Intrecceremo boccioli, fiori e travi
Che brillano sull'orlo della fontana e fanno
Strane combinazioni di cose comuni
"Prometheus Unbound" di Percy Bysshe Shelley
Benvenuto nel mondo della raccolta delle metriche e del monitoraggio delle prestazioni. Come per la maggior parte delle cose IT, interi settori di mercato sono stati creati per vendere questi strumenti. E, naturalmente, diverse utilità open source servono allo stesso scopo. È uno di questi strumenti open source che esamineremo.
Cos'è Prometeo?
Prometheus è uno strumento di raccolta di metriche e avvisi sviluppato e rilasciato in open source da SoundCloud. Prometheus è simile nel design al sistema di monitoraggio Borgmon di Google e un sistema relativamente modesto può gestire la raccolta di centinaia di migliaia di metriche al secondo. Ottimizzato e distribuito correttamente, un cluster Prometheus può raccogliere milioni di metriche al secondo.
Prometeo è composto da circa quattro parti:
- La stessa app Prometheus principale che è responsabile dello scraping delle metriche, dell'archiviazione nel database e (facoltativamente) del loro recupero quando richiesto.
- Il back-end del database è un database Time Series interno. Questo database viene sempre utilizzato, ma i dati possono anche essere inviati a backend di archiviazione remoti.
- Gli esportatori sono programmi esterni opzionali che acquisiscono dati da una varietà di fonti e li convertono in parametri che Prometheus può analizzare.
- Gli esportatori sono progettati appositamente per lavorare con applicazioni e hardware specifici.
- AlertManager è un sistema di gestione degli avvisi fornito con Prometheus.
- Le librerie client possono essere utilizzate per strumentare applicazioni personalizzate.
Dico "circa" quattro parti perché molte applicazioni aggiuntive vengono spesso utilizzate con un cluster Prometheus standard. Se hai bisogno o desideri migliori capacità di rappresentazione grafica, è possibile distribuire applicazioni come Grafana. Se è necessario archiviare le metriche per lunghi periodi di tempo, vale la pena considerare i backend di archiviazione remota. E la lista continua. Per questo articolo, tuttavia, ci concentreremo sullo stesso Prometeo con una piccola deviazione negli esportatori.
[ Potrebbe interessarti anche: 6 competenze di amministratore di sistema necessarie agli sviluppatori web ]
Cos'è una metrica?
Prima di arrivarci, dobbiamo capire perché esiste qualcosa come Prometeo. Quindi iniziamo con una domanda:cosa sono le metriche? In poche parole, le metriche misurano qualcosa. Ad esempio, il tempo impiegato per leggere questo articolo è una metrica. Il numero di parole è una metrica. Il numero medio di lettere nelle parole di questo articolo è una metrica.
Tuttavia, queste metriche sono abbastanza statiche e non sono qualcosa per cui avresti necessariamente bisogno di un sistema come Prometheus. Prometheus eccelle in metriche che cambiano nel tempo. Ad esempio, cosa succede se volessi sapere quante "visualizzazioni" sta ottenendo questo articolo? O se volessi sapere quanto traffico entra e esce dalla tua rete? O quanti cicli di compilazione e distribuzione si verificano ogni ora? Tutti questi sono parametri che possono essere inseriti in Prometheus.
Ora che capiamo cos'è una metrica, diamo un'occhiata a come Prometheus ottiene le metriche che deve archiviare. La prima cosa di cui ha bisogno Prometheus è un bersaglio . I target sono gli endpoint che forniscono le metriche archiviate da Prometheus. Questi endpoint possono essere l'effettivo endpoint monitorato oppure possono essere un middleware noto come esportatore. Gli endpoint possono essere forniti tramite una configurazione statica oppure possono essere "trovati" tramite un processo chiamato rilevamento del servizio. La scoperta del servizio è un argomento più avanzato per un articolo futuro.
Una volta che Prometheus ha un elenco di endpoint, può iniziare a recuperare le metriche da essi. Prometheus recupera le metriche in modo molto semplice; una semplice richiesta HTTP. La configurazione punta a una posizione specifica sull'endpoint che fornisce un flusso di testo che identifica la metrica e il suo valore corrente. Prometheus legge questo flusso di testo, ignora le righe che iniziano con un # come commenti e archivia le metriche che riceve in un database locale.
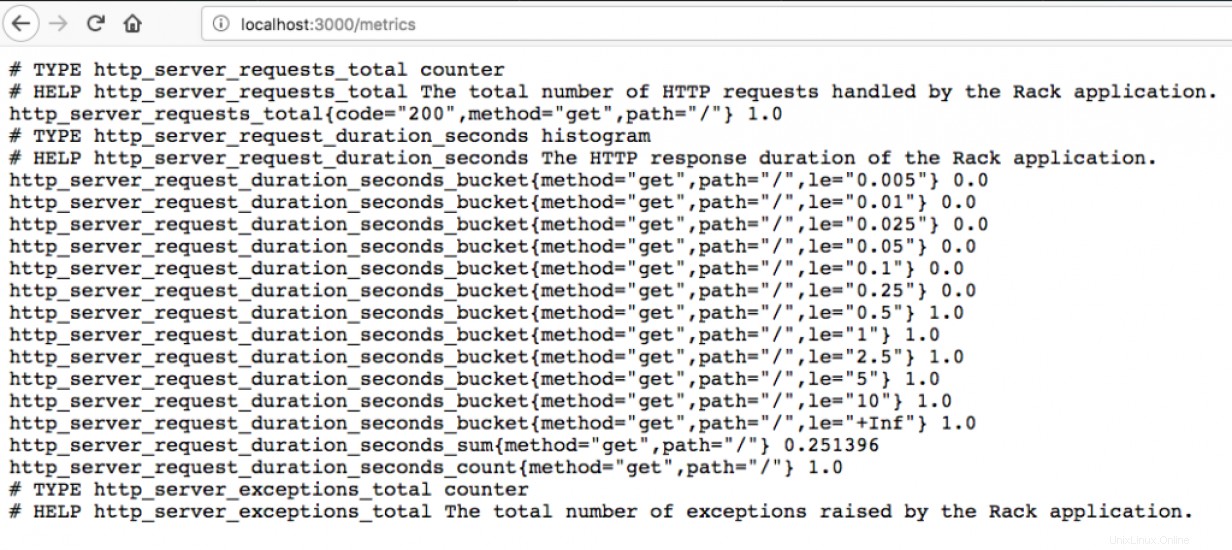
Una breve deviazione sugli esportatori
Prometheus può utilizzare HTTP solo per comunicare con gli endpoint per la raccolta delle metriche. Cosa succede quando si tenta di monitorare un router o uno switch che comunica solo tramite SNMP? O forse vuoi monitorare un servizio cloud che non ha un endpoint di metriche Prometheus nativo? Fortunatamente, c'è una soluzione:gli esportatori.
Gli esportatori sono disponibili in molte forme e dimensioni. Questi sono piccoli programmi appositamente progettati per stare tra Prometheus e tutto ciò che si desidera monitorare che non supporta nativamente Prometheus. Alcuni esportatori restano inattivi finché Prometheus non li interroga per i dati. Quando ciò accade, l'esportatore raggiunge il dispositivo che sta monitorando, ottiene i dati rilevanti e li converte in un formato che Prometheus può ingerire. Altri esportatori eseguono il polling dei dispositivi automaticamente, memorizzando nella cache i risultati in locale affinché Prometheus li raccolga in un secondo momento.
Indipendentemente dal design, gli esportatori fungono da traduttori tra Prometheus e gli endpoint che desideri monitorare. È probabile che se stai cercando di monitorare un dispositivo o un'applicazione comune, ci sia un esportatore là fuori.
Archiviazione dati
Prometheus utilizza un tipo speciale di database sul back-end noto come database di serie temporali. In poche parole, questo database è ottimizzato per archiviare e recuperare dati organizzati come valori per un periodo di tempo. Le metriche sono un ottimo esempio del tipo di dati che memorizzeresti in un database di questo tipo.
Anche l'archiviazione esterna è un'opzione. Ci sono molte scelte, come Thanos, Cortex e VictoriaMetrics che offrono una varietà di vantaggi. Uno dei vantaggi principali è la centralizzazione delle metriche raccolte e l'archiviazione a lungo termine. Strumenti come Grafana possono interrogare direttamente queste soluzioni di archiviazione di terze parti.
Quindi hai un sacco di metriche...
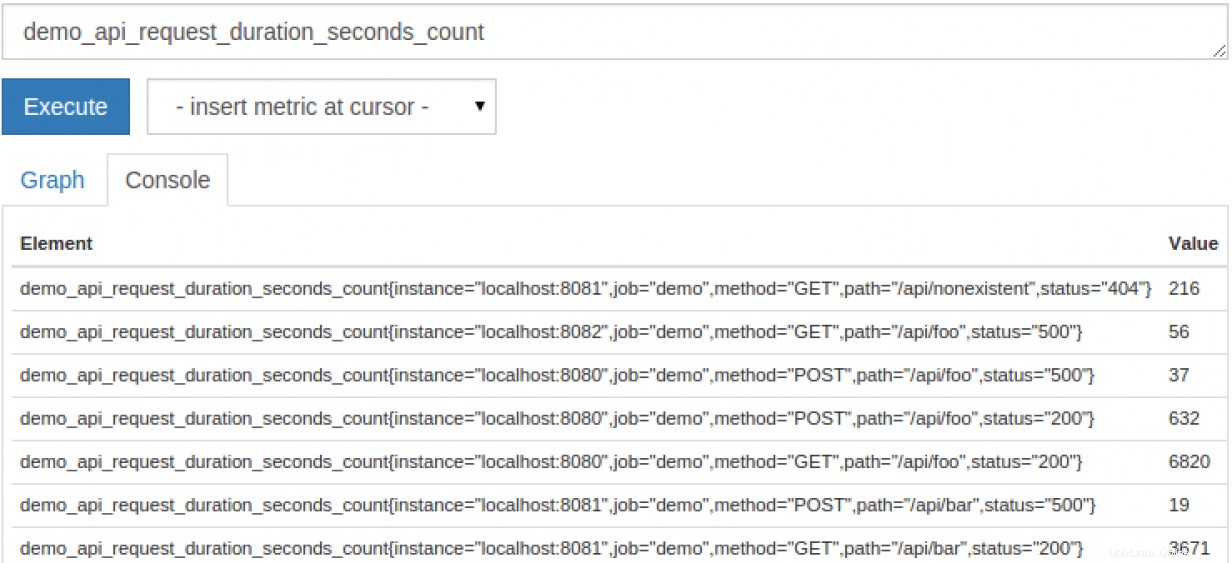
Ora che sei un esperto di Prometheus e lo hai in grado di memorizzare le metriche, come usi questi dati? Proprio come un database SQL, Prometheus ha un linguaggio di query personalizzato noto come PromQL. PromQL è piuttosto semplice per metriche semplici ma ha molta complessità quando necessario. Fornire il nome di una metrica mostrerà tutte le "istanze" di quella metrica:
Puoi anche utilizzare alcuni metodi PromQL per generare un grafico che rappresenta i dati che stai cercando.
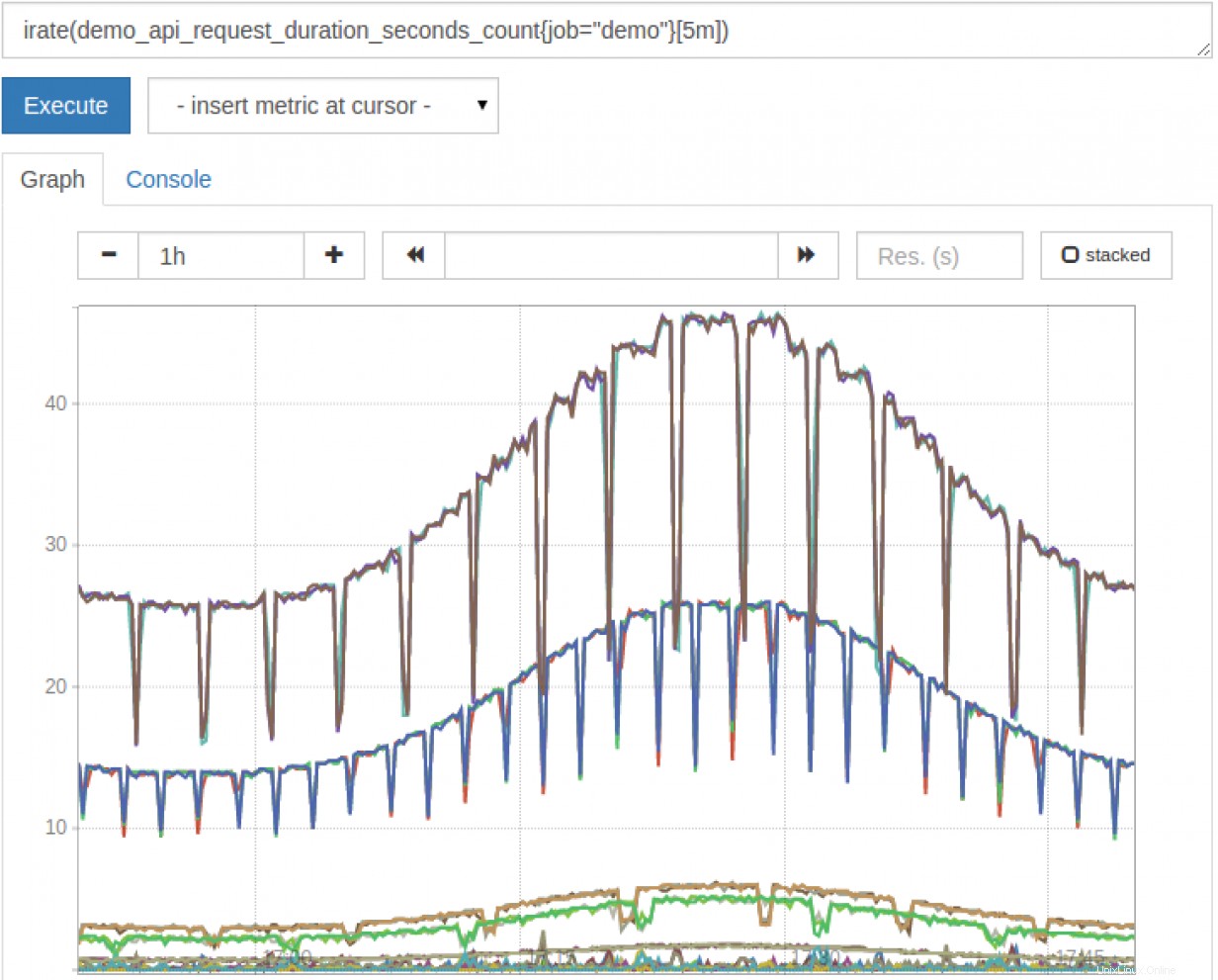
Ovviamente, se sei seriamente intenzionato a rappresentare graficamente, vale la pena esaminare un pacchetto come Grafana. Grafana ti consente di creare dashboard di metriche, inviare avvisi e altro ancora.
Avvisi
Sebbene i grafici siano belli da vedere, le metriche possono servire a un altro scopo importante. Possono essere utilizzati per inviare avvisi. Prometheus include un'applicazione separata, denominata AlertManager, che serve a questo scopo. AlertManager riceve le notifiche da Prometheus e gestisce tutta la logica necessaria per deduplicare e fornire gli avvisi.
Gli avvisi vengono creati scrivendo regole di avviso. Queste regole sono semplicemente query PromQL che vengono attivate quando la query è vera. Ovvero, se hai una query che controlla se la temperatura sulla CPU è superiore a 80°C, la query viene attivata per ogni metrica che soddisfa tale condizione.
Le regole di avviso possono anche includere un periodo di tempo durante il quale una regola deve restituire true. Espandendo il nostro esempio di temperatura, superare gli 80 °C va bene se è un breve periodo di tempo, ma se dura più di cinque minuti, invia un avviso. Gli avvisi possono essere inviati tramite e-mail, Slack, Twitter, SMS e praticamente qualsiasi altra cosa per cui puoi scrivere un'interfaccia.
[ Cerchi ulteriori informazioni sull'automazione dei sistemi? Inizia con The Automated Enterprise, un libro gratuito di Red Hat. ]
Concludi
Il monitoraggio è importante. Aiuta a identificare quando le cose sono andate storte e può mostrare quando le cose stanno andando bene. Un monitoraggio adeguato può essere utilizzato in varie discipline per spremere tutto ciò che puoi dall'oggetto monitorato.
Prometheus è un potente pacchetto di metriche open source. È altamente scalabile, robusto ed estremamente veloce. Un singolo server moderno può essere utilizzato per monitorare un milione o più di metriche al secondo. La distribuzione dei server Prometheus consente di monitorare molte decine e persino centinaia di milioni di metriche ogni secondo.
PromQL fornisce un robusto linguaggio di query che può essere utilizzato per la rappresentazione grafica e per gli avvisi. Il sistema grafico integrato è ottimo per visualizzazioni rapide, ma i dashboard a lungo termine dovrebbero essere gestiti in applicazioni esterne come Grafana.