Se leggi il mio primo articolo sull'utilizzo di Keepalived per la gestione del failover semplice nei cluster, ricorderai quel VRRP utilizza il concetto di priorità per determinare quale server sarà il master attivo. Il server con la priorità più alta "vince" e fungerà da master, trattenendo le richieste VIP e di servizio. Keepalived fornisce diversi metodi utili per regolare la priorità in base allo stato del sistema. In questo articolo esplorerai molti di questi meccanismi, insieme a Keepalived la capacità di eseguire script quando lo stato di un server cambia.
Mostrerò solo la configurazione su server1 per questi esempi. A questo punto, probabilmente sei a tuo agio con la configurazione necessaria su server2 se hai letto l'intera serie. In caso contrario, prenditi un momento per rivedere il primo e il secondo articolo di questa serie prima di continuare.
- Utilizzo di Keepalived per la gestione del failover semplice nei cluster
- Configurazione di un cluster Linux con Keepalived:configurazione di base
Simboli di rete nei diagrammi disponibili tramite VRT Network Equipment Extension, CC BY-SA 3.0.
Keepalived fa un ottimo lavoro nell'attivare un failover quando gli annunci non vengono ricevuti, ad esempio quando il master attivo muore completamente o è irraggiungibile per qualche altro motivo. Tuttavia, scoprirai spesso che sono necessari meccanismi di innesco più fini. Ad esempio, l'applicazione può eseguire i propri controlli di integrità per determinare la capacità dell'app di soddisfare le richieste dei client. Non vorresti che un server app malsano rimanesse il master attivo solo perché era vivo e inviava VRRP pubblicità.
Nota:ho scoperto che la versione di Keepalived disponibile tramite i repository di pacchetti standard contenevano bug che impedivano ad alcuni degli esempi seguenti di funzionare correttamente. Se riscontri problemi, potresti voler installare Keepalived dalla fonte, come descritto nell'articolo precedente.
Tracciamento dei processi
Uno dei Keepalived più comuni le impostazioni implicano il monitoraggio di un processo sul server per determinare lo stato dell'host. Ad esempio, potresti configurare una coppia di server web a disponibilità elevata e attivare un failover se Apache interrompe l'esecuzione su uno di essi.
Keepalived rende tutto più semplice grazie al suo track_process direttive di configurazione. Nell'esempio seguente, ho impostato Keepalived per guardare httpd processo con un peso di 10. A condizione che httpd è in esecuzione, la priorità annunciata sarà 254 (244 + 10 =254). Se httpd smette di funzionare, quindi la priorità scenderà a 244 e attiverà un failover (supponendo che esista una configurazione simile sul server2).
server1# cat keepalived.conf
vrrp_track_process track_apache {
process httpd
weight 10
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 244
advert_int 1
authentication {
auth_type PASS
auth_pass 12345
}
virtual_ipaddress {
192.168.122.200/24
}
track_process {
track_apache
}
} Con questa configurazione in atto (e Apache installato e in esecuzione su entrambi i server), puoi testare uno scenario di failover arrestando Apache e osservando lo spostamento del VIP dal server1 al server2:
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 192.168.122.200/24 fe80::5054:ff:fe82:d66e/64
server1# systemctl stop httpd
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 fe80::5054:ff:fe82:d66e/64
server2# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.102/24 192.168.122.200/24 fe80::5054:ff:fe04:2c5d/64 File di monitoraggio
Keepalived ha anche la capacità di prendere decisioni prioritarie in base al contenuto di un file, il che può essere utile se stai eseguendo un'applicazione in grado di scrivere valori su questo file. Ad esempio, potresti avere un processo in background nella tua app che esegue periodicamente un controllo dello stato e scrive un valore in un file in base allo stato generale dell'applicazione.
Il Keepalived la pagina man spiega che il tracciamento del file si basa sul peso configurato per il file:
"il valore verrà letto come un numero nel testo dal file. Se il peso configurato rispetto al track_file è 0, un valore diverso da zero nel file verrà trattato come uno stato di errore e un valore zero verrà trattato come uno stato OK, altrimenti il valore verrà moltiplicato per il peso configurato nel istruzione track_file. Se il risultato è inferiore a -253, qualsiasi istanza VRRP o gruppo di sincronizzazione che monitora lo script passerà allo stato di errore (il peso può essere 254 per consentire la lettura di un valore negativo dal file)."
Manterrò le cose semplici e userò un peso di 1 per il file di traccia in questo esempio. Questa configurazione prenderà il valore numerico nel file in /var/run/my_app/vrrp_track_file e moltiplicalo per 1.
server1# cat keepalived.conf
vrrp_track_file track_app_file {
file /var/run/my_app/vrrp_track_file
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 244
advert_int 1
authentication {
auth_type PASS
auth_pass 12345
}
virtual_ipaddress {
192.168.122.200/24
}
track_file {
track_app_file weight 1
}
}
Ora puoi creare il file con un valore iniziale e riavviare Keepalived . La priorità può essere vista in tcpdump output, come discusso nel secondo articolo di questa serie.
server1# mkdir /var/run/my_app
server1# echo 5 > /var/run/my_app/vrrp_track_file
server1# systemctl restart keepalived
server1# tcpdump proto 112
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
16:19:32.191562 IP server1 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 249, authtype simple, intvl 1s, length 20 Puoi vedere che la priorità annunciata è 249, che è il valore nel file (5) moltiplicato per il peso (1) e aggiunto alla priorità di base (244). Allo stesso modo, la regolazione della priorità su 6 aumenterà la priorità:
server1# echo 6 > /var/run/my_app/vrrp_track_file
server1# tcpdump proto 112
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
16:20:43.214940 IP server1 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 250, authtype simple, intvl 1s, length 20 Interfaccia traccia
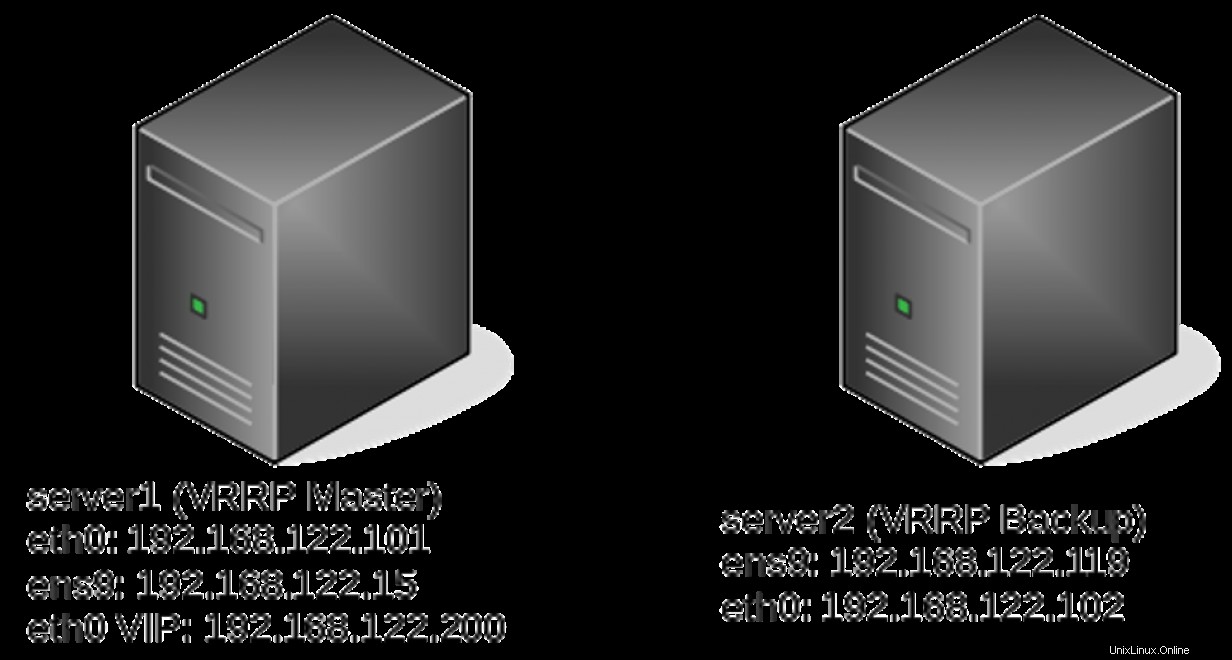
Per i server con più interfacce, può essere utile regolare la priorità del Keepalived istanza in base allo stato di un'interfaccia. Ad esempio, un sistema di bilanciamento del carico con un VIP front-end e una connessione back-end a una rete interna potrebbe voler attivare un Keepalived failover se la connessione alla rete back-end si interrompe. Questo può essere ottenuto con la configurazione track_interface:
server1# cat keepalived.conf
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 244
advert_int 1
authentication {
auth_type PASS
auth_pass 12345
}
virtual_ipaddress {
192.168.122.200/24
}
track_interface {
ens9 weight 5
}
} La configurazione sopra assegna un peso di 5 allo stato dell'interfaccia ens9. Ciò farà sì che server1 assuma una priorità di 249 (244 + 5 =249) finché ens9 è attivo. Se ens9 scende, la priorità scenderà a 244 (e attiverà un failover, supponendo che il server2 sia configurato allo stesso modo). Puoi testarlo su un server multi-interfaccia abbassando un'interfaccia e osservando lo spostamento VIP tra host:
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 192.168.122.200/24 fe80::5054:ff:fe82:d66e/64
ens9 UP 192.168.122.15/24 fe80::7444:5ec4:8015:722f/64
server1# ip link set ens9 down
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 fe80::5054:ff:fe82:d66e/64
ens9 DOWN
server2# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
ens9 UP 192.168.122.119/24 fe80::fc9f:8999:b93e:d491/64
eth0 UP 192.168.122.102/24 192.168.122.200/24 fe80::5054:ff:fe04:2c5d/64 Traccia script
Hai visto che Keepalived offre molti utili metodi di controllo integrati per determinare lo stato di salute e il successivo VRRP priorità di un host. Tuttavia, a volte gli ambienti più complessi richiedono l'uso di strumenti personalizzati, come gli script di controllo dello stato, per soddisfare le proprie esigenze. Per fortuna, Keepalived ha anche la capacità di eseguire uno script arbitrario per determinare lo stato di salute di un host. Puoi regolare il peso dello script, ma manterrò le cose semplici per questo esempio:uno script che restituisce 0 indicherà il successo, mentre uno script che restituisce qualsiasi altra cosa indicherà che il Keepalived l'istanza dovrebbe entrare in stato di errore.
Lo script è un semplice ping al 8.8.8.8 preferito da tutti Server DNS di Google, come mostrato di seguito. Nel tuo ambiente, probabilmente utilizzerai uno script più complesso per eseguire tutti i controlli di integrità di cui hai bisogno.
server1# cat /usr/local/bin/keepalived_check.sh
#!/bin/bash
/usr/bin/ping -c 1 -W 1 8.8.8.8 > /dev/null 2>&1
Noterai che ho utilizzato un timeout di 1 secondo per ping (-V 1). Durante la scrittura di Keepalived controlla gli script, è una buona idea mantenerli leggeri e veloci. Non vuoi che un server rotto rimanga il master per molto tempo perché il tuo script è lento.
Il Keepalived la configurazione per uno script di controllo è mostrata di seguito:
server1# cat keepalived.conf
vrrp_script keepalived_check {
script "/usr/local/bin/keepalived_check.sh"
interval 1
timeout 5
rise 3
fall 3
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 244
advert_int 1
authentication {
auth_type PASS
auth_pass 12345
}
virtual_ipaddress {
192.168.122.200/24
}
track_script {
keepalived_check
}
}
Assomiglia molto alla configurazione con cui hai lavorato, ma il vrrp_script block ha alcune direttive univoche:
interval:la frequenza con cui deve essere eseguito lo script (1 secondo).timeout:Quanto tempo attendere per il ritorno dello script (5 secondi).rise:quante volte lo script deve essere restituito correttamente affinché l'host sia considerato "sano". In questo esempio, lo script deve restituire correttamente 3 volte. Questo aiuta a prevenire una condizione di "sbattimento" in cui un singolo errore (o successo) causa ilKeepalivedstato per scorrere rapidamente avanti e indietro.fall:quante volte lo script deve tornare senza successo (o timeout) affinché l'host sia considerato "malsano". Funziona come l'inverso della direttiva aumento.
È possibile testare questa configurazione forzando l'esito negativo dello script. Nell'esempio seguente, ho aggiunto un iptables regola che impedisce la comunicazione con 8.8.8.8 . Ciò ha causato il fallimento del controllo dello stato e la scomparsa del VIP dopo pochi secondi. Posso quindi rimuovere la regola e guardare il VIP riapparire.
server1# iptables -I OUTPUT -d 8.8.8.8 -j DROP
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 fe80::5054:ff:fe82:d66e/64
server1# iptables -D OUTPUT -d 8.8.8.8 -j DROP
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 192.168.122.200/24 fe80::5054:ff:fe82:d66e/64
Un rapido suggerimento sugli script in Keepalived :Possono essere eseguiti come un utente diverso oltre a root. Anche se non l'ho dimostrato in questi esempi, dai un'occhiata alla pagina man e assicurati di utilizzare l'utente meno privilegiato possibile per evitare implicazioni negative sulla sicurezza dal tuo script di controllo.
Script di notifica
Ho discusso dei modi per attivare Keepalived risposte basate su condizioni esterne. Tuttavia, probabilmente vorrai anche attivare azioni quando Keepalived transizioni da uno stato all'altro. Ad esempio, potresti voler interrompere un servizio quando Keepalived entra nello stato di backup, oppure potresti voler dare il via a un'e-mail a un amministratore. Keepalived ti consente di farlo con gli script di notifica.
Keepalived fornisce diverse direttive di notifica per chiamare solo script su stati particolari (notify_master , notify_backup , ecc.), ma mi concentrerò sulla semplice notify direttiva in quanto è la più flessibile. Quando uno script nella notify viene chiamata, riceve quattro argomenti aggiuntivi (dopo tutti gli argomenti passati allo script stesso).
Elencati in ordine, questi sono:
- Gruppo o istanza:indicazione se la notifica è attivata da un
VRRPgruppo (non discusso in questa serie) o un particolareVRRPesempio. - Nome del gruppo o istanza
- Dichiara a cui è in corso la transizione del gruppo o dell'istanza
- La priorità
Dare un'occhiata a un esempio lo rende più chiaro. Lo script e Keepalived la configurazione è simile a questa:
server1# cat /usr/local/bin/keepalived_notify.sh
#!/bin/bash
echo "$1 $2 has transitioned to the $3 state with a priority of $4" > /var/run/keepalived_status
server1# cat keepalived.conf
vrrp_script keepalived_check {
script "/usr/local/bin/keepalived_check.sh"
interval 1
timeout 5
rise 3
fall 3
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 244
advert_int 1
authentication {
auth_type PASS
auth_pass 12345
}
virtual_ipaddress {
192.168.122.200/24
}
track_script {
keepalived_check
}
notify "/usr/local/bin/keepalived_notify.sh"
}
La configurazione di cui sopra chiamerà /usr/local/bin/keepalived_notify.sh script ogni volta un Keepalived avviene la transizione di stato. Poiché è attivo lo stesso script di controllo, puoi facilmente ispezionare lo stato iniziale e quindi attivare una transizione:
server1# cat /var/run/keepalived_status
INSTANCE VI_1 has transitioned to the MASTER state with a priority of 244
server1# iptables -A OUTPUT -d 8.8.8.8 -j DROP
server1# cat /var/run/keepalived_status
INSTANCE VI_1 has transitioned to the FAULT state with a priority of 244
server1# iptables -D OUTPUT -d 8.8.8.8 -j DROP
server1# cat /var/run/keepalived_status
INSTANCE VI_1 has transitioned to the MASTER state with a priority of 244
Puoi vedere che gli argomenti della riga di comando corrispondono a quelli che ho descritto all'inizio di questa sezione. Ovviamente questo è un semplice esempio, ma gli script di notifica possono eseguire molte azioni complesse, come regolare le regole di routing o attivare altri script. Sono un modo utile per intraprendere azioni esterne basate su Keepalived cambiamenti di stato.
Conclusione
Questo articolo ha chiuso un Keepalived fondamentale serie con alcuni concetti avanzati. Hai imparato come attivare Keepalived priorità e modifiche dello stato in base a eventi esterni, come lo stato del processo, le modifiche all'interfaccia e persino i risultati di script esterni. Hai anche imparato come attivare gli script di notifica in risposta a Keepalived cambiamenti di stato. Puoi combinare due o più di questi approcci per creare una coppia di server Linux ad alta disponibilità che rispondano a più stimoli esterni e garantiscano che il traffico raggiunga sempre un indirizzo IP sano in grado di soddisfare le richieste dei client.
[ Vuoi saperne di più sull'amministrazione del sistema? Segui un corso online gratuito:panoramica tecnica di Red Hat Enterprise Linux. ]