Curl è uno strumento eccellente per scaricare file nel terminale Linux.
La solita sintassi per scaricare un file con lo stesso nome del file originale è piuttosto semplice:
curl -O URL_of_the_fileQuesto funziona la maggior parte delle volte. Tuttavia, noterai che a volte quando scarichi un file da GitHub o SourceForge, non recupera il file corretto.
Ad esempio, stavo cercando di scaricare lo script di archinstall in formato tar gz. I file si trovano nella pagina di rilascio.
Se apro questo link al codice sorgente in un browser, mi ottiene il codice sorgente in formato .tar.gz.
Tuttavia, se utilizzo il terminale per scaricare lo stesso file utilizzando il comando curl, ottengo un piccolo file che non è nel formato di archivio corretto.
tar -zxvf v2.4.2.tar.gz
gzip: stdin: not in gzip format
tar: Child returned status 1
tar: Error is not recoverable: exiting now
Quando eseguo il comando file per conoscere il tipo di file esatto, mi dice che si tratta di un documento HTML.
file v2.4.2.tar.gz
v2.4.2.tar.gz: HTML document, ASCII text, with no line terminators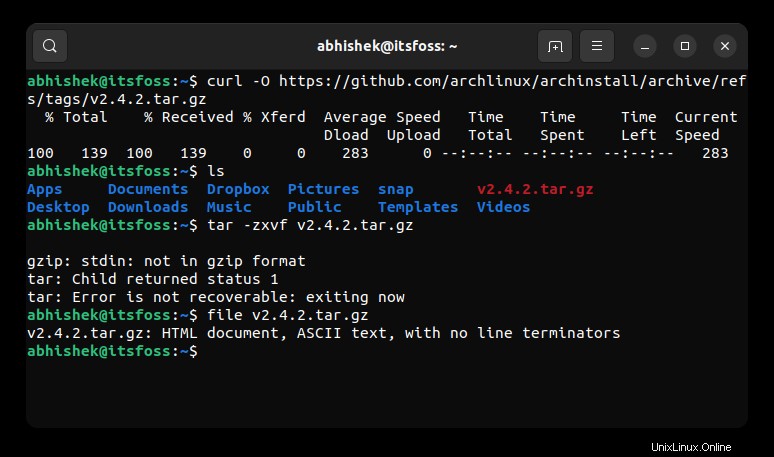
Documento HTML invece dell'archivio zip o tarball? Dov'è il problema? Lascia che ti mostri la soluzione rapida.
Download corretto del file di archivio con curl
Il problema qui è che l'URL che hai reindirizza al file di archivio effettivo. Per ottenerlo, devi utilizzare opzioni aggiuntive.
curl -JLO URL_of_the_fileLe opzioni possono essere in qualsiasi ordine. È solo più facile ricordare J LO (Jennifer Lopez).
Ecco una rapida spiegazione delle opzioni in base alla pagina man del comando curl.
- J:Questa opzione indica all'opzione -O, --remote-name di utilizzare il nome file Disposizione contenuto specificato dal server invece di estrarre un nome file dall'URL.
- L:Se il server segnala che la pagina richiesta è stata spostata in una posizione diversa (indicata con un'intestazione Location:e un codice di risposta 3XX), questa opzione farà ripetere a curl la richiesta nella nuova posizione.
- O:Con questa opzione, non è necessario specificare il nome del file di output per il download.
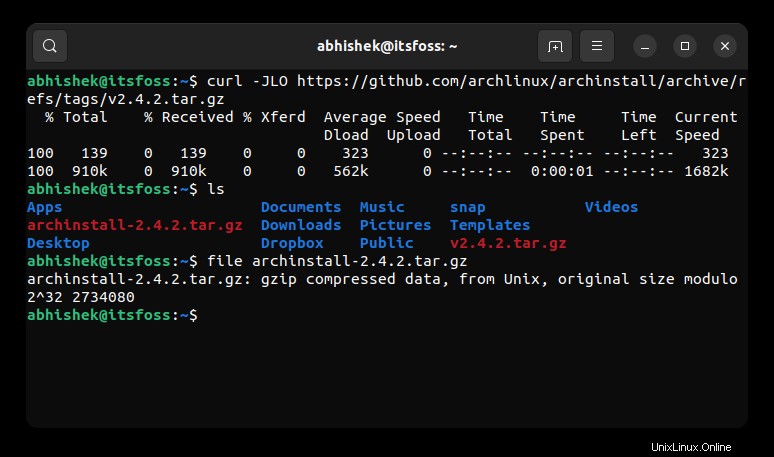
Come puoi vedere nello screenshot qui sotto, questa volta sono stato in grado di scaricare il file corretto con l'opzione curl -JLO.
Suggerimento bonus:devi accedere?
Questo funziona per i file pubblici. Ma se provi a scaricare file da repository privati o GitLab, potresti visualizzare un messaggio sul reindirizzamento alla pagina di accesso.
<html><body>You are being <a href="https://gitlab.com/users/sign_in">redirected</a>.</body></html>
In questi casi, fornisci il token API con l'opzione -H.
Spero che questo piccolo suggerimento rapido ti aiuti a scaricare correttamente i file di archivio con Curl. Fammi sapere se riscontri ancora problemi con i download di curl.