Alveare è un Data Warehouse modello in Hadoop Ecosistema. Può funzionare come strumento ETL su Hadoop . L'abilitazione dell'alta disponibilità (HA) su Hive non è simile a quella dei servizi principali come Namenode e Resource Manager.
Il failover automatico non avverrà in Hive (Hiveserver2 ). Se presente Hiveserver2 (HS2 ) non riesce, eseguendo lavori su quell'HS2 non riuscito fallirà. È necessario inviare nuovamente il lavoro in modo che possa essere eseguito su altri HiveServer2 . Quindi, abilitando HA su HS2 non è altro che aumentare il numero di HS2 componenti nel Cluster .
In questo articolo, vedremo i passaggi per installare e abilitare l'Alta disponibilità di Alveare .
Requisiti
- Best practice per la distribuzione di Hadoop Server su CentOS/RHEL 7 – Parte 1
- Impostazione dei prerequisiti Hadoop e rafforzamento della sicurezza – Parte 2
- Come installare e configurare Cloudera Manager su CentOS/RHEL 7 – Parte 3
- Come installare CDH e configurare i posizionamenti dei servizi su CentOS/RHEL 7 – Parte 4
- Come impostare l'alta disponibilità per Namenode – Parte 5
- Come impostare la disponibilità elevata per Resource Manager – Parte 6
Iniziamo...
Installazione e configurazione di Hive
1. Accedi a Cloudera Manager all'URL sottostante e vai a Cloudera Manager –> Aggiungi servizio .
http://13.233.129.39:7180/cmf/home
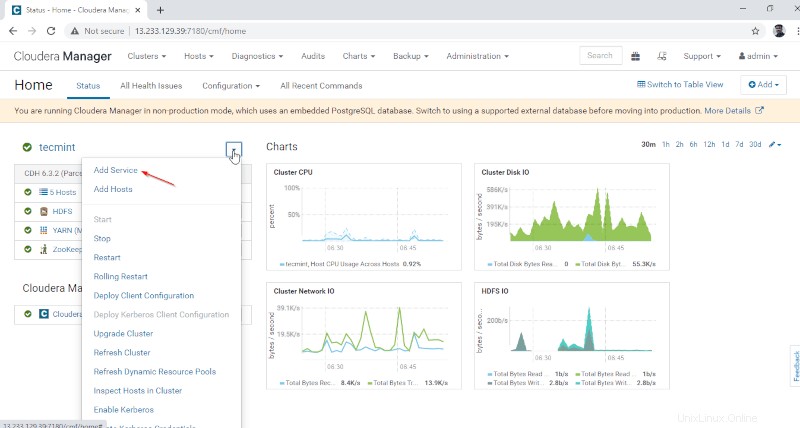
2. Seleziona il servizio "Alveare '.
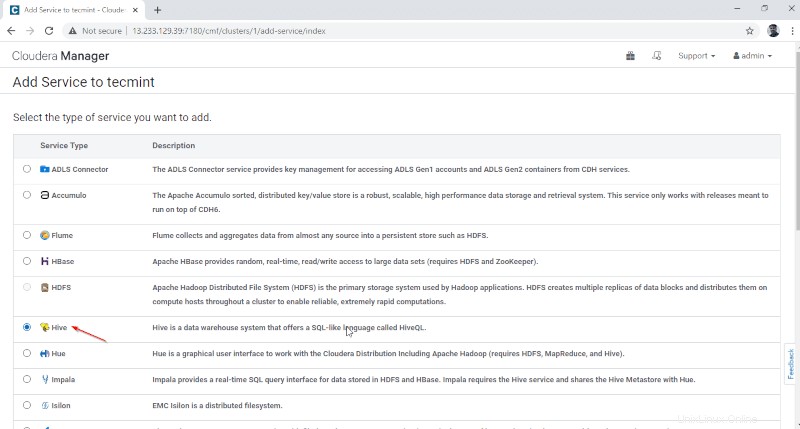
3. Assegna i servizi sui nodi.
- Gateway – È il servizio client in cui l'utente può accedere all'hive. Di solito, questo servizio verrà inserito in Edge nodi dedicati agli utenti.
- Metastore Hive – È un repository centrale per l'archiviazione dei metadati Hive.
- Server WebHCat – È un'API Web per HCatalolog e altri servizi Hadoop.
- Hiveserver2 – È un'interfaccia di client per l'esecuzione di query su Hive.
Una volta selezionati i server, fai clic su "Continua ' per procedere.
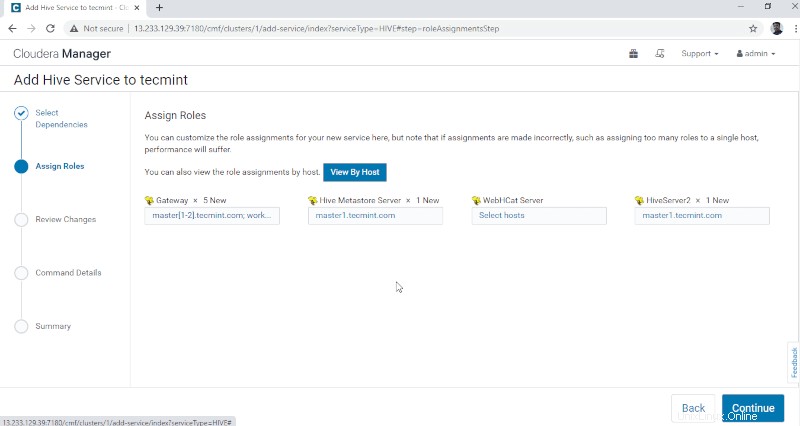
4. Hive Metastore necessita di un database sottostante per l'archiviazione dei metadati. Qui stiamo usando il predefinito PostgreSQL database integrato con CDH .
I dettagli del database di seguito menzionati verranno inseriti automaticamente, "Test connessione ' verrà saltato poiché il database menzionato verrà creato al volo. In tempo reale, dobbiamo creare il Database nel database esterno e testare la connessione per procedere ulteriormente. Al termine, fai clic su "Continua '.
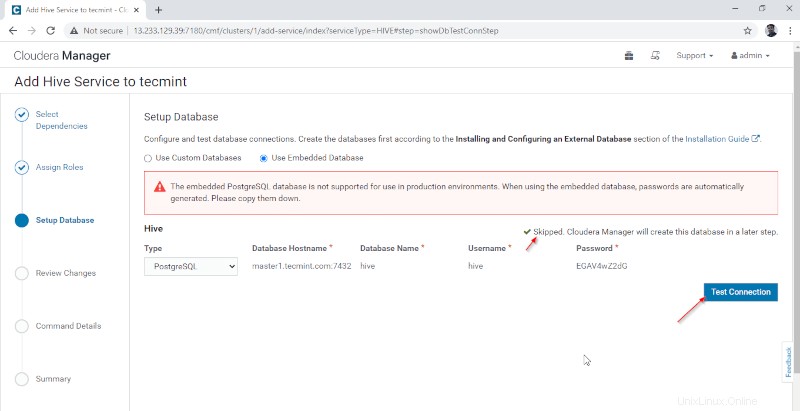
5. Configura il Magazzino Hive directory, /utente/alveare/magazzino è il percorso di directory predefinito per l'archiviazione delle tabelle Hive. Fai clic su "Continua '.
6. L'installazione di Hive è iniziata.
7. Una volta completata l'installazione, puoi ottenere il messaggio "Finito stato. Fai clic su "Continua ' per procedere ulteriormente.
8. Installazione e configurazione dell'hive completate correttamente. Fai clic su "Fine ' per completare la procedura di installazione.
9. Puoi vedere l'Alveare servizio aggiunto nel Cluster tramite il Dashboard di Cloudera Manager .
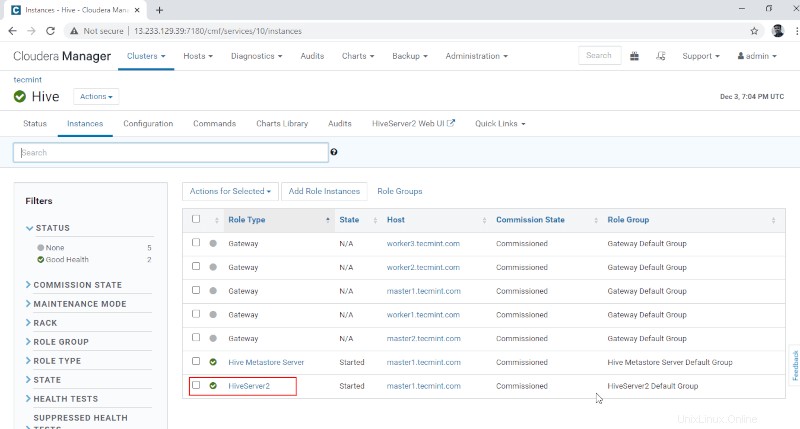
10. Puoi visualizzare Hiveserver2 in Istanze di Alveare . Abbiamo aggiunto Hiveserver2 in master1 .
Gestione Cloudera –> Alveare –> Istanze –> Hiveserver2 .
Abilitazione dell'alta disponibilità su Hive
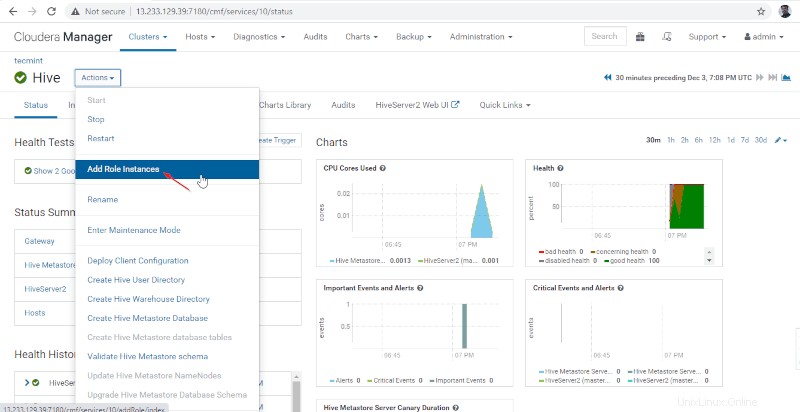
11. Quindi aggiungi il ruolo Hive andando su Cloudera Manager –> Alveare –> Azioni –> Aggiungi ruolo Istanze.
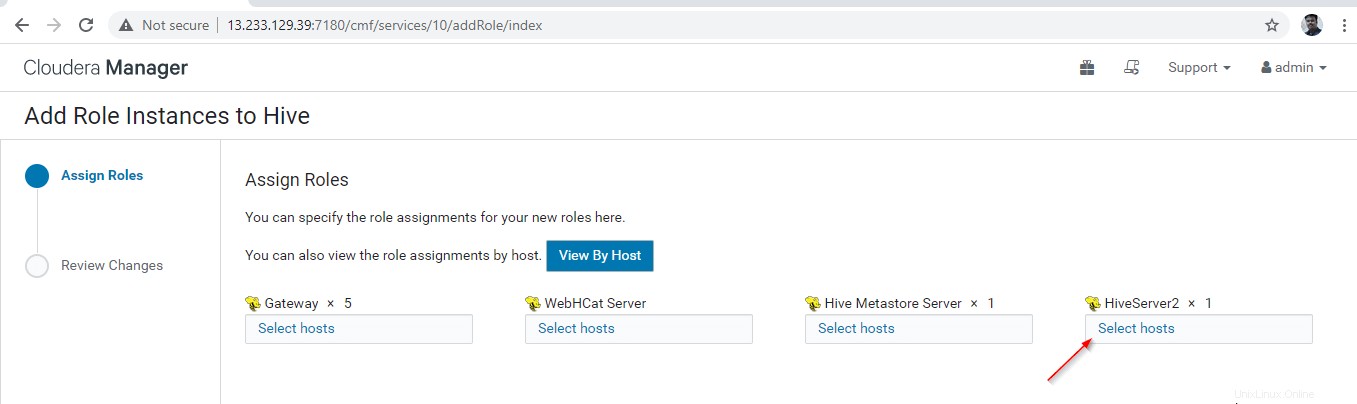
12. Seleziona i server in cui desideri posizionare Hiveserver2 extra . Puoi aggiungerne più di due, non c'è limite. Qui ne stiamo aggiungendo un altro Hiveserver2 in master2 .
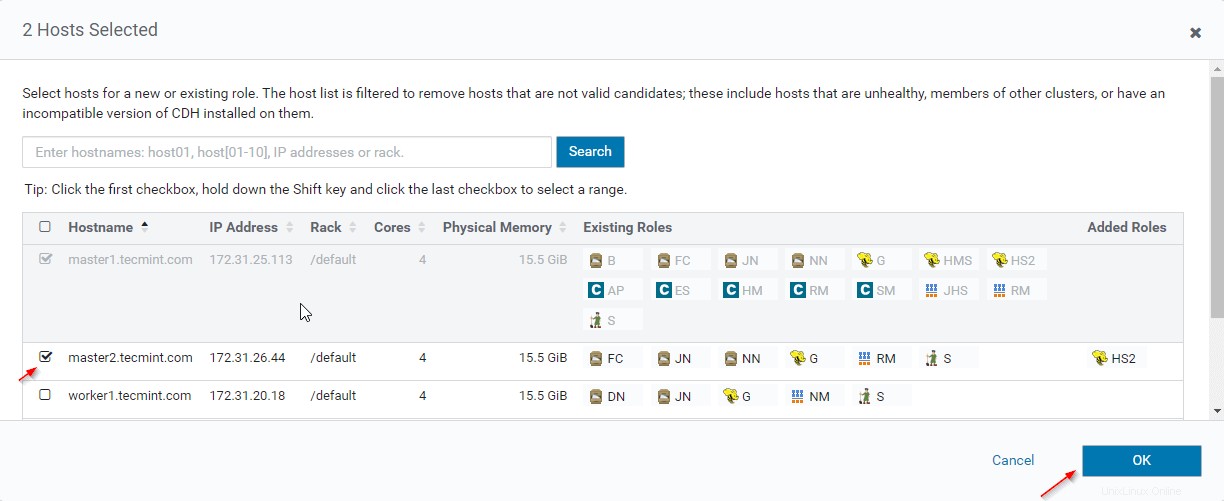
13. Una volta selezionato il server, fai clic su "Continua '.
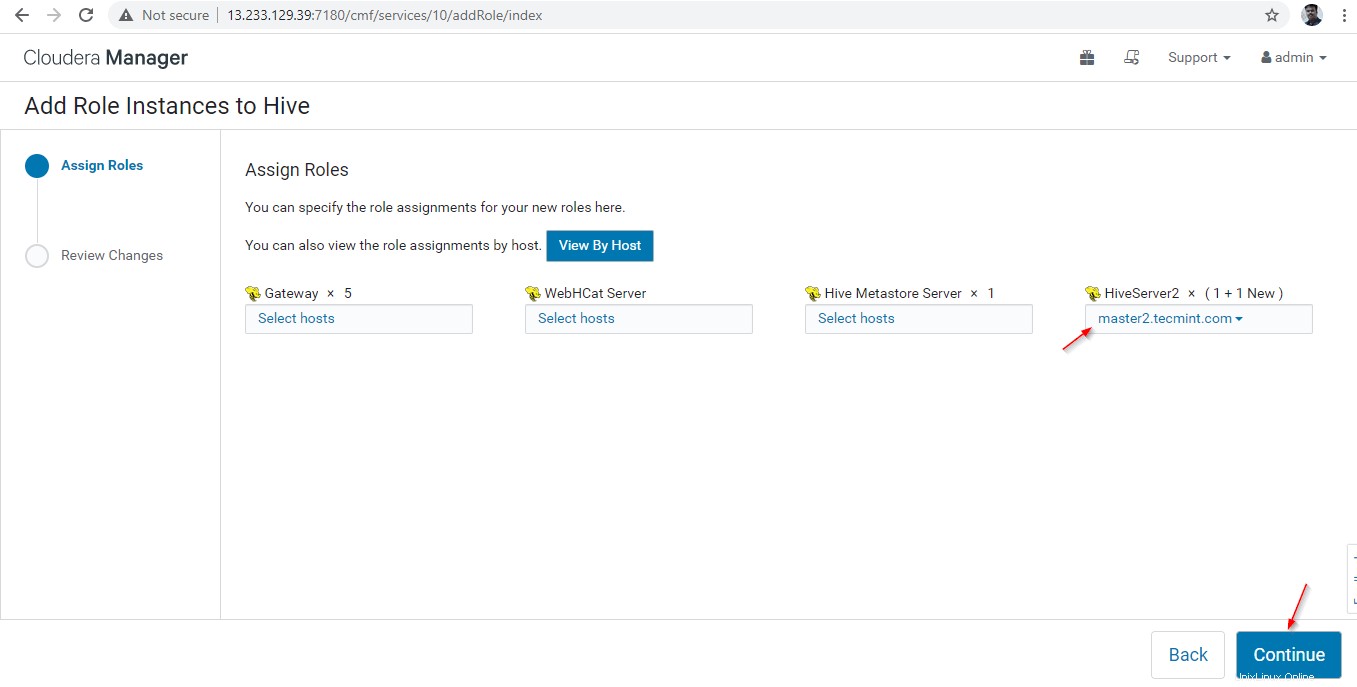
14. Un Hiverserver2 verrà aggiunto alle Istanze Hive , devi avviarlo andando su Cloudera Manager –> Alveare –> Istanze –> (Seleziona Hiveserver2 aggiunto di recente) –> Azione per selezionati –> Inizia .
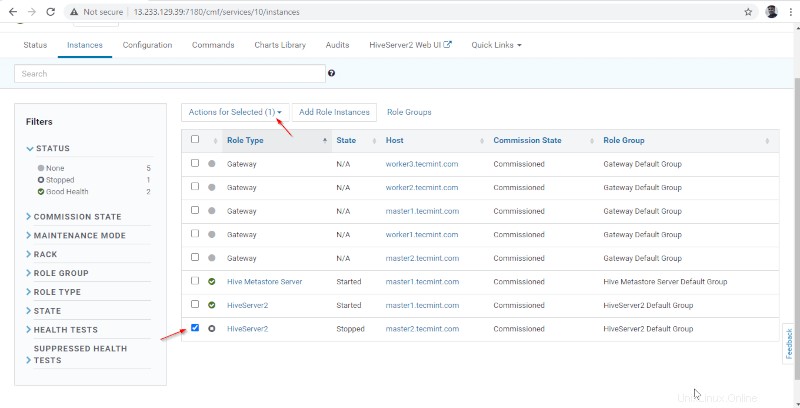
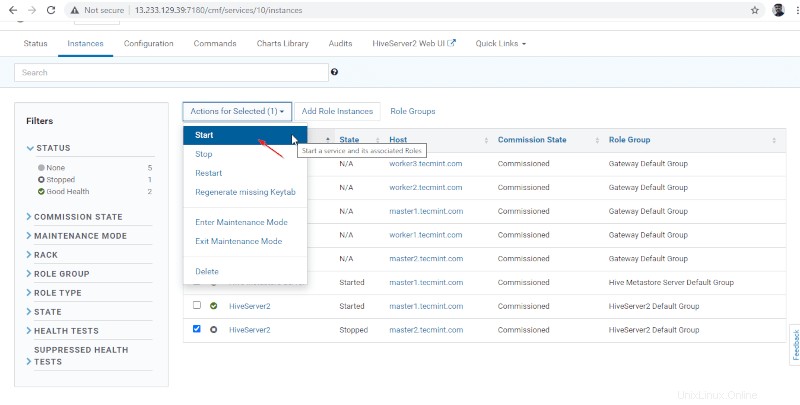
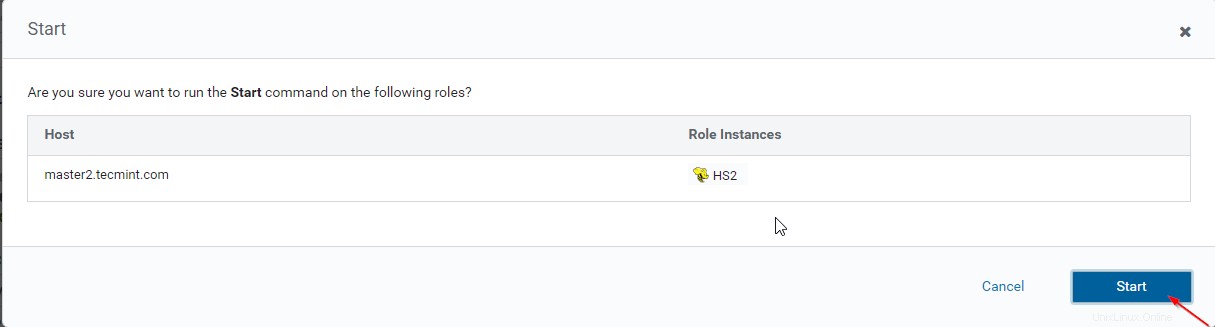
15. Una volta Hiveserver2 iniziato su master2 , otterrai lo stato "Fine '. Fai clic su Chiudi .
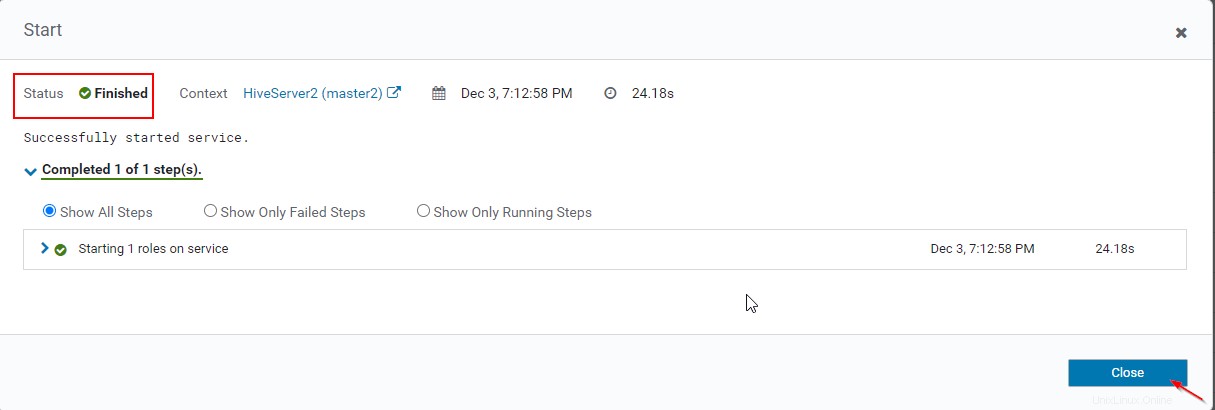
16. Puoi visualizzare entrambi gli Hiveserver2 sono in esecuzione.
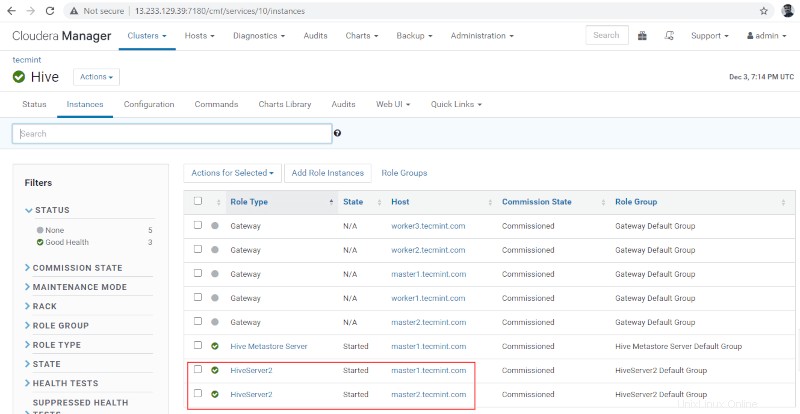
Verifica della disponibilità dell'alveare
Possiamo connettere Hiveserver2 attraverso il beeline che è un thin client e una riga di comando. Utilizza il driver JDBC per stabilire la connessione.
17. Accedi al server in cui Hive Gateway è in esecuzione.
[[email protected] ~]$ beeline

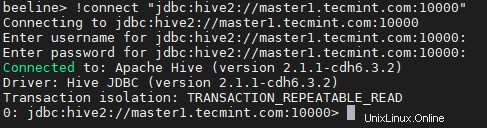
18. Inserisci il JDBC stringa di connessione per connettere Hiveserver2 . A questo proposito, la stringa stiamo citando Hiverserver2 (master2 ) con il numero di porta predefinito 10000 . Questa stringa di connessione si collegherà solo a Hiveserver2 che è in esecuzione su master2 .
beeline> !connect "jdbc:hive2://master1.tecmint.com:10000"
19. Esegui una query di esempio.
0: jdbc:hive2://master1.tecmint.com:10000> show databases;
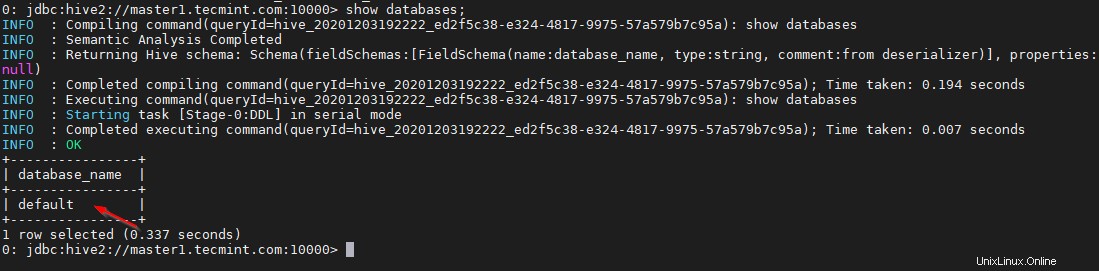
Questo è il database predefinito integrato.
20. Utilizza il comando seguente per terminare la sessione Hive.
0: jdbc:hive2://master1.tecmint.com:10000> !quit

21. Puoi utilizzare lo stesso modo per connettere Hiveserver2 in esecuzione su master2 .
beeline> !connect "jdbc:hive2://master2.tecmint.com:10000"
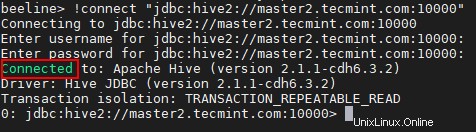
23. Possiamo connettere Hiveserver2 in Scoperta del guardiano dello zoo modalità. In questo metodo, non è necessario menzionare Hiveserver2 nella stringa di connessione invece stiamo usando Zookeeper per scoprire il Hiveserver2 disponibile .
Qui possiamo utilizzare un sistema di bilanciamento del carico di terze parti per bilanciare il carico tra gli Hiverserver2 disponibili . La configurazione seguente è necessaria per abilitare la Modalità di rilevamento Zookeeper andando su Cloudera Manager –> Alveare –> Configurazione .
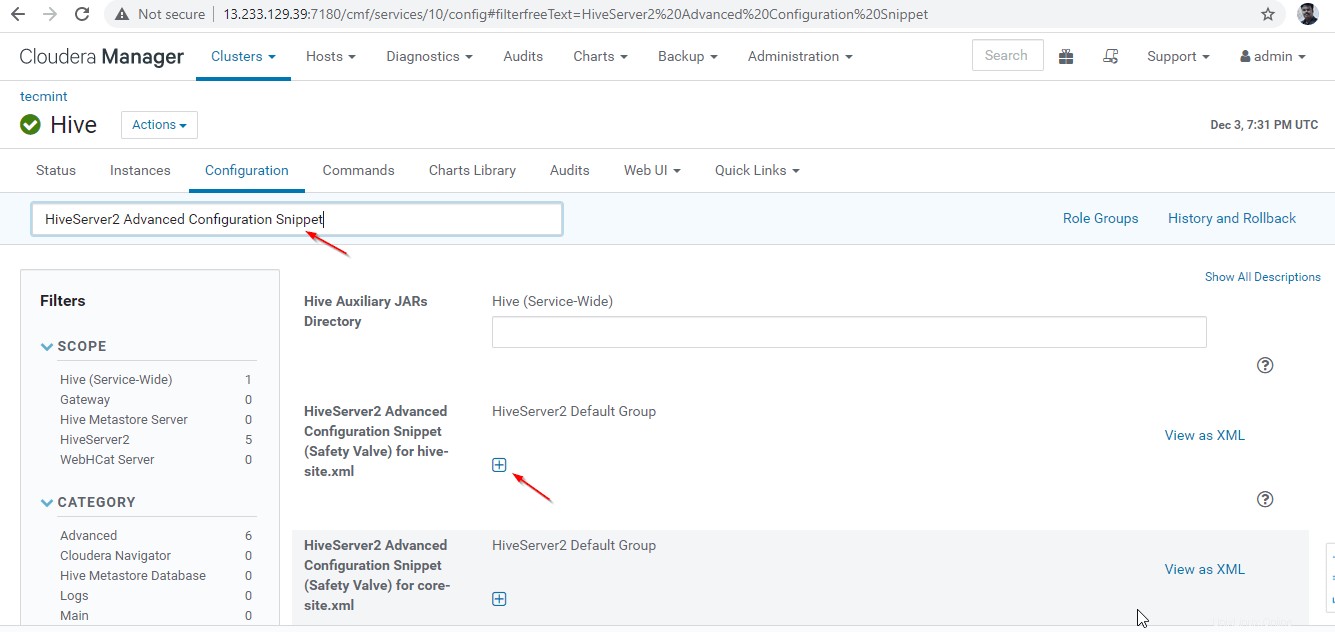
24. Quindi, cerca la proprietà "Snippet di configurazione avanzata di HiveServer2 ” e fai clic su + simbolo per aggiungere la proprietà sottostante.
Name : hive.server2.support.dynamic.service.discovery Value : true Description : <any description>
25. Una volta inserita la proprietà, fai clic su "Salva modifiche '.
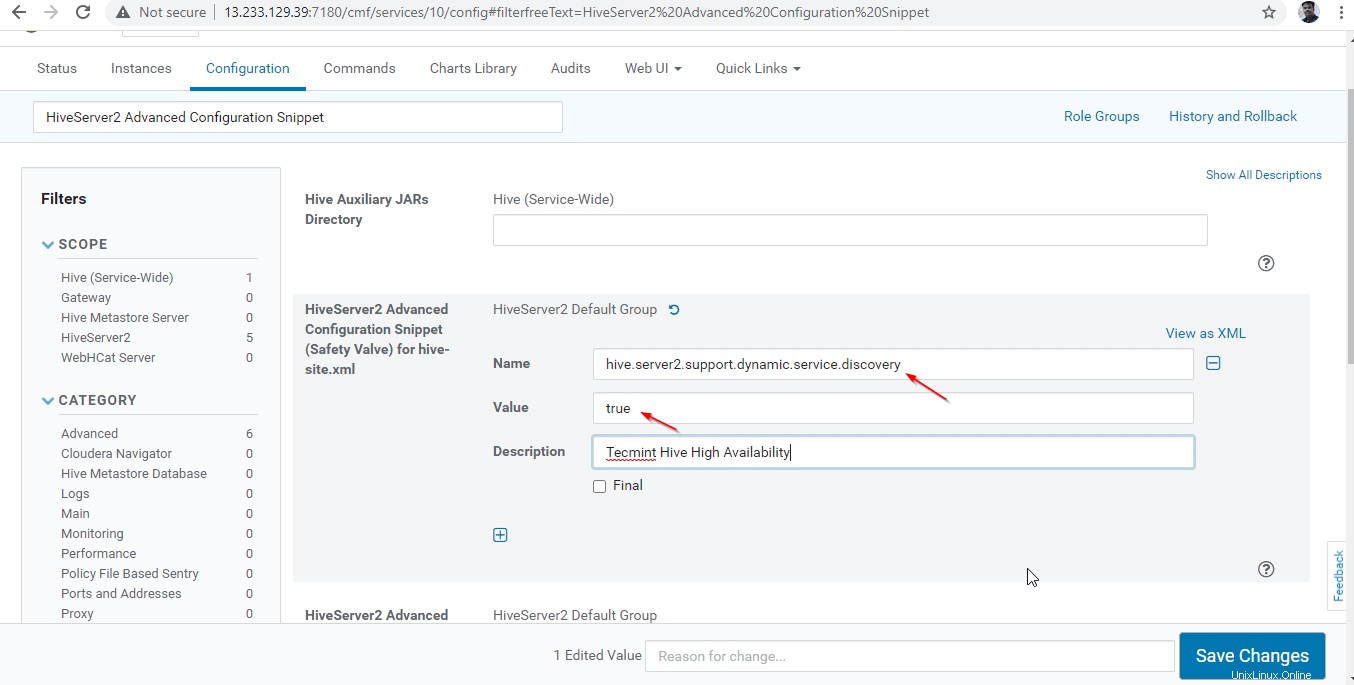
26. Poiché abbiamo apportato modifiche alla configurazione, è necessario riavviare i servizi interessati facendo clic sul simbolo di colore arancione per riavviare i servizi.
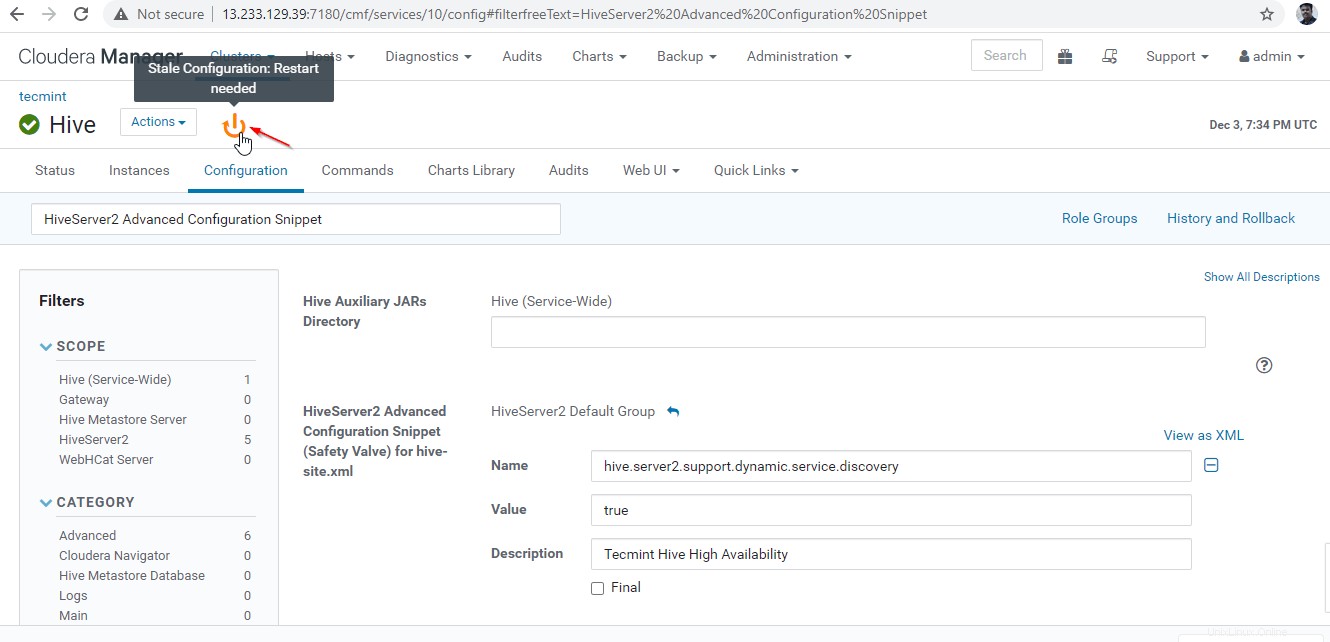
27. Fai clic su "Riavvia obsoleto ' servizi.
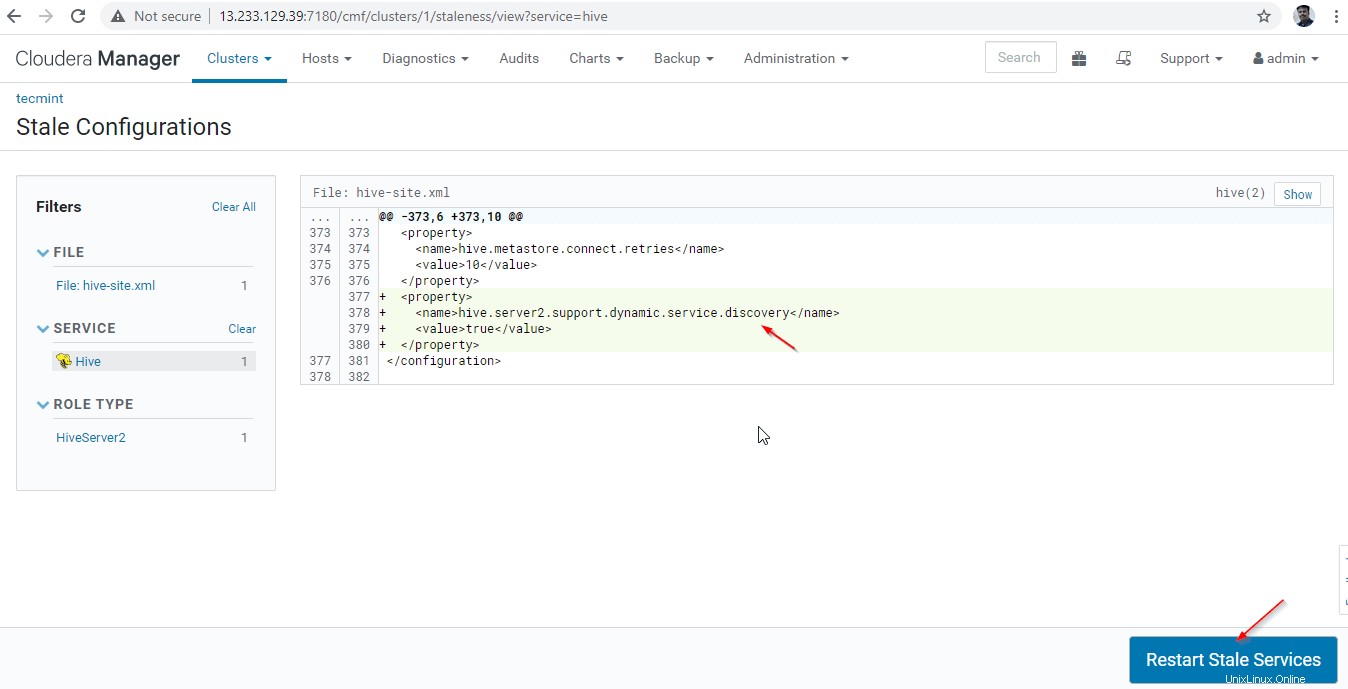
28. Sono disponibili due opzioni. Se il cluster è in produzione live, è necessario preferire il riavvio in sequenza per ridurre al minimo l'interruzione. Poiché stiamo installando di recente, possiamo scegliere la seconda opzione "Re-deploy Client Configuration ' e fai clic su 'Riavvia ora '.
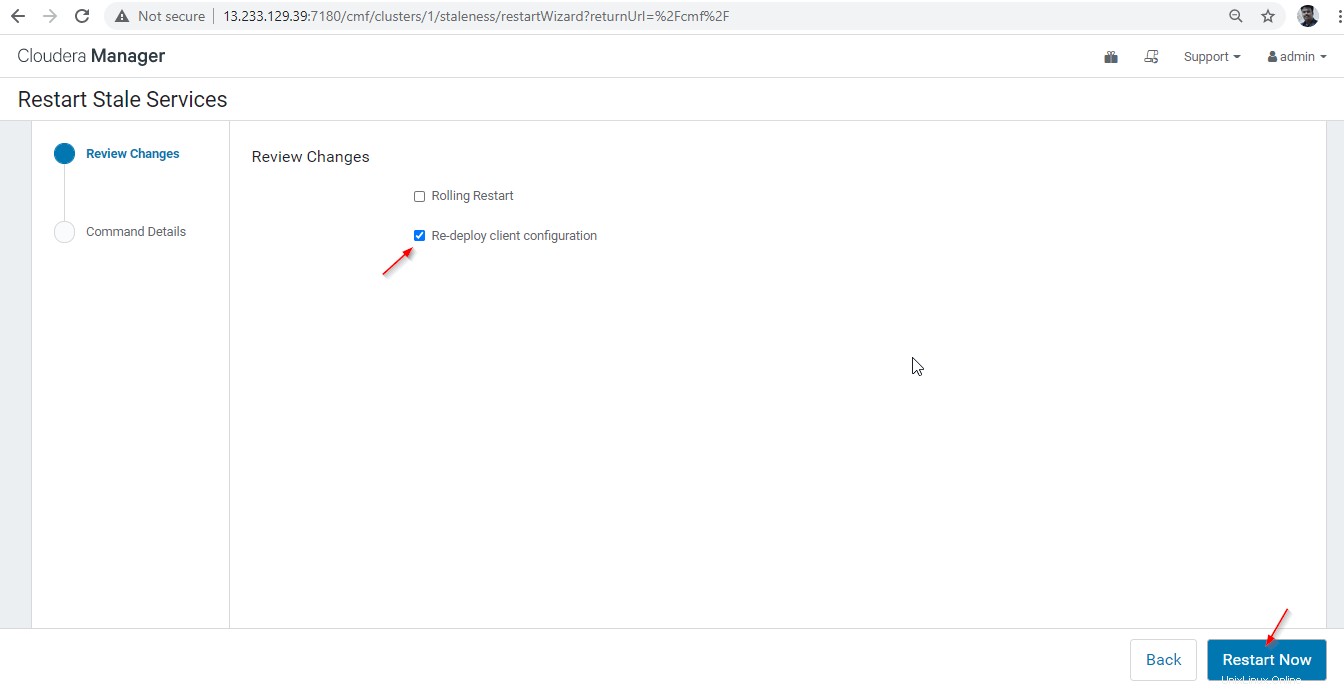
29. Una volta completato il riavvio, otterrai lo stato "Fine '. Fai clic su "Fine ' per completare il processo.
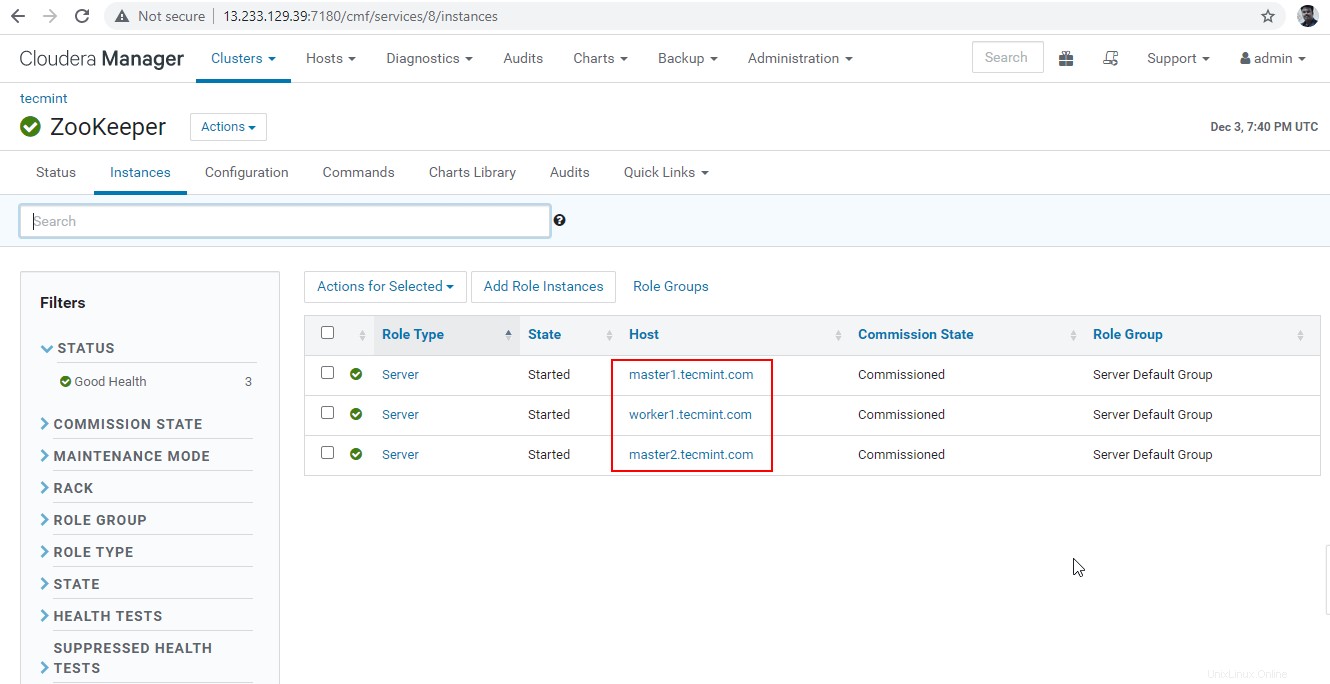
30. Ora collegheremo Hiveserver2 utilizzando Scoperta Zookeeper modalità. Nel JDBC connection, la stringa necessaria per utilizzare Zookeeper server con il numero di porta 2081 . Raccogli i server Zookeeper andando su Cloudera Manager –> Custode dello zoo –> Istanze –> (Annota i nomi dei server).
Questi sono i tre server con Zookeeper, 2181 è il numero di porta.
master1.tecmint.com:2181 master2.tecmint.com:2181 worker1.tecmint.com:2181
31. Ora entra in beeline .
[[email protected] ~]$ beeline

32. Inserisci il JDBC stringa di connessione come menzionato di seguito. Dobbiamo menzionare la Modalità di rilevamento del servizio e Spazio dei nomi Zookeeper . 'hiveserver2 ' è lo spazio dei nomi predefinito di Hiveserver2.
beeline>!connect "jdbc:hive2://master1.tecmint.com:2181,master2.tecmint.com:2181,worker1.tecmint.com:2181/;serviceDiscoveryMode=zookeeper;zookeeperNamespace=hiveserver2"

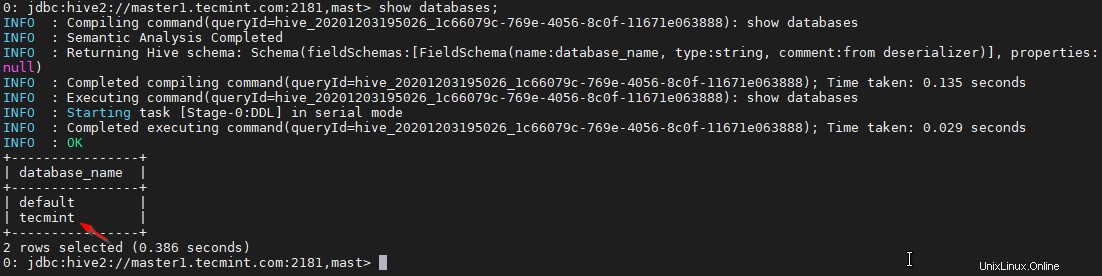
33. Ora la sessione è connessa a Hiveserver2 in esecuzione su master1 . Eseguire una query di esempio per convalidare. Usa il comando seguente per creare un database.
0: jdbc:hive2://master1.tecmint.com:2181,mast> create database tecmint;

34. Utilizzare il comando seguente per elencare il database.
0: jdbc:hive2://master1.tecmint.com:2181,mast> show databases;
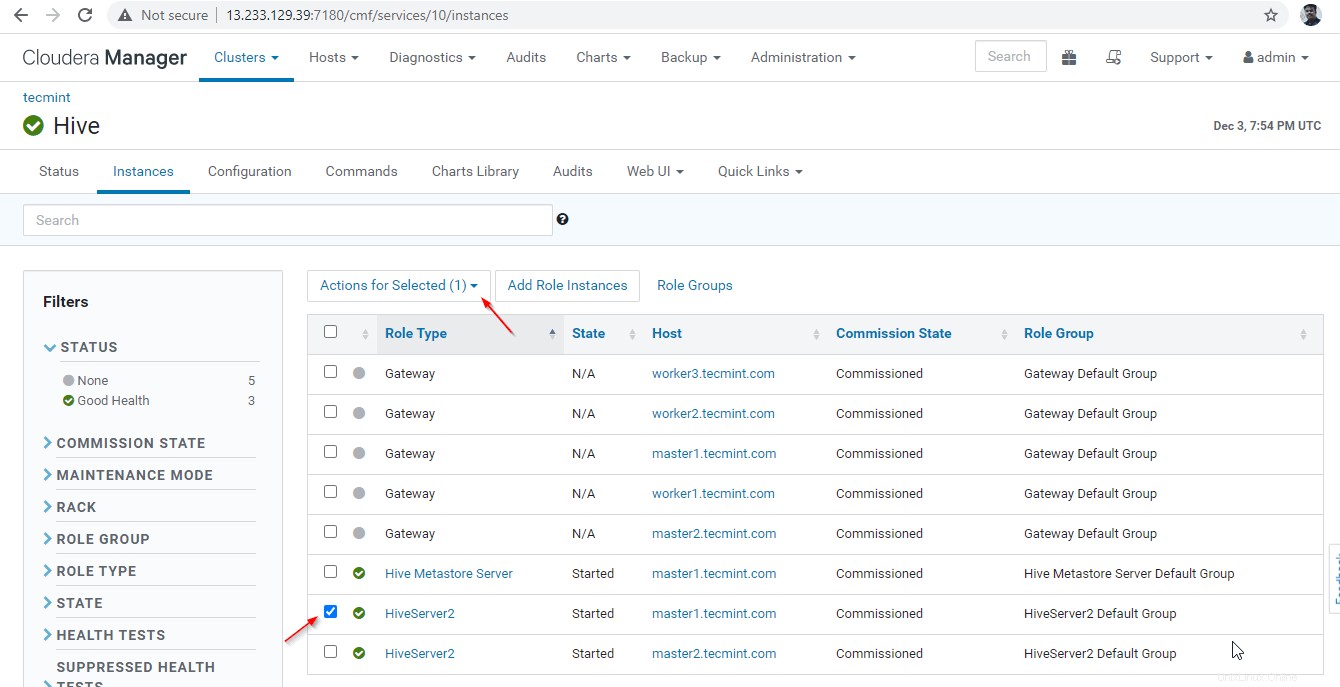
35. Ora convalideremo l'alta disponibilità in Modalità scoperta Zookeeper . Vai a Gestione Cloudera e arresta Hiveserver2 su master1 che abbiamo testato sopra.
Gestione Cloudera –> Alveare –> Istanze –> (seleziona Hiveserver2 su master1 ) –> Azione per selezionati –> Interrompi .
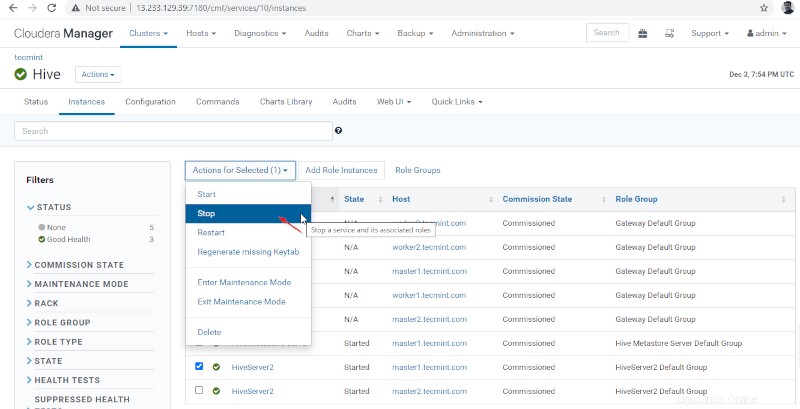
36. Fai clic su "Interrompi '. Una volta interrotto, otterrai lo stato "Fine '. Verifica Hiveserver2 su master1 navigando in Hive –> Istanze .
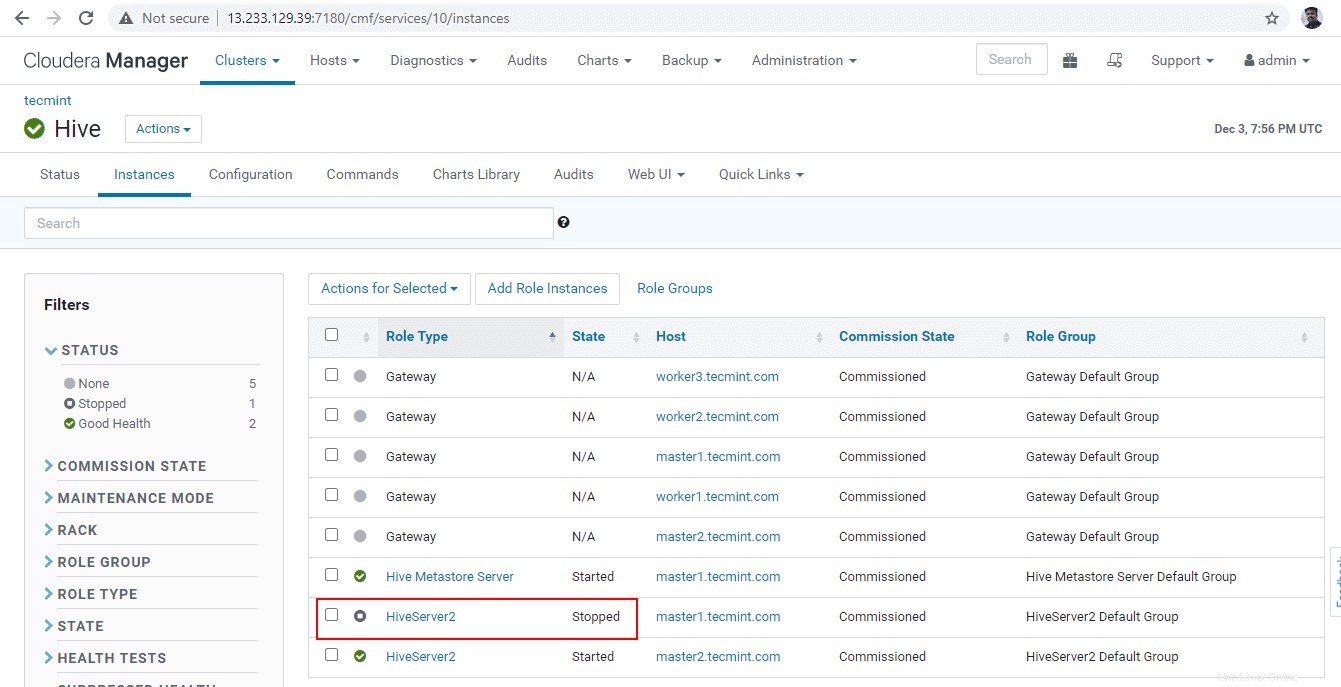
37. Entra nella linea di confine e connetti Hiveserver2 utilizzando lo stesso JDBC stringa di connessione con Modalità scoperta Zookeeper come abbiamo fatto nei passaggi precedenti.
[[email protected] ~]$ beeline beeline>!connect "jdbc:hive2://master1.tecmint.com:2181,master2.tecmint.com:2181,worker1.tecmint.com:2181/;serviceDiscoveryMode=zookeeper;zookeeperNamespace=hiveserver2"

Ora sarai connesso a Hiveserver2 in esecuzione su master2 .
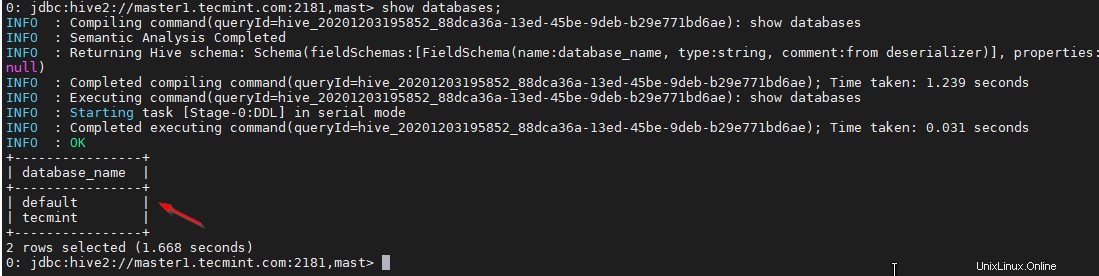
38. Convalida con una query di esempio.
0: jdbc:hive2://master1.tecmint.com:2181,mast> show databases;
Conclusione
In questo articolo, abbiamo esaminato i passaggi dettagliati per avere il Hive Data Warehouse modello nel nostro cluster con Alta disponibilità . In un ambiente di produzione in tempo reale, più di tre Hiveserver2 verrà posizionato con la Modalità scoperta Zookeeper abilitato.
Qui, tutti gli Hiveserver2 si stanno registrando con Zookeeper sotto uno Spazio dei nomi comune . Zookeeper in modo dinamico scopre il Hiveserver2 disponibile e stabilisce la sessione Hive.