Il compito principale di un robot Web è eseguire la scansione o la scansione di siti Web e pagine per informazioni; lavorano instancabilmente per raccogliere dati per motori di ricerca e altre applicazioni. Per alcuni, c'è una buona ragione per tenere le pagine lontane dai motori di ricerca. Sia che tu voglia ottimizzare l'accesso al tuo sito o lavorare su un sito di sviluppo senza comparire nei risultati di Google, una volta implementato, il file robots.txt consente ai crawler web e ai bot di sapere quali informazioni possono raccogliere.
Cos'è un file Robots.txt?
Un robots.txt è un file di un sito Web di testo normale nella radice del tuo sito che segue lo standard di esclusione dei robot. Ad esempio, www.tuodominio.com avrà un file robots.txt all'indirizzo www.tuodominio.com/robots.txt. Il file è costituito da una o più regole che consentono o bloccano l'accesso ai crawler, vincolandoli a un percorso file specificato nel sito Web. Per impostazione predefinita, tutti i file possono essere sottoposti a scansione se non diversamente specificato.
Il file robots.txt è uno dei primi aspetti analizzati dai crawler. È importante notare che il tuo sito può avere un solo file robots.txt. Il file viene implementato su una o più pagine o su un intero sito per scoraggiare i motori di ricerca dal mostrare dettagli sul tuo sito web.
Questo articolo fornirà cinque passaggi per creare un file robots.txt e la sintassi necessaria per tenere a bada i bot.
Come impostare un file Robots.txt
1. Crea un file Robots.txt
Devi avere accesso alla radice del tuo dominio. Il tuo provider di web hosting può aiutarti a stabilire se hai o meno l'accesso appropriato.
La parte più importante del file è la sua creazione e posizione. Usa qualsiasi editor di testo per creare un file robots.txt e puoi trovarlo su:
- La radice del tuo dominio:www.tuodominio.com/robots.txt.
- I tuoi sottodomini:page.yourdomain.com/robots.txt.
- Porte non standard:www.yourdomain.com:881/robots.txt.
Infine, dovrai assicurarti che il tuo file robots.txt sia un file di testo con codifica UTF-8. Google e altri popolari motori di ricerca e crawler potrebbero ignorare i caratteri al di fuori dell'intervallo UTF-8, rendendo le tue regole robots.txt non valide.
2. Imposta il tuo agente utente Robots.txt
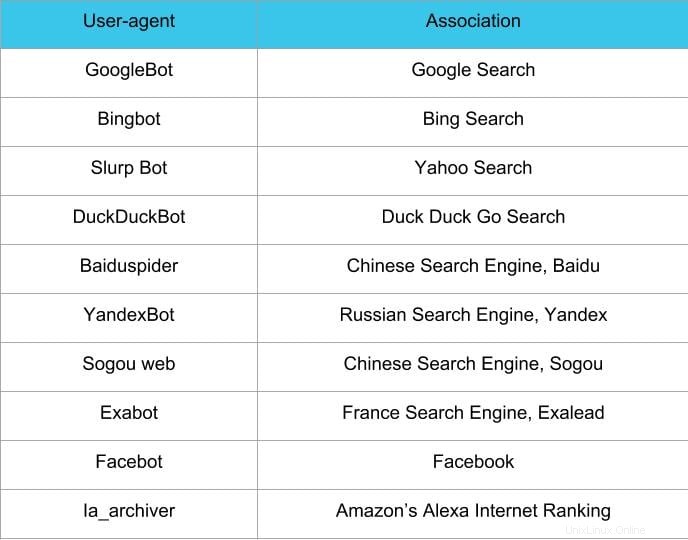
Il passaggio successivo su come creare file robots.txt consiste nell'impostare lo agente utente . Lo agente utente riguarda i crawler web o i motori di ricerca che desideri consentire o bloccare. Diverse entità potrebbero essere l'agente utente . Di seguito abbiamo elencato alcuni crawler, nonché le loro associazioni.
Esistono tre modi diversi per creare uno agente utente all'interno del tuo file robots.txt.
Creazione di un agente utente
La sintassi che usi per impostare lo user agent è User-agent:NameOfBot . Sotto, DuckDuckBot è l'unico agente utente stabilito.
# Example of how to set user-agent
User-agent: DuckDuckBotCreazione di più di un agente utente
Se dobbiamo aggiungerne più di uno, segui la stessa procedura che hai fatto per DuckDuckBot user-agent su una riga successiva, inserendo il nome dello user-agent aggiuntivo . In questo esempio, abbiamo utilizzato Facebot.
#Example of how to set more than one user-agent
User-agent: DuckDuckBot
User-agent: FacebotImpostazione di tutti i crawler come User-agent
Per bloccare tutti i bot o crawler, sostituisci il nome del bot con un asterisco (*).
#Example of how to set all crawlers as user-agent
User-agent: *3. Imposta le regole sul tuo file Robots.txt
Un file robots.txt viene letto in gruppi. Un gruppo specificherà chi è l'agente utente è e ha una regola o direttiva per indicare quali file o directory sono user-agent può o non può accedere.
Ecco le direttive utilizzate:
- Non consentire :la direttiva che fa riferimento a una pagina o directory relativa al tuo dominio principale di cui non desideri il nome user-agent gattonare. Inizierà con una barra (/) seguita dall'URL della pagina intera. Lo finirai con una barra solo se si riferisce a una directory e non a un'intera pagina. Puoi utilizzare uno o più disallow impostazioni per regola.
- Consenti :La direttiva fa riferimento a una pagina o directory relativa al tuo dominio principale di cui vuoi che venga denominata user-agent gattonare. Ad esempio, dovresti utilizzare consenti direttiva per ignorare il disallow regola. Inizierà anche con una barra (/) seguita dall'URL della pagina intera. Lo finirai con una barra solo se si riferisce a una directory e non a un'intera pagina. Puoi utilizzare uno o più consenti impostazioni per regola.
- Mappa del sito :La direttiva sulla mappa del sito è facoltativa e fornisce la posizione della mappa del sito per il sito web. L'unica condizione è che deve essere un URL completo. Puoi usarne zero o più, a seconda di ciò che è necessario.
I web crawler elaborano i gruppi dall'alto verso il basso. Come accennato in precedenza, accedono a qualsiasi pagina o directory non esplicitamente impostata su non consentire . Pertanto, aggiungi Disallow:/ sotto lo agente utente informazioni in ogni gruppo per impedire a quegli agenti utente specifici di eseguire la scansione del tuo sito web.
# Example of how to block DuckDuckBot
User-agent: DuckDuckBot
Disallow: /
#Example of how to block more than one user-agent
User-agent: DuckDuckBot
User-agent: Facebot
Disallow: /
#Example of how to block all crawlers
User-agent: *
Disallow: /Per bloccare un sottodominio specifico da tutti i crawler, aggiungi una barra e l'URL completo del sottodominio nella regola di non autorizzazione.
# Example
User-agent: *
Disallow: /https://page.yourdomain.com/robots.txtSe vuoi bloccare una directory, segui la stessa procedura aggiungendo una barra e il nome della directory, ma poi termina con un'altra barra.
# Example
User-agent: *
Disallow: /images/Infine, se desideri che tutti i motori di ricerca raccolgano informazioni su tutte le pagine del tuo sito, puoi creare un consenti o non consentire regola, ma assicurati di aggiungere una barra quando usi consenti regola. Di seguito sono riportati esempi di entrambe le regole.
# Allow example to allow all crawlers
User-agent: *
Allow: /
# Disallow example to allow all crawlers
User-agent: *
Disallow:4. Carica il tuo file Robots.txt
I siti Web non vengono forniti automaticamente con un file robots.txt in quanto non è richiesto. Dopo aver deciso di crearne uno, carica il file nella directory principale del tuo sito web. Il caricamento dipende dalla struttura dei file del tuo sito e dal tuo ambiente di hosting web. Contatta il tuo provider di hosting per ricevere assistenza su come caricare il tuo file robots.txt.
5. Verifica che il tuo file Robots.txt funzioni correttamente
Esistono diversi modi per testare e assicurarsi che il file robots.txt funzioni correttamente. Con uno qualsiasi di questi, puoi vedere eventuali errori nella tua sintassi o logica. Eccone alcuni:
- Tester robots.txt di Google nella loro Search Console.
- Il validatore robots.txt e lo strumento di test di Merkle, Inc.
- Strumento di test robots.txt di Ryte.
Bonus:utilizzo di Robots.txt in WordPress
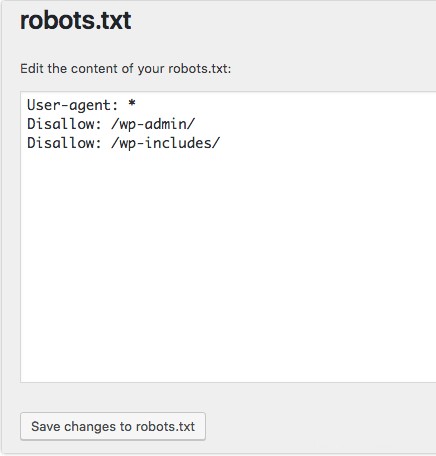
Se utilizzi il plugin Yoast SEO di WordPress, vedrai una sezione all'interno della finestra di amministrazione per creare un file robots.txt.
Accedi al back-end del tuo sito Web WordPress e accedi a Strumenti sotto il SEO sezione, quindi fai clic su Editor di file .
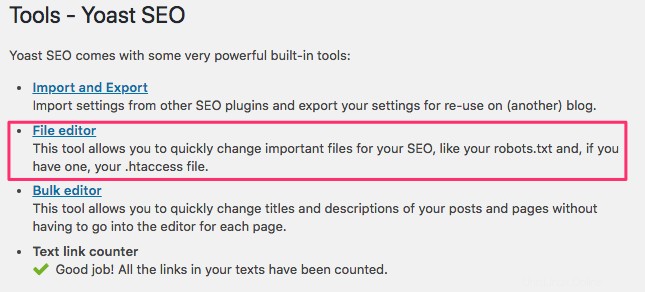
Segui la stessa sequenza di prima per stabilire i tuoi programmi utente e le regole. Di seguito, abbiamo bloccato i web crawler dalle directory wp-admin e wp-includes di WordPress, consentendo comunque a utenti e bot di vedere altre pagine del sito. Al termine, fai clic su Salva modifiche in robots.txt per attivare il file robots.txt.