Quando si utilizza un elaboratore di testi, la formattazione del testo in modo che le righe si adattino allo spazio disponibile sul dispositivo di destinazione non dovrebbe essere un problema. Ma quando si lavora al terminale, le cose non sono così facili.
Naturalmente, puoi sempre interrompere le righe a mano usando il tuo editor di testo preferito, ma questo è raramente desiderabile ed è persino fuori questione per l'elaborazione automatizzata.
Si spera che POSIX fold utility e GNU/BSD fmt il comando può aiutarti a ridisporre un testo in modo che le righe non superino una determinata lunghezza.
Cos'è una riga in Unix, di nuovo?
Prima di entrare nei dettagli del fold e fmt comandi, definiamo prima di cosa stiamo parlando. In un file di testo, una riga è composta da una quantità arbitraria di caratteri, seguita dalla speciale sequenza di controllo di nuova riga (a volte chiamata EOL, per fine riga )
Sui sistemi simili a Unix, la sequenza di controllo di fine riga è composta dal (unico e solo) carattere avanzamento riga , a volte abbreviato LF o scritto \n seguendo una convenzione ereditata dal linguaggio C. A livello binario, il carattere di avanzamento riga è rappresentato come un byte contenente 0a valore esadecimale.
Puoi verificarlo facilmente usando hexdump utility che useremo molto in questo articolo. Quindi potrebbe essere una buona occasione per familiarizzare con quello strumento. Ad esempio, puoi esaminare i dump esadecimali di seguito per trovare quanti caratteri di nuova riga sono stati inviati da ciascun comando echo. Una volta che pensi di avere la soluzione, riprova quei comandi senza il | hexdump -C parte per vedere se hai indovinato correttamente.
sh$ echo hello | hexdump -C
00000000 68 65 6c 6c 6f 0a |hello.|
00000006
sh$ echo -n hello | hexdump -C
00000000 68 65 6c 6c 6f |hello|
00000005
sh$ echo -e 'hello\n' | hexdump -C
00000000 68 65 6c 6c 6f 0a 0a |hello..|
00000007
Vale la pena menzionare a questo punto diversi sistemi operativi possono seguire regole diverse per quanto riguarda la sequenza di nuova riga. Come abbiamo visto sopra, i sistemi operativi simili a Unix utilizzano il line feed carattere, ma Windows, come la maggior parte dei protocolli Internet, utilizza due caratteri:ritorno a capo+avanzamento riga coppia (CRLF o 0d 0a o \r\n ). Su Mac OS "classico" (fino a MacOS 9.2 incluso nei primi anni 2000), i computer Apple utilizzavano solo il CR come carattere di nuova riga. Anche altri computer legacy utilizzavano la coppia LFCR, o anche sequenze di byte completamente diverse nel caso di vecchi sistemi incompatibili con ASCII. Fortunatamente, questi ultimi sono reliquie del passato e dubito che vedrai un computer EBCDIC in uso oggi!
Parlando di storia, se sei curioso, l'uso dei caratteri di controllo "ritorno a capo" e "avanzamento riga" risalgono al codice Baudot utilizzato nell'era della telescrivente. Potresti aver visto la telescrivente raffigurata nei vecchi film come interfaccia per un computer delle dimensioni di una stanza. Ma anche prima, le telescriventi venivano utilizzate "autonome" per la comunicazione punto-punto o multipunto. A quel tempo, un terminale tipico sembrava una macchina da scrivere pesante con una tastiera meccanica, carta e un carrello mobile che reggeva la testina di stampa. Per iniziare una nuova linea, il carrello deve essere riportato all'estrema sinistra e la carta deve spostarsi verso l'alto ruotando la piastra (a volte chiamata "cilindro"). Queste due mosse erano controllate da due sistemi elettromeccanici indipendenti, i caratteri di controllo dell'avanzamento riga e del ritorno a capo erano collegati direttamente a quelle due parti del dispositivo. Poiché lo spostamento del carrello richiede più volte rispetto alla rotazione della piastra, era logico avviare prima il ritorno del carrello. La separazione delle due funzioni ha avuto anche un paio di interessanti effetti collaterali, come consentire la sovrastampa (inviando solo il CR) o la trasmissione efficiente di "doppia interlinea" (un CR + due LF).
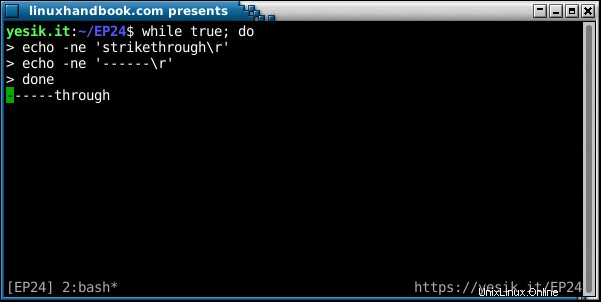
La definizione all'inizio di questa sezione descrive principalmente ciò che è logico la linea è. La maggior parte delle volte, tuttavia, quella linea logica "arbitrariamente lunga" deve essere inviata su un fisico dispositivo come uno schermo o una stampante, dove lo spazio disponibile è limitato. La visualizzazione di linee logiche brevi su un dispositivo con linee fisiche più grandi non è un problema. Semplicemente c'è spazio inutilizzato a destra del testo. Ma cosa succede se si tenta di visualizzare una riga di testo più grande dello spazio disponibile sul dispositivo? In realtà, ci sono due soluzioni, ognuna con la sua parte di inconvenienti:
- In primo luogo, il dispositivo può troncare le righe alla loro dimensione fisica, nascondendo così parte del contenuto all'utente. Alcune stampanti lo fanno, in particolare le stampanti stupide (e sì, ci sono ancora stampanti ad aghi di base in uso oggi, specialmente in ambienti difficili o sporchi!)
- La seconda opzione per visualizzare righe logiche lunghe è dividerle in più righe fisiche. Questo è chiamato a capo automatico perché le linee sembrano avvolgere lo spazio disponibile, un effetto particolarmente visibile se puoi ridimensionare il display come quando si lavora con un emulatore di terminale.
Questi comportamenti automatici sono abbastanza utili, ma ci sono ancora volte in cui vuoi interrompere lunghe file in una determinata posizione indipendentemente dalle dimensioni fisiche del dispositivo. Ad esempio, può essere utile perché si desidera che le interruzioni di riga si verifichino nella stessa posizione sia sullo schermo che sulla stampante. Oppure perché si desidera che il testo venga utilizzato in un'applicazione che non esegue il ritorno a capo della riga (ad esempio, se si incorpora il testo a livello di codice in un file SVG). Infine, che tu ci creda o no, ci sono ancora molti protocolli di comunicazione che impongono una larghezza massima della linea nelle trasmissioni, compresi quelli popolari come IRC e SMTP (se hai mai visto l'errore 550 Lunghezza massima della linea superata sai cosa sono parlare di). Quindi ci sono molte occasioni in cui è necessario spezzare lunghe file in pezzi più piccoli. Questo è il compito di POSIX fold comando.
Il comando piega
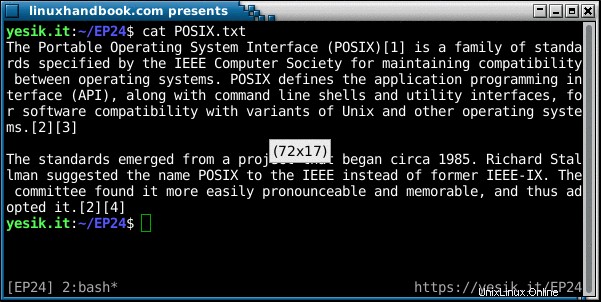
Se utilizzato senza alcuna opzione, il fold il comando aggiunge ulteriori sequenze di controllo di nuova riga per garantire che nessuna riga superi il limite di 80 caratteri. Giusto per chiarire, una riga conterrà al massimo 80 caratteri più la sequenza di nuova riga.
Se hai scaricato il materiale di supporto per quell'articolo, puoi provarlo da solo:
sh$ fold POSIX.txt | head -5
The Portable Operating System Interface (POSIX)[1] is a family of standards spec
ified by the IEEE Computer Society for maintaining compatibility between operati
ng systems. POSIX defines the application programming interface (API), along wit
h command line shells and utility interfaces, for software compatibility with va
riants of Unix and other operating systems.[2][3]
# Using AWK to prefix each line by its length:
sh$ fold POSIX.txt | awk '{ printf("%3d %s\n", length($0), $0) }'
80 The Portable Operating System Interface (POSIX)[1] is a family of standards spec
80 ified by the IEEE Computer Society for maintaining compatibility between operati
80 ng systems. POSIX defines the application programming interface (API), along wit
80 h command line shells and utility interfaces, for software compatibility with va
49 riants of Unix and other operating systems.[2][3]
0
80 The standards emerged from a project that began circa 1985. Richard Stallman sug
80 gested the name POSIX to the IEEE instead of former IEEE-IX. The committee found
71 it more easily pronounceable and memorable, and thus adopted it.[2][4]
Puoi modificare la lunghezza massima della riga di output utilizzando -w opzione. Più interessante probabilmente è l'uso di -s opzione per garantire che le righe si interrompano al limite di una parola. Confrontiamo il risultato senza e con -s opzione se applicata al secondo paragrafo del nostro testo di esempio:
# Without `-s` option: fold will break lines at the specified position
# Broken lines have exactly the required width
sh$ awk -vRS='' 'NR==2' POSIX.txt |
fold -w 30 | awk '{ printf("%3d %s\n", length($0), $0) }'
30 The standards emerged from a p
30 roject that began circa 1985.
30 Richard Stallman suggested the
30 name POSIX to the IEEE instea
30 d of former IEEE-IX. The commi
30 ttee found it more easily pron
30 ounceable and memorable, and t
21 hus adopted it.[2][4]
# With `-s` option: fold will break lines at the last space before the specified position
# Broken lines are shorter or equal to the required width
awk -vRS='' 'NR==2' POSIX.txt |
fold -s -w 30 | awk '{ printf("%3d %s\n", length($0), $0) }'
29 The standards emerged from a
25 project that began circa
23 1985. Richard Stallman
28 suggested the name POSIX to
27 the IEEE instead of former
29 IEEE-IX. The committee found
29 it more easily pronounceable
24 and memorable, and thus
17 adopted it.[2][4]
Ovviamente, se il tuo testo contiene parole più lunghe della lunghezza massima della riga, il comando fold non sarà in grado di rispettare il -s bandiera. In tal caso, il fold l'utilità interromperà le parole di grandi dimensioni nella posizione massima, assicurando sempre che nessuna linea superi la larghezza massima consentita.
sh$ echo "It's Supercalifragilisticexpialidocious!" | fold -sw 10
It's
Supercalif
ragilistic
expialidoc
ious!Caratteri multibyte
Come la maggior parte, se non tutte, le utility principali, il fold il comando è stato progettato in un momento in cui un carattere equivaleva a un byte. Tuttavia, questo non è più il caso dell'informatica moderna, specialmente con l'adozione diffusa di UTF-8. Qualcosa che porta a problemi sfortunati:
# Just in case, check first the relevant locale
# settings are properly defined
debian-9.4$ locale | grep LC_CTYPE
LC_CTYPE="en_US.utf8"
# Everything is OK, unfortunately...
debian-9.4$ echo élève | fold -w2
é
l�
�v
e
La parola “élève” (la parola francese per “studente”) contiene due lettere accentate:é (LETTERA E PICCOLA LATINA CON ACUTO) e è (LETTERA E PICCOLA LATINA CON GRAVE). Utilizzando il set di caratteri UTF-8, queste lettere vengono codificate utilizzando due byte ciascuna (rispettivamente, c3 a9 e c3 a8 ), invece di un solo byte come nel caso delle lettere latine non accentate. Puoi verificarlo esaminando i byte grezzi usando hexdump utilità. Dovresti essere in grado di individuare le sequenze di byte corrispondenti a é e è caratteri. A proposito, potresti anche vedere in quel dump il nostro vecchio amico il carattere del feed di riga il cui codice esadecimale è stato menzionato prima:
debian-9.4$ echo élève | hexdump -C
00000000 c3 a9 6c c3 a8 76 65 0a |..l..ve.|
00000008Esaminiamo ora l'output prodotto dal comando fold:
debian-9.4$ echo élève | fold -w2
é
l�
�v
e
debian-9.4$ echo élève | fold -w 2 | hexdump -C
00000000 c3 a9 0a 6c c3 0a a8 76 0a 65 0a |...l...v.e.|
0000000b
Ovviamente, il risultato prodotto dal fold comando è leggermente più lungo della stringa di caratteri originale a causa delle nuove righe extra:rispettivamente 11 byte di lunghezza e 8 byte di lunghezza, comprese le nuove righe. A proposito, nell'output di fold comando potresti aver visto il feed di riga (0a ) carattere che compare ogni due byte. E questo è esattamente il problema:il comando fold ha interrotto le righe a byte posizioni, non a carattere posizioni. Anche se l'interruzione si verifica nel mezzo di un carattere multi-byte! Non c'è bisogno di menzionare che l'output risultante non è più un flusso di byte UTF-8 valido, da qui l'uso del carattere sostitutivo Unicode (� ) dal mio terminale come segnaposto per le sequenze di byte non valide.
Come per il cut comando che ho scritto qualche settimana fa, questa è una limitazione nell'implementazione GNU del fold utilità e questo è chiaramente in contrasto con le specifiche POSIX che affermano esplicitamente che "Una riga non deve essere interrotta nel mezzo di un carattere".
Quindi appare il fold di GNU l'implementazione gestisce correttamente solo le codifiche di caratteri a un byte di lunghezza fissa (US-ASCII, Latin1 e così via). Come soluzione alternativa, se esiste un set di caratteri adatto, è possibile transcodificare il testo in una codifica di caratteri a un byte prima di elaborarlo e successivamente transcodificarlo in UTF-8. Tuttavia, questo è ingombrante, per non dire altro:
debian-9.4$ echo élève |
iconv -t latin1 | fold -w 2 |
iconv -f latin1 | hexdump -C
00000000 c3 a9 6c 0a c3 a8 76 0a 65 0a |..l...v.e.|
0000000a
debian-9.4$ echo élève |
iconv -t latin1 | fold -w 2 |
iconv -f latin1
él
èv
e
Essendo tutto ciò piuttosto deludente, ho deciso di controllare il comportamento di altre implementazioni. Come spesso accade, l'implementazione OpenBSD del fold l'utilità è molto migliore in questa materia poiché è conforme a POSIX e rispetterà il LC_CTYPE impostazione locale per gestire correttamente i caratteri multibyte:
openbsd-6.3$ locale | grep LC_CTYPE
LC_CTYPE=en_US.UTF-8
openbsd-6.3$ echo élève | fold -w 2 C
él
èv
e
openbsd-6.3$ echo élève | fold -w 2 | hexdump -C
00000000 c3 a9 6c 0a c3 a8 76 0a 65 0a |..l...v.e.|
0000000aCome puoi vedere, l'implementazione di OpenBSD taglia correttamente le linee a carattere posizioni, indipendentemente dal numero di byte necessari per codificarle. Nella stragrande maggioranza dei casi d'uso, questo è ciò che desideri. Tuttavia, se hai bisogno del comportamento legacy (es.:stile GNU) considerando un byte come un carattere, puoi cambiare temporaneamente la locale corrente nella cosiddetta locale POSIX (identificata dalla costante "POSIX" o, per ragioni storiche, "C ”):
openbsd-6.3$ echo élève | LC_ALL=C fold -w 2
é
l�
�v
e
openbsd-6.3$ echo élève | LC_ALL=C fold -w 2 | hexdump -C
00000000 c3 a9 0a 6c c3 0a a8 76 0a 65 0a |...l...v.e.|
0000000b
Infine, POSIX specifica il -b flag, che indica il fold utility per misurare la lunghezza della linea in byte , ma ciò garantisce comunque caratteri multibyte (secondo l'attuale LC_CTYPE impostazioni locali) non essere rotto.
Come esercizio, ti consiglio vivamente di dedicare il tempo necessario per trovare le differenze a livello di byte tra il risultato ottenuto modificando la locale corrente in "C" (sopra) e il risultato ottenuto usando il -b flag invece (sotto). Potrebbe essere sottile. Ma c'è c'è una differenza:
openbsd-6.3$ echo élève | fold -b -w 2 | hexdump -C
00000000 c3 a9 0a 6c 0a c3 a8 0a 76 65 0a |...l....ve.|
0000000bAllora, hai trovato la differenza?
Bene, cambiando la locale in "C", il fold l'utilità non si è occupata delle sequenze multi-byte, poiché, per definizione, quando la locale è "C" gli strumenti devono presumere un carattere è un byte . Quindi una nuova riga può essere aggiunta ovunque, anche nel mezzo di una sequenza di byte che farebbe sono stati considerati come un carattere multibyte in un'altra codifica dei caratteri. Questo è esattamente ciò che è successo quando lo strumento ha prodotto il c3 0a a8 sequenza di byte:i due byte c3 a8 sono intesi come un carattere quando LC_CTYPE definisce la codifica dei caratteri come UTF-8. Ma la stessa sequenza di byte è vista come due caratteri nella lingua "C":
# Bytes are bytes. They don't change so
# the byte count is the same whatever is the locale
openbsd-6.3$ printf "%d bytes\n" $(echo -n é | LC_ALL=en_US.UTF-8 wc -c)
2 bytes
openbsd-6.3$ printf "%d bytes\n" $(echo -n é | LC_ALL=C wc -c)
2 bytes
# The interpretation of the bytes may change depending on the encoding
# so the corresponding character count will change
openbsd-6.3$ printf "%d chars\n" $(echo -n é | LC_ALL=en_US.UTF-8 wc -m)
1 chars
openbsd-6.3$ printf "%d chars\n" $(echo -n é | LC_ALL=C wc -m)
2 chars
D'altra parte, con il -b opzione, lo strumento dovrebbe essere ancora multibyte. Quell'opzione cambia solo nel modo in cui conta le posizioni , in byte questa volta, anziché in caratteri come avviene per impostazione predefinita. In tal caso, poiché le sequenze multibyte non vengono suddivise, l'output risultante rimane un flusso di caratteri valido (secondo l'attuale LC_CTYPE impostazioni locali):
openbsd-6.3$ echo élève | fold -b -w 2
é
l
è
ve
L'hai visto, ora non ci sono più occorrenze del carattere sostitutivo Unicode (� ), e non abbiamo perso alcun carattere significativo nel processo, a scapito di finire questa volta con righe contenenti un numero variabile di caratteri e un numero variabile di byte. Infine, tutto lo strumento assicura che non ci siano più byte per riga di quelli richiesti con -w opzione. Qualcosa che possiamo verificare usando il wc strumento:
openbsd-6.3$ echo élève | fold -b -w 2 | while read line; do
> printf "%3d bytes %3d chars %s\n" \
> $(echo -n $line | wc -c) \
> $(echo -n $line | wc -m) \
> $line
> done
2 bytes 1 chars é
1 bytes 1 chars l
2 bytes 1 chars è
2 bytes 2 chars ve
Ancora una volta, prenditi il tempo necessario per studiare l'esempio sopra. Fa uso di printf e wc comandi che non ho spiegato in dettaglio in precedenza. Quindi, se le cose non sono abbastanza chiare, non esitate a utilizzare la sezione commenti per chiedere alcune spiegazioni!
Per curiosità, ho controllato -b flag sulla mia Debian box usando GNU fold attuazione:
debian-9.4$ echo élève | fold -w 2 | hexdump -C
00000000 c3 a9 0a 6c c3 0a a8 76 0a 65 0a |...l...v.e.|
0000000b
debian-9.4$ echo élève | fold -b -w 2 | hexdump -C
00000000 c3 a9 0a 6c c3 0a a8 76 0a 65 0a |...l...v.e.|
0000000b
Non perdere tempo a cercare una differenza tra -b e non--b versioni di quell'esempio:abbiamo visto che l'implementazione di GNU fold non è multi-byte, quindi entrambi i risultati sono identici. Se non ne sei convinto, forse potresti usare il diff -s comando per consentire al tuo computer di confermarlo. Se lo fai, usa la sezione commenti per condividere il comando che hai usato con gli altri lettori!
Comunque, significa il -b opzione inutile nell'implementazione GNU di fold utilità? Bene, leggendo più attentamente la documentazione GNU Coreutils per il fold comando, ho trovato il -b l'opzione tratta solo caratteri speciali come la tabulazione o il backspace che contano rispettivamente per 1~8 (da uno a otto) o -1 (meno uno) posizione in modalità normale, ma contano sempre per 1 posizione in modalità byte. Confuso? Quindi, forse potremmo prenderci del tempo per spiegarlo in modo più dettagliato.
Gestione di tabulazioni e backspace
La maggior parte dei file di testo con cui ti occuperai contiene solo caratteri stampabili e sequenze di fine riga. Tuttavia, occasionalmente, può capitare che alcuni personaggi di controllo si intromettano nei tuoi dati. Il carattere di tabulazione (\t ) è uno di questi. Molto più raramente, il backspace (\b ) possono anche essere incontrati. Lo menziono ancora qui perché, come suggerisce il nome, è un carattere di controllo che fa muovere il cursore di una posizione indietro (verso sinistra), mentre la maggior parte degli altri personaggi sta andando avanti (verso destra).
sh$ echo -e 'tab:[\t] backspace:[\b]'
tab:[ ] backspace:]
Questo potrebbe non essere visibile nel tuo browser, quindi ti consiglio vivamente di testarlo sul tuo terminale. Ma i caratteri di tabulazione (\t ) occupa diverse posizioni sull'uscita. E il backspace? Sembra che ci sia qualcosa di strano nell'output, vero? Quindi rallenta un po' le cose, suddividendo la stringa di testo in più parti e inserendo un po' di sleep tra loro:
# For that to work, type all the commands on the same line
# or using backslashes like here if you split them into
# several (physical) lines:
sh$ echo -ne 'tab:[\t] backspace:['; \
sleep 1; echo -ne '\b'; \
sleep 1; echo -n ']'; \
sleep 1; echo ''OK? L'hai visto questa volta? Scomponiamo la sequenza degli eventi:
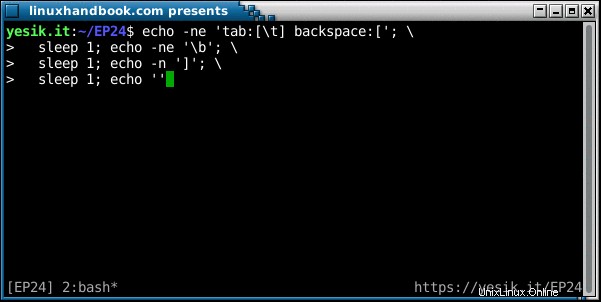
- La prima stringa di caratteri viene visualizzata "normalmente" fino alla seconda parentesi quadra aperta. A causa del
-nflag, l'echocomando non invia un carattere di nuova riga, in modo che il cursore rimanga sulla stessa riga. - Primo sonno.
- Viene emesso Backspace, con il risultato che il cursore si sposta indietro di una posizione. Ancora nessuna nuova riga, quindi il cursore rimane sulla stessa riga.
- Secondo sonno.
- Viene visualizzata la parentesi quadra di chiusura, sovrascrivendo quello di apertura.
- Terzo sonno.
- In assenza del
-nopzione, l'ultimoechoil comando invia infine il carattere di nuova riga e il cursore si sposta sulla riga successiva, dove verrà visualizzato il prompt della shell.
Ovviamente, un effetto altrettanto interessante può essere ottenuto utilizzando un ritorno a capo, se lo ricordi:
sh$ echo -n 'hello'; sleep 1; echo -e '\rgood bye'
good bye
Sono abbastanza sicuro che tu abbia già visto qualche utilità da riga di comando come curl , wget o ffmpeg visualizzazione di una barra di avanzamento. Fanno la loro magia usando una combinazione di \b e/o \r .
Per quanto interessante che la discussione possa essere di per sé, il punto qui era capire che gestire quei caratteri può essere difficile per il fold utilità. Si spera che lo standard POSIX definisca le regole:
Tutti questi trattamenti speciali sono disabilitati quando si utilizza il -b opzione. In tal caso, soprattutto i caratteri di controllo contano (correttamente) per un byte e quindi aumentare il contatore di posizione di uno e solo uno, proprio come qualsiasi altro personaggio.
Per una migliore comprensione, ti lascio esaminare da solo i due seguenti esempi (magari usando hexdump utilità). Ora dovresti essere in grado di scoprire perché "ciao" è diventato "inferno" e dove si trova esattamente la "i" nell'output (come è lì, anche se non puoi vederlo!) Come sempre, se hai bisogno di aiuto , o semplicemente se vuoi condividere i tuoi risultati, la sezione commenti è tua.
# Why "hello" has become "hell"? where is the "i"?
sh$ echo -e 'hello\rgood bi\bye' | fold -w4
hell
good
bye
# Why "hello" has become "hell"? where is the "i"?
# Why the second line seems to be made of only two chars instead of 4?
sh$ echo -e 'hello\rgood bi\bye' | fold -bw4
hell
go
od b
yeAltre limitazioni
Il fold il comando che abbiamo studiato fino ad ora è stato progettato per suddividere lunghe linee logiche in linee fisiche più piccole, in particolare per scopi di formattazione.
Ciò significa che presuppone che ogni linea di input sia autonoma e possa essere interrotta indipendentemente dalle altre linee. Questo non è sempre il caso, tuttavia. Consideriamo ad esempio quella mail molto importante che ho ricevuto:
sh$ cat MAIL.txt
Dear friends,
Have a nice day!
We are manufactuer for event chairs and tables, more than 10 years experience.
We supply all kinds of wooden, resin and metal event chairs, include chiavari
chairs, cross back chairs, folding chairs, napoleon chairs, phoenix chairs, etc.
Our chairs and tables are of high quality and competitively priced.
If you need our products, welcome to contact me;we are happy to make you special
offer.
Best Regards
Doris
sh$ awk '{ length>maxlen && (maxlen=length) } END { print maxlen }' MAIL.txt
81
Ovviamente, le linee erano già interrotte a una larghezza fissa. Il awk il comando mi ha detto che la larghezza massima della riga qui era ... 81 caratteri, esclusa la nuova sequenza di righe. Sì, era sufficientemente strano che l'ho ricontrollato:infatti la riga più lunga ha 80 caratteri stampabili più uno spazio in più all'81a posizione e solo dopo c'è il carattere di avanzamento riga. Probabilmente gli informatici che lavorano per conto di questo "produttore" di sedie potrebbero trarre vantaggio dalla lettura di questo articolo!
Ad ogni modo, supponendo che io voglia cambiare la formattazione di quell'email, avrò problemi con il fold comando a causa delle interruzioni di riga esistenti. Ti ho lasciato controllare da solo i due comandi seguenti, se lo desideri, ma nessuno di essi funzionerà come previsto:
sh$ fold -sw 100 MAIL.txt
sh$ fold -sw 60 MAIL.txtIl primo semplicemente non farà nulla poiché tutte le righe sono già più corte di 100 caratteri. Per quanto riguarda il secondo comando, interromperà le righe alla 60a posizione ma manterrà i caratteri di nuova riga già esistenti in modo che il risultato sia frastagliato. Sarà particolarmente visibile nel terzo paragrafo:
sh$ awk -v RS='' 'NR==3' MAIL.txt |
fold -sw 60 |
awk '{ length>maxlen && (maxlen=length); print length, $0 }'
53 We supply all kinds of wooden, resin and metal event
25 chairs, include chiavari
60 chairs, cross back chairs, folding chairs, napoleon chairs,
20 phoenix chairs, etc.La prima riga del terzo paragrafo è stata interrotta alla posizione 53, che è coerente con la nostra larghezza massima di 60 caratteri per riga. Tuttavia, la seconda riga si è interrotta alla posizione 25 perché quel carattere di nuova riga era già presente nel file di input. In altre parole, per ridimensionare correttamente i paragrafi, dobbiamo prima unire le righe prima di spezzarle nella nuova posizione di destinazione.
Puoi usare sed o awk per ricongiungersi alle linee. E in effetti, come l'ho menzionato nel video introduttivo, sarebbe una bella sfida per te. Quindi non esitare a pubblicare la tua soluzione nella sezione commenti.
Quanto a me, seguirò un percorso più semplice guardando il fmt comando. Sebbene non sia un comando standard POSIX, è disponibile sia nel mondo GNU che BSD. Quindi ci sono buone probabilità che sia utilizzabile sul tuo sistema. Sfortunatamente, la mancanza di standardizzazione avrà delle implicazioni negative come vedremo in seguito. Ma per ora concentriamoci sulle parti buone.
Il comando fmt
Il fmt il comando è più evoluto del fold comando e ha più opzioni di formattazione. La parte più interessante è che può identificare i paragrafi nel file di input in base alle righe vuote. Ciò significa che tutte le righe fino alla successiva riga vuota (o alla fine del file) verranno prima unite per formare quella che ho chiamato prima una "linea logica" del testo. Solo dopo, il fmt il comando interromperà il testo nella posizione richiesta.
Vediamo ora cosa cambierà quando applicato al secondo paragrafo della mia mail di esempio:
sh$ awk -v RS='' 'NR==3' MAIL.txt |
fmt -w 60 |
awk '{ length>maxlen && (maxlen=length); print length, $0 }'
60 We supply all kinds of wooden, resin and metal event chairs,
59 include chiavari chairs, cross back chairs, folding chairs,
37 napoleon chairs, phoenix chairs, etc.
Aneddoticamente, il fmt comando accettato per comprimere un'altra parola nella prima riga. Ma cosa più interessante, la seconda riga è ora riempita, il che significa che il carattere di nuova riga già presente nel file di input dopo che la parola "chiavari" (che cos'è?) è stata scartata. Naturalmente, le cose non sono perfette e il fmt l'algoritmo di rilevamento dei paragrafi a volte attiva falsi positivi, come nei saluti alla fine della posta (riga 14 dell'output):
sh$ fmt -w 60 MAIL.txt | cat -n
1 Dear friends,
2
3 Have a nice day! We are manufactuer for event chairs and
4 tables, more than 10 years experience.
5
6 We supply all kinds of wooden, resin and metal event chairs,
7 include chiavari chairs, cross back chairs, folding chairs,
8 napoleon chairs, phoenix chairs, etc.
9
10 Our chairs and tables are of high quality and competitively
11 priced. If you need our products, welcome to contact me;we
12 are happy to make you special offer.
13
14 Best Regards Doris
Ho detto prima il fmt command era uno strumento di formattazione del testo più evoluto rispetto a fold utilità. Certo che lo è. Potrebbe non essere ovvio a prima vista, ma se guardi attentamente le righe 10-11, potresti notare che usava due spazi dopo il punto:applicare una convenzione molto discussa di utilizzare due spazi alla fine di una frase. Non entrerò in quel dibattito per sapere se dovresti o meno usare due spazi tra le frasi, ma non hai una vera scelta qui:per quanto ne so, nessuna delle implementazioni comuni di fmt comando offrono un flag per disabilitare il doppio spazio dopo una frase. A meno che una tale opzione non esista da qualche parte e l'ho persa? Se questo è il caso, sarò felice che tu me lo faccia sapere usando la sezione commenti:come scrittore francese, non ho mai usato il "doppio spazio" dopo una frase...
Altre opzioni fmt
Il fmt l'utilità è progettata con alcune capacità di formattazione in più rispetto al comando fold. Tuttavia, non essendo definito POSIX, ci sono grandi incompatibilità tra le opzioni GNU e BSD.
Ad esempio, il -c l'opzione è usata nel mondo BSD per centrare il testo mentre in fmt di GNU Coreutils abilita la modalità margine corona, “preservando il rientro delle prime due righe all'interno di un paragrafo, e allineando il margine sinistro di ogni riga successiva con quello della seconda riga. “
Ti ho lasciato sperimentare da solo con GNU fmt -c se vuoi. Personalmente, trovo più interessante studiare la funzionalità di centratura del testo BSD a causa di alcune stranezze:infatti, in OpenBSD, fmt -c will center the text according to the target width— but without reflowing it! So the following command will not work as you might have expected:
openbsd-6.3$ fmt -c -w 60 MAIL.txt
Dear friends,
Have a nice day!
We are manufactuer for event chairs and tables, more than 10 years experience.
We supply all kinds of wooden, resin and metal event chairs, include chiavari
chairs, cross back chairs, folding chairs, napoleon chairs, phoenix chairs, etc.
Our chairs and tables are of high quality and competitively priced.
If you need our products, welcome to contact me;we are happy to make you special
offer.
Best Regards
Doris
If you really want to reflow the text for a maximum width of 60 characters and center the result, you will have to use two instances of the fmt comando:
openbsd-6.3$ fmt -w 60 MAIL.txt | fmt -c -w60
Dear friends,
Have a nice day! We are manufactuer for event chairs and
tables, more than 10 years experience.
We supply all kinds of wooden, resin and metal event chairs,
include chiavari chairs, cross back chairs, folding chairs,
napoleon chairs, phoenix chairs, etc.
Our chairs and tables are of high quality and competitively
priced. If you need our products, welcome to contact me;we
are happy to make you special offer.
Best Regards Doris
I will not make here an exhaustive list of the differences between the GNU and BSD fmt implementations … essentially because all the options are different! Except of course the -w opzione. Speaking of that, I forgot to mention -N where N is an integer is a shortcut for -wN . Moreover you can use that shortcut both with the fold and fmt commands:so, if you were perseverent enough to read his article until this point, as a reward you may now amaze your friends by saving one (!) entire keystroke the next time you will use one of those utilities:
debian-9.4$ fmt -50 POSIX.txt | head -5
The Portable Operating System Interface
(POSIX)[1] is a family of standards specified
by the IEEE Computer Society for maintaining
compatibility between operating systems. POSIX
defines the application programming interface
openbsd-6.3$ fmt -50 POSIX.txt | head -5
The Portable Operating System Interface (POSIX)[1]
is a family of standards specified by the IEEE
Computer Society for maintaining compatibility
between operating systems. POSIX defines the
application programming interface (API), along
debian-9.4$ fold -sw50 POSIX.txt | head -5
The Portable Operating System Interface
(POSIX)[1] is a family of standards specified by
the IEEE Computer Society for maintaining
compatibility between operating systems. POSIX
defines the application programming interface
openbsd-6.3$ fold -sw50 POSIX.txt | head -5
The Portable Operating System Interface
(POSIX)[1] is a family of standards specified by
the IEEE Computer Society for maintaining
compatibility between operating systems. POSIX
defines the application programming interface
As the final word, you may also notice in that last example the GNU and BSD versions of the fmt utility are using a different formatting algorithm, producing a different result. On the other hand, the simpler fold algorithm produces consistent results between the implementations. All that to say if portability is a premium, you need to stick with the fold command, eventually completed by some other POSIX utilities. But if you need more fancy features and can afford to break compatibility, take a look at the manual for the fmt command specific to your own system. And let us know if you discovered some fun or creative usage for those vendor-specific options!