Non importa se sei un amministratore di sistema o un semplice appassionato, è probabile che tu debba lavorare spesso con documenti di testo. Linux, come altri Unice, fornisce alcune delle migliori utilità di manipolazione del testo per gli utenti finali. L'utilità della riga di comando sed è uno di questi strumenti che rende l'elaborazione del testo molto più comoda e produttiva. Se sei un utente esperto, dovresti già conoscere sed. Tuttavia, i principianti spesso sentono che l'apprendimento di sed richiede un duro lavoro e quindi si astengono dall'usare questo strumento affascinante. Ecco perché ci siamo presi la libertà di produrre questa guida e aiutarli ad apprendere le basi di sed il più facilmente possibile.
Utili comandi SED per utenti principianti
Sed è una delle tre utilità di filtraggio ampiamente utilizzate disponibili in Unix, le altre sono "grep e awk". Abbiamo già trattato il comando Linux grep e il comando awk per i principianti. Questa guida mira a concludere l'utilità sed per utenti inesperti e renderli esperti nell'elaborazione di testi utilizzando Linux e altri Unice.
Come funziona SED:una comprensione di base
Prima di approfondire direttamente gli esempi, dovresti avere una comprensione concisa di come funziona sed in generale. Sed è un editor di flussi, basato sull'utilità ed. Ci consente di apportare modifiche di modifica a un flusso di dati testuali. Sebbene possiamo utilizzare un certo numero di editor di testo Linux per la modifica, sed consente qualcosa di più conveniente.
Puoi usare sed per trasformare il testo o filtrare i dati essenziali al volo. Aderisce alla filosofia di base di Unix eseguendo molto bene questo compito specifico. Inoltre, sed funziona molto bene con gli strumenti e i comandi standard del terminale Linux. Pertanto, è più adatto per molte attività rispetto ai tradizionali editor di testo.

Al suo interno, sed prende alcuni input, esegue alcune manipolazioni e sputa l'output. Non cambia l'input ma mostra semplicemente il risultato nello standard output. Possiamo facilmente rendere permanenti queste modifiche tramite il reindirizzamento I/O o modificando il file originale. La sintassi di base di un comando sed è mostrata di seguito.
sed [OPTIONS] INPUT sed 'list of ed commands' filename
La prima riga è la sintassi mostrata nel manuale sed. Il secondo è più facile da capire. Non preoccuparti se non hai familiarità con i comandi ed in questo momento. Li imparerai in questa guida.
1. Input di testo sostitutivo
- -Il comando sostitutivo è la funzionalità più utilizzata di sed da molti utenti. Ci consente di sostituire una parte di testo con altri dati. Utilizzerai molto spesso questo comando per elaborare dati testuali. Funziona come il seguente.
$ echo 'Hello world!' | sed 's/world/universe/'
Questo comando produrrà la stringa "Hello universe!". Ha quattro parti fondamentali. Le 's' comando indica l'operazione di sostituzione, /../../ sono delimitatori, la prima parte all'interno dei delimitatori è il modello che deve essere modificato e l'ultima parte è la stringa di sostituzione.
2. Sostituzione dell'input di testo da file
Creiamo prima un file usando quanto segue.
$ echo 'strawberry fields forever...' >> input-file $ cat input-file
Ora, supponiamo di voler sostituire la fragola con il mirtillo. Possiamo farlo usando il seguente semplice comando. Nota le somiglianze tra la parte sed di questo comando e quella precedente.
$ sed 's/strawberry/blueberry/' input-file
Abbiamo semplicemente aggiunto il nome del file dopo la parte sed. Puoi anche produrre prima il contenuto del file e poi usare sed per modificare il flusso di output, come mostrato di seguito.
$ cat input-file | sed 's/strawberry/blueberry/'
3. Salvataggio delle modifiche ai file
Come abbiamo già detto, sed non cambia affatto i dati di input. Mostra semplicemente i dati trasformati nell'output standard, che sembra essere il terminale Linux per impostazione predefinita. Puoi verificarlo eseguendo il comando seguente.
$ cat input-file
Questo visualizzerà il contenuto originale del file. Tuttavia, supponi di voler rendere permanenti le modifiche. Puoi farlo in diversi modi. Il metodo standard consiste nel reindirizzare l'output sed su un altro file. Il comando successivo salva l'output del precedente comando sed in un file denominato output-file.
$ sed 's/strawberry/blueberry/' input-file >> output-file
Puoi verificarlo usando il seguente comando.
$ cat output-file
4. Salvataggio delle modifiche al file originale
E se volessi salvare l'output di sed nel file originale? È possibile farlo utilizzando -i o –sul posto opzione di questo strumento. I comandi seguenti lo dimostrano utilizzando esempi appropriati.
$ sed -i 's/strawberry/blueberry' input-file $ sed --in-place 's/strawberry/blueberry/' input-file
Entrambi questi comandi precedenti sono equivalenti e scrivono le modifiche apportate da sed al file originale. Tuttavia, se stai pensando di reindirizzare l'output al file originale, non funzionerà come previsto.
$ sed 's/strawberry/blueberry/' input-file > input-file
Questo comando non funzionerà e risulta in un file di input vuoto. Questo perché la shell esegue il reindirizzamento prima di eseguire il comando stesso.
5. Delimitatori di escape
Molti esempi di sed convenzionali usano il carattere "/" come delimitatori. Tuttavia, cosa succede se si desidera sostituire una stringa che contiene questo carattere? L'esempio seguente illustra come sostituire un percorso di un nome file utilizzando sed. Dovremo sfuggire ai delimitatori "/" usando il carattere barra rovesciata.
$ echo '/usr/local/bin/dummy' >> input-file $ sed 's/\/usr\/local\/bin\/dummy/\/usr\/bin\/dummy/' input-file > output-file
Un altro modo facile per sfuggire ai delimitatori è usare un metacarattere diverso. Ad esempio, potremmo usare '_' invece di '/' come delimitatori del comando di sostituzione. È perfettamente valido poiché sed non impone delimitatori specifici. La '/' è usata per convenzione, non come requisito.
$ sed 's_/usr/local/bin/dummy_/usr/bin/dummy/_' input-file
6. Sostituzione di ogni istanza di una stringa
Una caratteristica interessante del comando di sostituzione è che, per impostazione predefinita, sostituirà solo una singola istanza di una stringa su ogni riga.
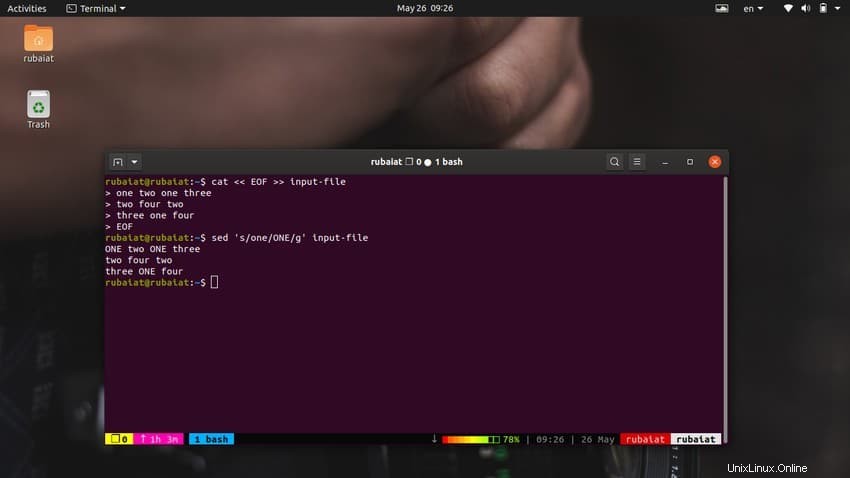
$ cat << EOF >> input-file one two one three two four two three one four EOF
Questo comando sostituirà il contenuto del file di input con alcuni numeri casuali in un formato stringa. Ora, guarda il comando seguente.
$ sed 's/one/ONE/' input-file
Come dovresti vedere, questo comando sostituisce solo la prima occorrenza di "uno" nella prima riga. È necessario utilizzare la sostituzione globale per sostituire tutte le occorrenze di una parola utilizzando sed. Aggiungi semplicemente una 'g' dopo il delimitatore finale di 's '.
$ sed 's/one/ONE/g' input-file
Questo sostituirà tutte le occorrenze della parola "uno" in tutto il flusso di input.
7. Utilizzo della stringa abbinata
A volte gli utenti potrebbero voler aggiungere alcune cose come parentesi o virgolette attorno a una stringa specifica. Questo è facile da fare se sai esattamente cosa stai cercando. Tuttavia, cosa succede se non sappiamo esattamente cosa troveremo? L'utilità sed fornisce una piccola funzionalità per abbinare tale stringa.
$ echo 'one two three 123' | sed 's/123/(123)/'
Qui, stiamo aggiungendo parentesi attorno al 123 usando il comando di sostituzione sed. Tuttavia, possiamo farlo per qualsiasi stringa nel nostro flusso di input utilizzando il metacarattere speciale & , come illustrato dal seguente esempio.
$ echo 'one two three 123' | sed 's/[a-z][a-z]*/(&)/g'
Questo comando aggiungerà parentesi attorno a tutte le parole minuscole nel nostro input. Se ometti la 'g' opzione, sed lo farà solo per la prima parola, non per tutte.
8. Utilizzo di espressioni regolari estese
Nel comando precedente, abbiamo abbinato tutte le parole minuscole usando l'espressione regolare [a-z][a-z]*. Corrisponde a una o più lettere minuscole. Un altro modo per abbinarli sarebbe utilizzare il metacarattere '+' . Questo è un esempio di espressioni regolari estese. Pertanto, sed non li supporterà per impostazione predefinita.
$ echo 'one two three 123' | sed 's/[a-z]+/(&)/g'
Questo comando non funziona come previsto poiché sed non supporta il '+' metacarattere fuori dagli schemi. Devi usare le opzioni -E o -r per abilitare le espressioni regolari estese in sed.
$ echo 'one two three 123' | sed -E 's/[a-z]+/(&)/g' $ echo 'one two three 123' | sed -r 's/[a-z]+/(&)/g'
9. Esecuzione di più sostituzioni
Possiamo usare più di un comando sed contemporaneamente separandoli da ';' (punto e virgola). Questo è molto utile poiché consente all'utente di creare combinazioni di comandi più robuste e ridurre al volo i problemi extra. Il comando seguente ci mostra come sostituire tre stringhe contemporaneamente usando questo metodo.
$ echo 'one two three' | sed 's/one/1/; s/two/2/; s/three/3/'
Abbiamo usato questo semplice esempio per illustrare come eseguire sostituzioni multiple o qualsiasi altra operazione sed per quella materia.
10. Sostituzione insensibile di maiuscole e minuscole
L'utilità sed ci consente di sostituire le stringhe senza distinzione tra maiuscole e minuscole. Per prima cosa, vediamo come sed esegue la seguente semplice operazione di sostituzione.
$ echo 'one ONE OnE' | sed 's/one/1/g' # replaces single one
Il comando di sostituzione può corrispondere solo a un'istanza di "one" e quindi sostituirla. Tuttavia, diciamo che vogliamo che corrisponda a tutte le occorrenze di "uno", indipendentemente dal loro caso. Possiamo affrontare questo problema usando il flag "i" dell'operazione di sostituzione sed.
$ echo 'one ONE OnE' | sed 's/one/1/gi' # replaces all ones
11. Stampa di linee specifiche
Possiamo visualizzare una riga specifica dall'input utilizzando la 'p' comando. Aggiungiamo altro testo al nostro file di input e dimostriamo questo esempio.
$ echo 'Adding some more text to input file for better demonstration' >> input-file
Ora, esegui il comando seguente per vedere come stampare una riga specifica usando 'p'.
$ sed '3p; 6p' input-file
L'output dovrebbe contenere la riga numero tre e sei due volte. Non è quello che ci aspettavamo, giusto? Ciò accade perché, per impostazione predefinita, sed emette tutte le righe del flusso di input, nonché le righe, richieste in modo specifico. Per stampare solo le righe specifiche, dobbiamo sopprimere tutti gli altri output.
$ sed -n '3p; 6p' input-file $ sed --quiet '3p; 6p' input-file $ sed --silent '3p; 6p' input-file
Tutti questi comandi sed sono equivalenti e stampano solo la terza e la sesta riga dal nostro file di input. Quindi, puoi eliminare l'output indesiderato utilizzando uno tra -n , –silenzioso o –silenzioso opzioni.
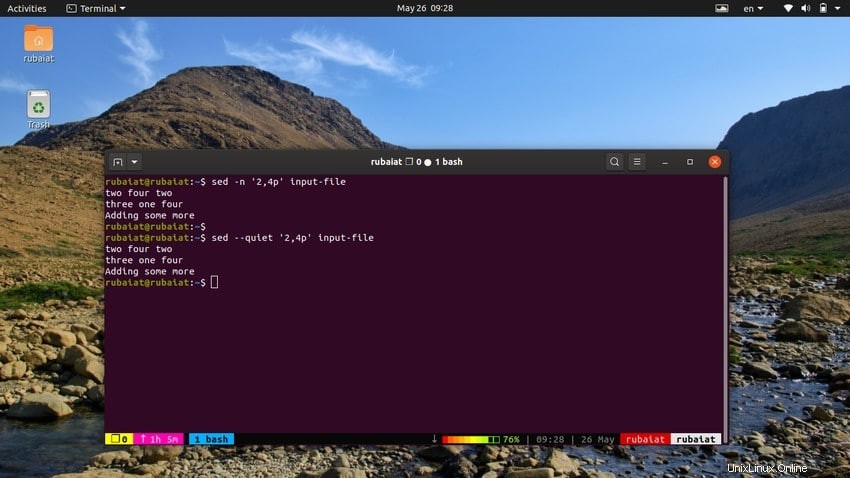
12. Gamma di linee di stampa
Il comando seguente stamperà un intervallo di righe dal nostro file di input. Il simbolo ',' può essere utilizzato per specificare un intervallo di input per sed.
$ sed -n '2,4p' input-file $ sed --quiet '2,4p' input-file $ sed --silent '2,4p' input-file
anche tutti e tre questi comandi sono equivalenti. Stamperanno le righe da due a quattro del nostro file di input.
13. Stampa di righe non consecutive
Si supponga di voler stampare righe specifiche dall'input di testo utilizzando un singolo comando. È possibile gestire tali operazioni in due modi. Il primo consiste nell'unire più operazioni di stampa utilizzando ';' separatore.
$ sed -n '1,2p; 5,6p' input-file
Questo comando stampa le prime due righe del file di input seguite dalle ultime due righe. Puoi farlo anche usando -e opzione di sed. Nota le differenze nella sintassi.
$ sed -n -e '1,2p' -e '5,6p' input-file
14. Stampa ogni riga ennesima
Supponiamo di voler visualizzare ogni seconda riga dal nostro file di input. L'utilità sed lo rende molto semplice fornendo la tilde '~' operatore. Dai una rapida occhiata al comando seguente per vedere come funziona.
$ sed -n '1~2p' input-file
Questo comando funziona stampando la prima riga seguita da ogni seconda riga dell'input. Il comando seguente stampa la seconda riga seguita da ogni terza riga dall'output di un semplice comando ip.
$ ip -4 a | sed -n '2~3p'
15. Sostituzione di testo all'interno di un intervallo
Possiamo anche sostituire del testo solo all'interno di un intervallo specificato nello stesso modo in cui lo abbiamo stampato. Il comando seguente mostra come sostituire gli "uno" con 1 nelle prime tre righe del nostro file di input usando sed.
$ sed '1,3 s/one/1/gi' input-file
Questo comando lascerà inalterato qualsiasi altro "uno". Aggiungi alcune righe che ne contengono una a questo file e prova a verificarlo di persona.
16. Eliminazione di righe dall'input
Il comando ed 'd' ci consente di eliminare righe o intervalli di righe specifici dal flusso di testo o dai file di input. Il comando seguente mostra come eliminare la prima riga dall'output di sed.
$ sed '1d' input-file
Poiché sed scrive solo nell'output standard, questa eliminazione non si rifletterà sul file originale. Lo stesso comando può essere utilizzato per eliminare la prima riga da un flusso di testo multilinea.
$ ps | sed '1d'
Quindi, semplicemente usando la 'd' comando dopo l'indirizzo di riga, possiamo sopprimere l'input per sed.
17. Eliminazione dell'intervallo di linee dall'input
È anche molto facile eliminare un intervallo di righe utilizzando l'operatore ',' insieme a 'd' opzione. Il prossimo comando sed sopprimerà le prime tre righe dal nostro file di input.
$ sed '1,3d' input-file
Possiamo anche eliminare righe non consecutive utilizzando uno dei seguenti comandi.
$ sed '1d; 3d; 5d' input-file
Questo comando mostra la seconda, la quarta e l'ultima riga dal nostro file di input. Il comando seguente omette alcune righe arbitrarie dall'output di un semplice comando IP di Linux.
$ ip -4 a | sed '1d; 3d; 4d; 6d'
18. Eliminazione dell'ultima riga
L'utilità sed ha un semplice meccanismo che ci consente di eliminare l'ultima riga da un flusso di testo o da un file di input. È il '$' simbolo e può essere utilizzato anche per altri tipi di operazioni oltre alla cancellazione. Il comando seguente elimina l'ultima riga dal file di input.
$ sed '$d' input-file
Questo è molto utile poiché spesso potremmo conoscere in anticipo il numero di righe. Funziona in modo simile per gli input della pipeline.
$ seq 3 | sed '$d'
19. Eliminazione di tutte le righe tranne quelle specifiche
Un altro pratico esempio di eliminazione sed consiste nell'eliminare tutte le righe tranne quelle specificate nel comando. Questo è utile per filtrare le informazioni essenziali dai flussi di testo o dall'output di altri comandi del terminale Linux.
$ free | sed '2!d'
Questo comando produrrà solo l'utilizzo della memoria, che si trova sulla seconda riga. Puoi anche fare lo stesso con i file di input, come mostrato di seguito.
$ sed '1,3!d' input-file
Questo comando cancella tutte le righe tranne le prime tre dal file di input.
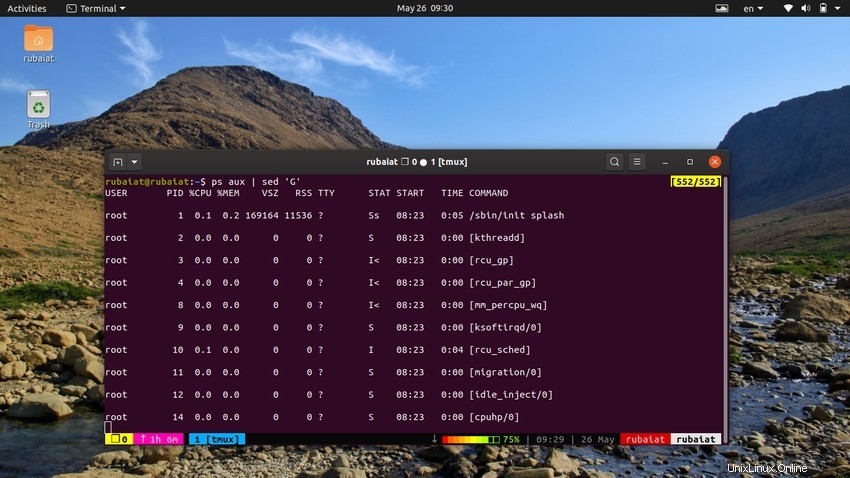
20. Aggiunta di righe vuote
A volte il flusso di input potrebbe essere troppo concentrato. È possibile utilizzare l'utilità sed per aggiungere righe vuote tra l'input in questi casi. L'esempio successivo aggiunge una riga vuota tra ogni riga dell'output del comando ps.
$ ps aux | sed 'G'
La 'G' comando aggiunge questa riga vuota. Puoi aggiungere più righe vuote utilizzando più di una 'G' comando per sed.
$ sed 'G; G' input-file
Il comando seguente mostra come aggiungere una riga vuota dopo un numero di riga specifico. Aggiungerà una riga vuota dopo la terza riga del nostro file di input.
$ sed '3G' input-file
21. Sostituzione del testo su righe specifiche
L'utilità sed consente agli utenti di sostituire del testo su una riga particolare. Ciò è utile in diversi scenari. Diciamo che vogliamo sostituire la parola "uno" sulla terza riga del nostro file di input. Possiamo usare il seguente comando per farlo.
$ sed '3 s/one/1/' input-file
Il '3' prima dell'inizio delle 's' comando specifica che vogliamo sostituire solo la parola che si trova sulla terza riga.
22. Sostituzione dell'ennesima parola di una stringa
Possiamo anche usare il comando sed per sostituire l'n-esima occorrenza di un pattern per una data stringa. L'esempio seguente lo illustra utilizzando un singolo esempio di una riga in bash.
$ echo 'one one one one one one' | sed 's/one/1/3'
Questo comando sostituirà il terzo "uno" con il numero 1. Funziona allo stesso modo per i file di input. Il comando seguente sostituisce gli ultimi "due" dalla seconda riga del file di input.
$ cat input-file | sed '2 s/two/2/2'
Per prima cosa selezioniamo la seconda riga e poi specifichiamo quale occorrenza del pattern modificare.
23. Aggiunta di nuove righe
Puoi facilmente aggiungere nuove righe al flusso di input utilizzando il comando 'a' . Dai un'occhiata al semplice esempio qui sotto per vedere come funziona.
$ sed 'a new line in input' input-file
Il comando precedente aggiungerà la stringa "nuova riga in input" dopo ogni riga del file di input originale. Tuttavia, questo potrebbe non essere quello che intendevi. Puoi aggiungere nuove righe dopo una riga specifica utilizzando la seguente sintassi.
$ sed '3 a new line in input' input-file
24. Inserimento di nuove righe
Possiamo anche inserire righe invece di aggiungerle. Il comando seguente inserisce una nuova riga prima di ogni riga di input.
$ seq 5 | sed 'i 888'
La 'i' comando fa inserire la stringa 888 prima di ogni riga dell'output della seq. Per inserire una riga prima di una specifica riga di input, utilizzare la seguente sintassi.
$ seq 5 | sed '3 i 333'
Questo comando aggiungerà il numero 333 prima della riga che ne contiene effettivamente tre. Questi sono semplici esempi di inserimento di righe. Puoi facilmente aggiungere stringhe facendo corrispondere le linee usando i modelli.
25. Modifica delle righe di input
Possiamo anche modificare le linee di un flusso di input direttamente utilizzando la 'c' comando dell'utilità sed. Questo è utile quando sai esattamente quale riga sostituire e non vuoi far corrispondere la riga usando espressioni regolari. L'esempio seguente cambia la terza riga dell'output del comando seq.
$ seq 5 | sed '3 c 123'
Sostituisce il contenuto della terza riga, che è 3, con il numero 123. Il prossimo esempio ci mostra come modificare l'ultima riga del nostro file di input usando 'c' .
$ sed '$ c CHANGED STRING' input-file
Possiamo anche usare regex per selezionare il numero di riga da modificare. Il prossimo esempio lo illustra.
$ sed '/demo*/ c CHANGED TEXT' input-file
26. Creazione di file di backup per l'input
Se desideri trasformare del testo e salvare le modifiche nel file originale, ti consigliamo vivamente di creare file di backup prima di procedere. Il comando seguente esegue alcune operazioni sed sul nostro file di input e lo salva come originale. Inoltre, per precauzione, crea un backup chiamato input-file.old.
$ sed -i.old 's/one/1/g; s/two/2/g; s/three/3/g' input-file
Il -i l'opzione scrive le modifiche apportate da sed al file originale. La parte del suffisso .old è responsabile della creazione del documento input-file.old.
27. Linee di stampa basate su motivi
Supponiamo di voler stampare tutte le righe da un input in base a un determinato modello. Questo è abbastanza facile quando combiniamo i comandi sed 'p' con -n opzione. L'esempio seguente lo illustra utilizzando il file di input.
$ sed -n '/^for/ p' input-file
Questo comando cerca il modello "for" all'inizio di ogni riga e stampa solo le righe che iniziano con esso. Il '^' carattere è un carattere speciale di espressione regolare noto come ancora. Specifica che il modello deve essere posizionato all'inizio della riga.
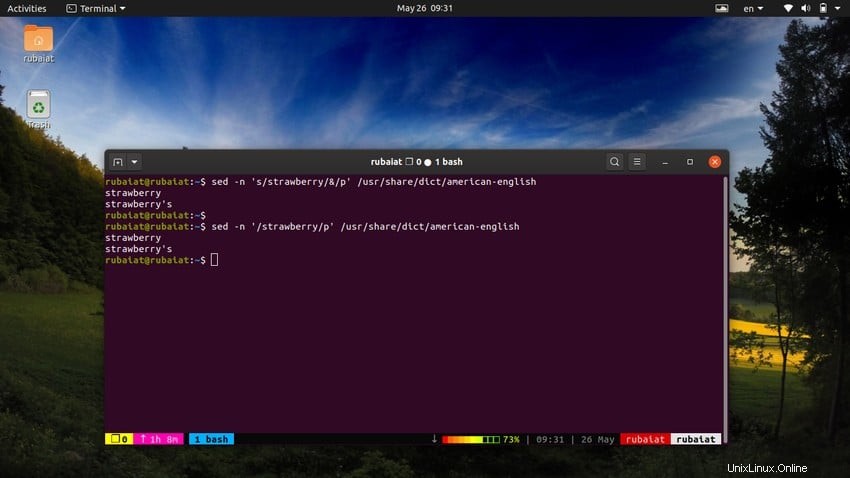
28. Utilizzo di SED come alternativa al GREP
Il comando grep in Linux cerca un modello particolare in un file e, se trovato, visualizza la riga. Possiamo emulare questo comportamento usando l'utilità sed. Il comando seguente lo illustra usando un semplice esempio.
$ sed -n 's/strawberry/&/p' /usr/share/dict/american-english
Questo comando individua la parola fragola nel inglese americano file del dizionario. Funziona cercando il motivo fragola e quindi utilizza una stringa abbinata accanto alla 'p' comando per stamparlo. Il -n flag sopprime tutte le altre righe nell'output. Possiamo rendere questo comando più semplice usando la seguente sintassi.
$ sed -n '/strawberry/p' /usr/share/dict/american-english
29. Aggiunta di testo da file
La 'r' il comando dell'utilità sed ci consente di aggiungere il testo letto da un file al flusso di input. Il comando seguente genera un flusso di input per sed usando il comando seq e aggiunge i testi contenuti da input-file a questo flusso.
$ seq 5 | sed 'r input-file'
Questo comando aggiungerà il contenuto del file di input dopo ogni sequenza di input consecutiva prodotta da seq. Utilizzare il comando successivo per aggiungere il contenuto dopo i numeri generati da seq.
$ seq 5 | sed '$ r input-file'
Puoi usare il comando seguente per aggiungere il contenuto dopo l'n-esima riga di input.
$ seq 5 | sed '3 r input-file'
30. Scrivere modifiche ai file
Supponiamo di avere un file di testo che contiene un elenco di indirizzi web. Supponiamo che alcuni di essi inizino con www, alcuni https e altri http. Possiamo cambiare tutti gli indirizzi che iniziano con www in modo che inizino con https e salvare solo quelli che sono stati modificati in un file completamente nuovo.
$ sed 's/www/https/ w modified-websites' websites
Ora, se controlli il contenuto del file modified-websites, troverai solo gli indirizzi che sono stati modificati da sed. Il 'w nomefile ' opzione fa in modo che sed scriva le modifiche al nome file specificato. È utile quando hai a che fare con file di grandi dimensioni e desideri archiviare i dati modificati separatamente.
31. Utilizzo dei file di programma SED
A volte, potrebbe essere necessario eseguire una serie di operazioni sed su un determinato set di input. In questi casi, è meglio scrivere un file di programma contenente tutti i diversi script sed. È quindi possibile richiamare semplicemente questo file di programma utilizzando -f opzione dell'utilità sed.
$ cat << EOF >> sed-script s/a/A/g s/e/E/g s/i/I/g s/o/O/g s/u/U/g EOF
Questo programma sed cambia tutte le vocali minuscole in maiuscole. Puoi eseguirlo utilizzando la sintassi seguente.
$ sed -f sed-script input-file $ sed --file=sed-script < input-file
32. Utilizzo di comandi SED multiriga
Se stai scrivendo un programma sed di grandi dimensioni che si estende su più righe, dovrai citarle correttamente. La sintassi differisce leggermente tra le diverse shell Linux. Fortunatamente, è molto semplice per la shell bourne e i suoi derivati (bash).
$ sed ' s/a/A/g s/e/E/g s/i/I/g s/o/O/g s/u/U/g' < input-file
In alcune shell, come la shell C (csh), è necessario proteggere le virgolette usando il carattere backslash(\).
$ sed 's/a/A/g \ s/e/E/g \ s/i/I/g \ s/o/O/g \ s/u/U/g' < input-file
33. Stampa dei numeri di riga
Se vuoi stampare il numero di riga contenente una stringa specifica, puoi cercarlo utilizzando un modello e stamparlo molto facilmente. Per questo, dovrai utilizzare il '=' comando dell'utilità sed.
$ sed -n '/ion*/ =' < input-file
Questo comando cercherà il modello dato nel file di input e ne stamperà il numero di riga nell'output standard. Puoi anche usare una combinazione di grep e awk per risolvere questo problema.
$ cat -n input-file | grep 'ion*' | awk '{print $1}' Puoi usare il comando seguente per stampare il numero totale di righe nel tuo input.
$ sed -n '$=' input-file
34. Impedire la sovrascrittura dei collegamenti simbolici
Il sed 'i' o '–sul posto Il comando ' spesso sovrascrive qualsiasi collegamento di sistema con file regolari. Questa è una situazione indesiderata in molti casi e quindi gli utenti potrebbero voler evitare che ciò accada. Fortunatamente, sed fornisce una semplice opzione della riga di comando per disabilitare la sovrascrittura dei collegamenti simbolici.
$ echo 'apple' > fruit $ ln --symbolic fruit fruit-link $ sed --in-place --follow-symlinks 's/apple/banana/' fruit-link $ cat fruit
Quindi, puoi impedire la sovrascrittura dei link simbolici usando –follow-symlinks opzione dell'utilità sed. In questo modo, puoi preservare i collegamenti simbolici durante l'elaborazione del testo.
35. Stampa di tutti i nomi utente da /etc/passwd
Il /etc/passwd contiene informazioni a livello di sistema per tutti gli account utente in Linux. Possiamo ottenere un elenco di tutti i nomi utente disponibili in questo file utilizzando un semplice programma sed one-liner. Dai un'occhiata da vicino all'esempio seguente per vedere come funziona.
$ sed 's/\([^:]*\).*/\1/' /etc/passwd
Abbiamo utilizzato un modello di espressione regolare per ottenere il primo campo da questo file eliminando tutte le altre informazioni. Qui è dove risiedono i nomi utente in /etc/passwd file.
36. Eliminazione di righe commentate dall'input
Molti strumenti di sistema, così come applicazioni di terze parti, sono dotati di file di configurazione. Questi file di solito contengono molti commenti che descrivono i parametri in dettaglio. Tuttavia, a volte potresti voler visualizzare solo le opzioni di configurazione mantenendo i commenti originali al loro posto.
$ cat ~/.bashrc | sed -e 's/#.*//;/^$/d'
Questo comando cancella le righe commentate dal file di configurazione bash. I commenti sono contrassegnati da un segno '#' precedente. Quindi, abbiamo rimosso tutte queste linee usando un semplice modello regex. Se i commenti sono contrassegnati da un simbolo diverso, sostituisci il "#" nel modello sopra con quel simbolo specifico.
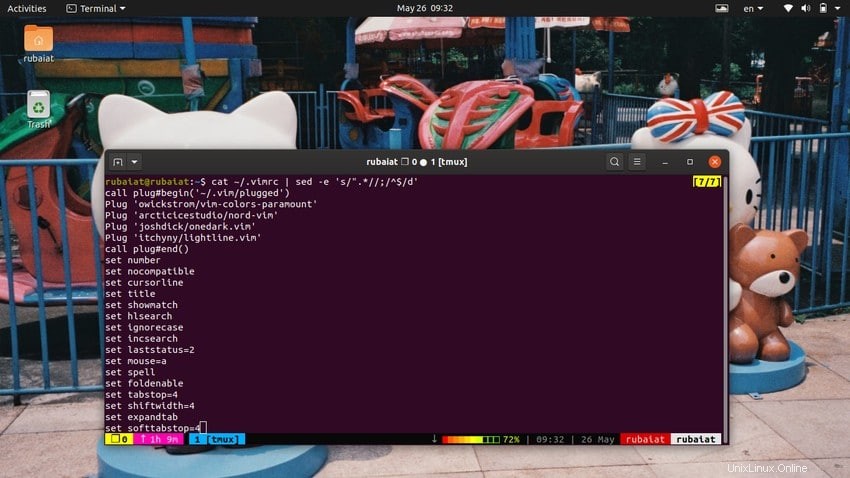
$ cat ~/.vimrc | sed -e 's/".*//;/^$/d'
Questo rimuoverà i commenti dal file di configurazione di vim, che inizia con un simbolo di doppia virgoletta (").
37. Eliminazione degli spazi bianchi dall'input
Molti documenti di testo sono pieni di spazi bianchi non necessari. Spesso sono il risultato di una cattiva formattazione e possono rovinare i documenti complessivi. Fortunatamente, sed consente agli utenti di rimuovere abbastanza facilmente queste spaziature indesiderate. Puoi utilizzare il comando successivo per rimuovere gli spazi bianchi iniziali da un flusso di input.
$ sed 's/^[ \t]*//' whitespace.txt
Questo comando rimuoverà tutti gli spazi bianchi iniziali dal file whitespace.txt. Se vuoi rimuovere gli spazi vuoti finali, usa invece il seguente comando.
$ sed 's/[ \t]*$//' whitespace.txt
Puoi anche usare il comando sed per rimuovere contemporaneamente gli spazi bianchi iniziali e finali. Il comando seguente può essere utilizzato per eseguire questa attività.
$ sed 's/^[ \t]*//;s/[ \t]*$//' whitespace.txt
38. Creazione di offset di pagina con SED
Se hai un file di grandi dimensioni con zero padding frontali, potresti voler creare degli offset di pagina per esso. Gli offset di pagina sono semplicemente spazi bianchi iniziali che ci aiutano a leggere le righe di input senza sforzo. Il comando seguente crea un offset di 5 spazi vuoti.
$ sed 's/^/ /' input-file
Basta aumentare o ridurre la spaziatura per specificare un offset diverso. Il comando successivo riduce l'offset della pagina a 3 righe vuote.
$ sed 's/^/ /' input-file
39. Inversione delle linee di input
Il comando seguente ci mostra come usare sed per invertire l'ordine delle righe in un file di input. Emula il comportamento del tac di Linux comando.
$ sed '1!G;h;$!d' input-file
Questo comando inverte le righe del documento della riga di input. Può anche essere fatto utilizzando un metodo alternativo.
$ sed -n '1!G;h;$p' input-file
40. Inversione dei caratteri di input
Possiamo anche usare l'utilità sed per invertire i caratteri sulle righe di input. Questo invertirà l'ordine di ogni carattere consecutivo nel flusso di input.
$ sed '/\n/!G;s/\(.\)\(.*\n\)/&\2\1/;//D;s/.//' input-file
Questo comando emula il comportamento di Linux rev comando. Puoi verificarlo eseguendo il comando seguente dopo quello sopra.
$ rev input-file
41. Unire coppie di linee di input
Il seguente semplice comando sed unisce due righe consecutive di un file di input come una singola riga. È utile quando si dispone di un testo di grandi dimensioni contenente linee divise.
$ sed '$!N;s/\n/ /' input-file $ tail -15 /usr/share/dict/american-english | sed '$!N;s/\n/ /'
È utile in numerose attività di manipolazione del testo.
42. Aggiunta di righe vuote su ogni N-esima riga di input
Puoi aggiungere una riga vuota su ogni riga n-esima del file di input molto facilmente usando sed. I comandi successivi aggiungono una riga vuota su ogni terza riga del file di input.
$ sed 'n;n;G;' input-file
Utilizzare quanto segue per aggiungere la riga vuota su ogni seconda riga.
$ sed 'n;G;' input-file
43. Stampa delle ultime N-esime righe
In precedenza, abbiamo utilizzato i comandi sed per stampare le righe di input in base al numero di riga, agli intervalli e al modello. Possiamo anche usare sed per emulare il comportamento dei comandi head o tail. L'esempio successivo stampa le ultime 3 righe del file di input.
$ sed -e :a -e '$q;N;4,$D;ba' input-file
È simile al file di input tail -3 del comando tail sotto.
44. Stampa righe contenenti un numero specifico di caratteri
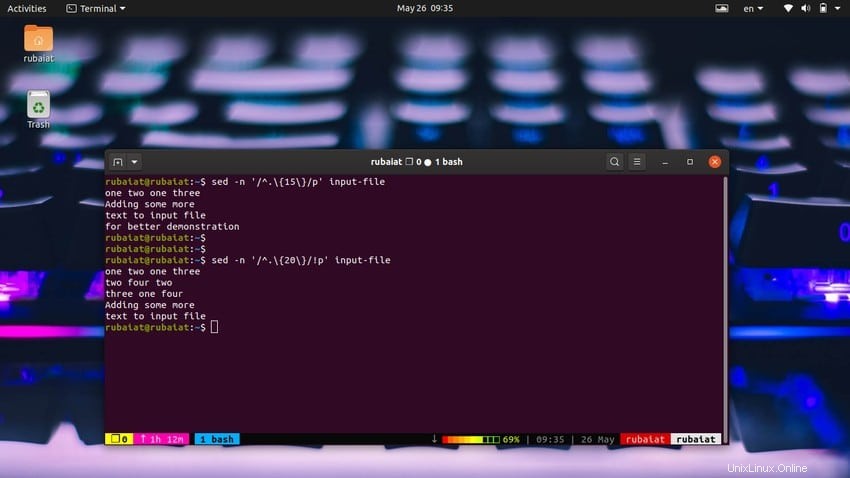
È molto facile stampare le righe in base al conteggio dei caratteri. Il seguente semplice comando stamperà righe che contengono 15 o più caratteri.
$ sed -n '/^.\{15\}/p' input-file Utilizzare il comando seguente per stampare righe con meno di 20 caratteri.
$ sed -n '/^.\{20\}/!p' input-file Possiamo anche farlo in un modo più semplice usando il metodo seguente.
$ sed '/^.\{20\}/d' input-file
45. Eliminazione di righe duplicate
The following sed example shows us to emulate the behavior of the Linux uniq comando. It deletes any two consecutive duplicate lines from the input.
$ sed '$!N; /^\(.*\)\n\1$/!P; D' input-file
However, sed can not delete all duplicate lines if the input is not sorted. Although you can sort the text using the sort command and then connect the output to sed using a pipe, it will change the orientation of the lines.
46. Deleting All Blank Lines
If your text file contains a lot of unnecessary blank lines, you may delete them using the sed utility. The below command demonstrates this.
$ sed '/^$/d' input-file $ sed '/./!d' input-file
Both of these commands will delete any blank lines present in the specified file.
47. Deleting Last Lines of Paragraphs
You can delete the last line of all paragraphs using the following sed command. We will use a dummy filename for this example. Replace this with the name of an actual file that contains some paragraphs.
$ sed -n '/^$/{p;h;};/./{x;/./p;}' paragraphs.txt 48. Displaying the Help Page
The help page contains summarized information on all available options and usage of the sed program. You can invoke this by using the following syntax.
$ sed -h $ sed --help
You can use any of these two commands to find a nice, compact overview of the sed utility.
49. Displaying the Manual Page
The manual page provides an in-depth discussion of sed, its usage, and all available options. You should read this carefully to understand sed clearly.
$ man sed
50. Displaying Version Information
The –version option of sed allows us to view which version of sed is installed in our machine. It is useful when debugging errors and reporting bugs.
$ sed --version
The above command will display the version information of the sed utility in your system.
Pensieri finali
The sed command is one of the most widely used text manipulation tools provided by Linux distributions. It is one of the three primary filtering utilities in Unix, alongside grep and awk. We have outlined 50 simple yet useful examples to help readers get started with this amazing tool. We highly recommend users to try these commands themselves to gain practical insights. Additionally, try tweaking the examples given in this guide and examine their effect. It will help you master sed quickly. Hopefully, you’ve learned the basics of sed clearly. Don’t forget to comment below if you’ve any questions.