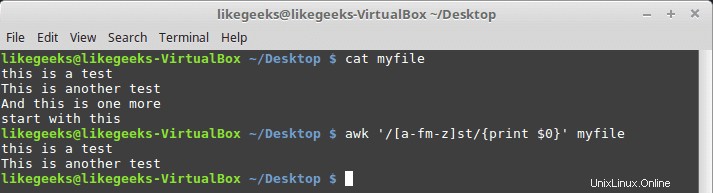
Il motivo qui significa da a a f e da m a z devono apparire prima del testo st.
Classi di caratteri speciali
L'elenco seguente include le classi di caratteri speciali che puoi utilizzare:
| [[:alnum:]] | Motivo per 0–9, A–Z o a–z. |
| [[:vuoto:]] | Modello per spazio o solo tabulazione. |
| [[:cifra:]] | Modello da 0 a 9. |
| [[:inferiore:]] | Solo motivo per a–z minuscolo. |
| [[:stampa:]] | Modello per qualsiasi carattere stampabile. |
| [[:punct:]] | Modello per qualsiasi carattere di punteggiatura. |
| [[:spazio:]] | Modello per qualsiasi carattere di spazio vuoto:spazio, Tab, NL, FF, VT, CR. |
| [[:superiore:]] | Solo motivo per lettere maiuscole dalla A alla Z. |
Puoi usarli in questo modo:
$ echo "abc" | awk '/[[:alpha:]]/{print $0}' $ echo "abc" | awk '/[[:digit:]]/{print $0}' $ echo "abc123" | awk '/[[:digit:]]/{print $0}'

L'asterisco
L'asterisco significa che il carattere deve esistere zero o più volte.
$ echo "tessst" | awk '/tes*t/{print $0}' $ echo "tessst" | awk '/tes*t/{print $0}'

Questo simbolo del modello è utile per controllare errori di ortografia o variazioni di lingua.
$ echo "I like green color" | awk '/colou*r/{print $0}' $ echo "I like green color" | awk '/colou*r/{print $0}'

Qui in questi esempi, indipendentemente dal fatto che lo digiti colore o colore corrisponderà, perché l'asterisco significa se il carattere "u" esisteva molte volte o zero volte corrisponderà.
Per abbinare qualsiasi numero di qualsiasi carattere, puoi utilizzare il punto con l'asterisco così:
$ awk '/this.*test/{print $0}' myfile
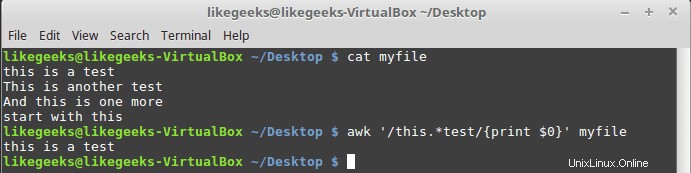
Non importa quante parole tra le parole "questo" e "test", verranno stampate eventuali corrispondenze di riga.
Puoi usare il carattere asterisco con la classe del carattere.
$ echo "st" | awk '/s[ae]*t/{print $0}' $ echo "sat" | awk '/s[ae]*t/{print $0}' $ echo "set" | awk '/s[ae]*t/{print $0}'
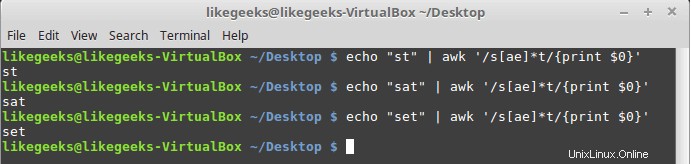
Tutti e tre gli esempi corrispondono perché l'asterisco significa che se trovi zero volte o più qualsiasi carattere "a" o "e" lo stampi.
Espressioni regolari estese
Di seguito sono riportati alcuni dei pattern che appartengono a Posix ERE:
Il punto interrogativo
Il punto interrogativo significa che il carattere precedente può esistere una volta o nessuno.
$ echo "tet" | awk '/tes?t/{print $0}' $ echo "tesst" | awk '/tes?t/{print $0}' $ echo "tesst" | awk '/tes?t/{print $0}'
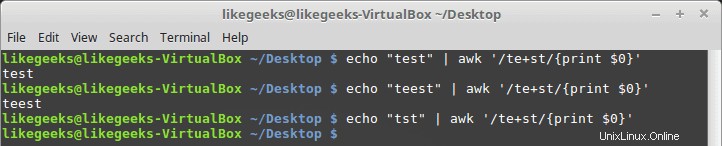
Possiamo usare il punto interrogativo in combinazione con una classe di caratteri:
$ echo "tst" | awk '/t[ae]?st/{print $0}' $ echo "test" | awk '/t[ae]?st/{print $0}' $ echo "tast" | awk '/t[ae]?st/{print $0}' $ echo "tast" | awk '/t[ae]?st/{print $0}' $ echo "teest" | awk '/t[ae]?st/{print $0}'
Se esiste uno qualsiasi degli elementi della classe di caratteri, la corrispondenza del modello passa. In caso contrario, il pattern fallirà.
Il segno più
Il segno più significa che il carattere prima del segno più deve esistere una o più volte, ma deve esistere almeno una volta.
$ echo "test" | awk '/te+st/{print $0}' $ echo "teest" | awk '/te+st/{print $0}' $ echo "tst" | awk '/te+st/{print $0}'
Se il carattere "e" non viene trovato, fallisce.
Puoi usarlo con classi di personaggi come questa:
$ echo "tst" | awk '/t[ae]+st/{print $0}' $ echo "test" | awk '/t[ae]+st/{print $0}' $ echo "teeast" | awk '/t[ae]+st/{print $0}' $ echo "teeast" | awk '/t[ae]+st/{print $0}'
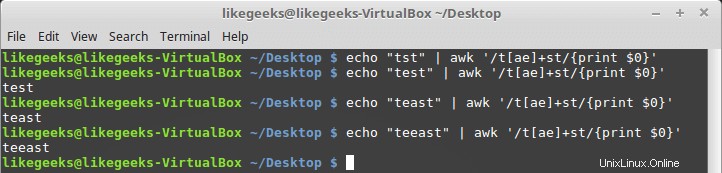
se esiste un carattere della classe di caratteri, ha esito positivo.
parentesi graffe
Le parentesi graffe ti consentono di specificare il numero di esistenza per un modello, ha due formati:
n:la regex appare esattamente n volte.
n,m:la regex appare almeno n volte, ma non più di m volte.
$ echo "tst" | awk '/te{1}st/{print $0}' $ echo "test" | awk '/te{1}st/{print $0}'

Nelle vecchie versioni di awk, dovresti usare l'opzione –re-interval per il comando awk per farlo leggere le parentesi graffe, ma nelle versioni più recenti non ne hai bisogno.
$ echo "tst" | awk '/te{1,2}st/{print $0}' $ echo "test" | awk '/te{1,2}st/{print $0}' $ echo "teest" | awk '/te{1,2}st/{print $0}' $ echo "teeest" | awk '/te{1,2}st/{print $0}'

In questo esempio, se il carattere "e" esiste una o due volte, ha esito positivo; in caso contrario, fallisce.
Puoi usarlo con classi di personaggi come questa:
$ echo "tst" | awk '/t[ae]{1,2}st/{print $0}' $ echo "test" | awk '/t[ae]{1,2}st/{print $0}' $ echo "teest" | awk '/t[ae]{1,2}st/{print $0}' $ echo "teeast" | awk '/t[ae]{1,2}st/{print $0}'
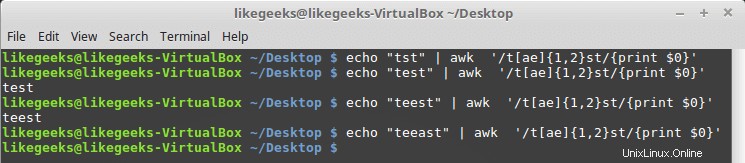
Se ci sono una o due istanze della lettera "a" o "e", il modello passa; in caso contrario, fallisce.
Simbolo del tubo
Il simbolo del tubo crea un OR logico tra 2 modelli. Se uno dei modelli esiste, ha successo; in caso contrario, fallisce, ecco un esempio:
$ echo "Testing regex" | awk '/regex|regular expressions/{print $0}' $ echo "Testing regular expressions" | awk '/regex|regular expressions/{print $0}' $ echo "This is something else" | awk '/regex|regular expressions/{print $0}'
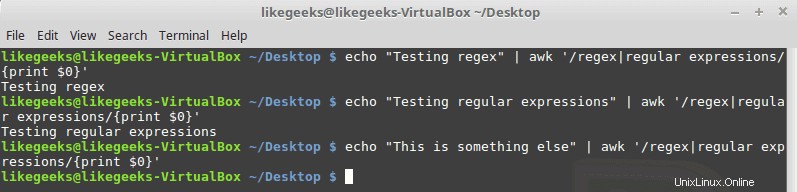
Non digitare spazi tra il motivo e il simbolo del tubo.
Espressioni di raggruppamento
Puoi raggruppare le espressioni in modo che i motori regex le considerino un pezzo unico.
$ echo "Like" | awk '/Like(Geeks)?/{print $0}' $ echo "LikeGeeks" | awk '/Like(Geeks)?/{print $0}'
Il raggruppamento di "Geeks" fa sì che il motore regex lo tratti come un pezzo unico, quindi se "LikeGeeks" o la parola "Mi piace" esistono, ha successo.
Esempi pratici
Abbiamo visto alcune semplici dimostrazioni dell'utilizzo di modelli di espressioni regolari. È ora di metterlo in atto, solo per esercitarsi.
Conteggio dei file di directory
Diamo un'occhiata a uno script bash che conta i file eseguibili in una cartella dalla variabile di ambiente PATH.
$ echo $PATH
Per ottenere un elenco di directory, devi sostituire i due punti con uno spazio.
$ echo $PATH | sed 's/:/ /g'
Ora ripetiamo ogni directory usando il ciclo for in questo modo:
mypath=$(echo $PATH | sed 's/:/ /g') for directory in $mypath; do done
Ottimo!!
Puoi ottenere i file in ogni directory utilizzando il comando ls e salvarlo in una variabile.
#!/bin/bash path_dir=$(echo $PATH | sed 's/:/ /g') total=0 for folder in $path_dir; do files=$(ls $folder) for file in $files; do total=$(($total + 1)) done echo "$folder - $total" total=0 done
Potresti notare che alcune directory non esistono, nessun problema con questo, va bene.
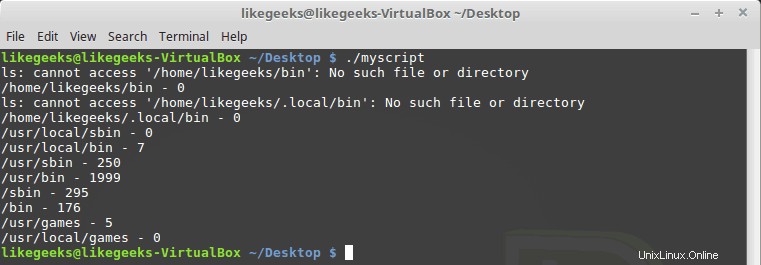
Freddo!! Questo è il potere di regex:queste poche righe di codice contano tutti i file in tutte le directory. Naturalmente, esiste un comando Linux per farlo molto facilmente, ma qui discutiamo di come utilizzare regex su qualcosa che puoi usare. Puoi trovare altre idee utili.
Indirizzo e-mail di convalida
Ci sono un sacco di siti Web che offrono modelli regex pronti per l'uso per tutto, inclusi e-mail, numero di telefono e molto altro, questo è utile, ma vogliamo capire come funziona.
esempio@unixlinux.online
Il nome utente può utilizzare qualsiasi carattere alfanumerico combinato con punto, trattino, segno più, trattino basso.
Il nome host può utilizzare qualsiasi carattere alfanumerico combinato con un punto e un trattino basso.
Per il nome utente, il seguente schema si adatta a tutti i nomi utente:
^([a-zA-Z0-9_\-\.\+]+)@
Il segno più indica che deve esistere uno o più caratteri seguito dal segno @.
Quindi il modello del nome host dovrebbe essere così:
([a-zA-Z0-9_\-\.]+)
Esistono regole speciali per i TLD o domini di primo livello e non devono essere inferiori a 2 e cinque caratteri al massimo. Quello che segue è il modello regex per il dominio di primo livello.
\.([a-zA-Z]{2,5})$ Ora li mettiamo tutti insieme:
^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$ Testiamo quella espressione regolare rispetto a un'e-mail:
$ echo "example@unixlinux.online" | awk '/^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$/{print $0}' $ echo "example@unixlinux.online" | awk '/^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$/{print $0}'

Fantastico!!
Questo è stato solo l'inizio del mondo regex che non finisce mai. Spero che tu capisca questi vomiti ASCII 🙂 e li usi in modo più professionale.
Spero che il post ti piaccia.
Grazie.