Quando lavoravo in un ruolo incentrato sulla rete, una delle maggiori sfide era sempre colmare il divario tra rete e ingegneria dei sistemi. Gli amministratori di sistema, privi di visibilità sulla rete, spesso incolpavano la rete di interruzioni o strani problemi. Gli amministratori di rete, incapaci di controllare i server e affaticati dall'atteggiamento "colpevole fino a prova contraria" nei confronti della rete, spesso incolpavano gli endpoint della rete.
Naturalmente, la colpa non risolve i problemi. Prendersi del tempo per comprendere le basi del dominio di qualcuno può fare molto per migliorare le relazioni con gli altri team e favorire soluzioni più rapide ai problemi. Questo fatto è particolarmente vero per gli amministratori di sistema. Avendo una conoscenza di base della risoluzione dei problemi di rete, possiamo fornire prove più forti ai nostri colleghi di rete quando sospettiamo che la rete possa essere in errore. Allo stesso modo, spesso possiamo risparmiare tempo eseguendo da soli alcuni problemi iniziali di risoluzione dei problemi.
In questo articolo, tratteremo le basi della risoluzione dei problemi di rete tramite la riga di comando di Linux.
Una rapida rassegna del modello TCP/IP
Per prima cosa, prendiamoci un momento per rivedere i fondamenti del modello di rete TCP/IP. Sebbene la maggior parte delle persone utilizzi il modello Open Systems Interconnection (OSI) per discutere la teoria delle reti, il modello TCP/IP rappresenta in modo più accurato la suite di protocolli implementati nelle reti moderne.
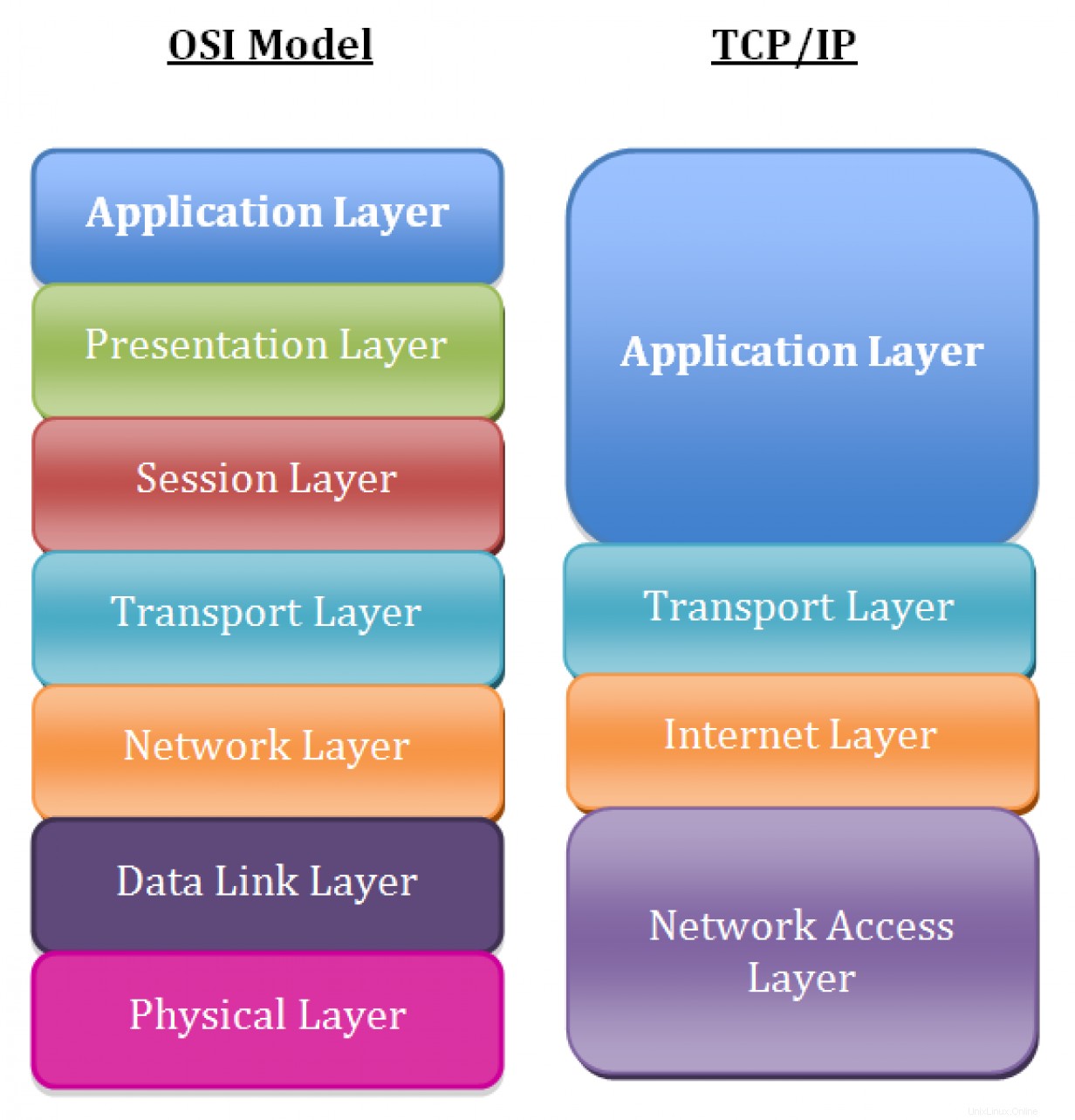
I livelli nel modello di rete TCP/IP, nell'ordine, includono:
- Livello 5: Applicazione
- Livello 4: Trasporto
- Livello 3: Rete/Internet
- Livello 2: Collegamento dati
- Livello 1: Fisico
Presumo che tu abbia familiarità con questo modello e procederò discutendo i modi per risolvere i problemi nello stack dai livelli da 1 a 4. Il punto in cui iniziare la risoluzione dei problemi dipende dalla situazione. Ad esempio, se è possibile eseguire l'SSH su un server, ma il server non può connettersi a un database MySQL, è improbabile che il problema riguardi i livelli fisici o di collegamento dati sul server locale. In generale, è una buona idea scendere in classifica. Inizia con l'applicazione, quindi risolvi gradualmente ogni livello inferiore fino a quando non hai isolato il problema.
Con quello sfondo fuori mano, passiamo alla riga di comando e iniziamo la risoluzione dei problemi.
Livello 1:il livello fisico
Spesso diamo per scontato il livello fisico ("ti sei assicurato che il cavo sia collegato?"), ma possiamo facilmente risolvere i problemi del livello fisico dalla riga di comando di Linux. Questo è se hai la connettività della console all'host, cosa che potrebbe non essere il caso per alcuni sistemi remoti.
Iniziamo con la domanda più elementare:la nostra interfaccia fisica è attiva? Il ip link show il comando ci dice:
# ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST> mtu 1500 qdisc pfifo_fast state DOWN mode DEFAULT group default qlen 1000
link/ether 52:54:00:82:d6:6e brd ff:ff:ff:ff:ff:ff
Notare l'indicazione di GIÙ nell'output sopra per l'interfaccia eth0. Questo risultato significa che il livello 1 non sta arrivando. Potremmo provare a risolvere i problemi controllando il cablaggio o l'estremità remota della connessione (ad esempio, lo switch) per problemi.
Prima di iniziare a controllare i cavi, tuttavia, è una buona idea assicurarsi che l'interfaccia non sia solo disabilitata. L'esecuzione di un comando per visualizzare l'interfaccia può escludere questo problema:
# ip link set eth0 up
L'output di ip link show può essere difficile da analizzare a una rapida occhiata. Fortunatamente, il -br switch stampa questo output in un formato tabella molto più leggibile:
# ip -br link show
lo UNKNOWN 00:00:00:00:00:00 <LOOPBACK,UP,LOWER_UP>
eth0 UP 52:54:00:82:d6:6e <BROADCAST,MULTICAST,UP,LOWER_UP>
Sembra ip link set eth0 up ha fatto il trucco ed eth0 è tornato in attività.
Questi comandi sono ottimi per risolvere problemi fisici evidenti, ma per quanto riguarda problemi più insidiosi? Le interfacce possono negoziare alla velocità errata, oppure collisioni e problemi del livello fisico possono causare la perdita o il danneggiamento dei pacchetti, con conseguenti costose ritrasmissioni. Come iniziamo a risolvere questi problemi?
Possiamo usare i -s contrassegnare con il ip comando per stampare statistiche aggiuntive su un'interfaccia. L'output seguente mostra un'interfaccia per lo più pulita, con solo pochi pacchetti di ricezione persi e nessun altro segno di problemi a livello fisico:
# ip -s link show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 52:54:00:82:d6:6e brd ff:ff:ff:ff:ff:ff
RX: bytes packets errors dropped overrun mcast
34107919 5808 0 6 0 0
TX: bytes packets errors dropped carrier collsns
434573 4487 0 0 0 0
Per una risoluzione dei problemi di livello 1 più avanzata, ethtool l'utilità è un'opzione eccellente. Un caso d'uso particolarmente valido per questo comando è verificare se un'interfaccia ha negoziato la velocità corretta. Un'interfaccia che ha negoziato la velocità errata (ad es. un'interfaccia a 10 Gbps che riporta solo velocità di 1 Gbps) può essere un indicatore di un problema hardware/di cablaggio o di una configurazione errata di negoziazione su un lato del collegamento (ad es. una porta dello switch configurata in modo errato).
I nostri risultati potrebbero assomigliare a questo:
# ethtool eth0
Settings for eth0:
Supported ports: [ TP ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Supported pause frame use: Symmetric
Supports auto-negotiation: Yes
Supported FEC modes: Not reported
Advertised link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Advertised pause frame use: Symmetric
Advertised auto-negotiation: Yes
Advertised FEC modes: Not reported
Speed: 1000Mb/s
Duplex: Full
Port: Twisted Pair
PHYAD: 1
Transceiver: internal
Auto-negotiation: on
MDI-X: on (auto)
Supports Wake-on: d
Wake-on: d
Current message level: 0x00000007 (7)
drv probe link
Link detected: yes
Nota che l'output sopra mostra un collegamento che ha negoziato correttamente a una velocità di 1000 Mbps e full-duplex.
Livello 2:il livello di collegamento dati
Il livello di collegamento dati è responsabile di locale connettività di rete; essenzialmente, la comunicazione di frame tra host sullo stesso dominio di livello 2 (comunemente chiamato rete locale). Il protocollo Layer 2 più rilevante per la maggior parte degli amministratori di sistema è l'Address Resolution Protocol (ARP), che mappa gli indirizzi IP Layer 3 agli indirizzi MAC Ethernet Layer 2. Quando un host tenta di contattare un altro host sulla sua rete locale (come il gateway predefinito), probabilmente ha l'indirizzo IP dell'altro host, ma non conosce l'indirizzo MAC dell'altro host. ARP risolve questo problema e calcola l'indirizzo MAC per noi.
Un problema comune che potresti incontrare è una voce ARP che non verrà popolata, in particolare per il gateway predefinito del tuo host. Se il tuo localhost non riesce a risolvere correttamente l'indirizzo MAC di livello 2 del gateway, non sarà in grado di inviare traffico a reti remote. Questo problema potrebbe essere causato dalla configurazione dell'indirizzo IP errato per il gateway o da un altro problema, ad esempio una porta dello switch configurata in modo errato.
Possiamo controllare le voci nella nostra tabella ARP con il ip neighbor comando:
# ip neighbor show
192.168.122.1 dev eth0 lladdr 52:54:00:11:23:84 REACHABLE
Nota che l'indirizzo MAC del gateway è popolato (parleremo di più su come trovare il tuo gateway nella prossima sezione). Se si verificasse un problema con ARP, vedremmo un errore di risoluzione:
# ip neighbor show
192.168.122.1 dev eth0 FAILED
Un altro uso comune di ip neighbor comando implica la manipolazione della tabella ARP. Immagina che il tuo team di rete abbia appena sostituito il router a monte (che è il gateway predefinito del tuo server). Anche l'indirizzo MAC potrebbe essere cambiato poiché gli indirizzi MAC sono indirizzi hardware assegnati in fabbrica.
Nota: Sebbene gli indirizzi MAC univoci siano assegnati ai dispositivi in fabbrica, è possibile modificarli o contraffarli. Molte reti moderne spesso utilizzano anche protocolli come il Virtual Router Redundancy Protocol (VRRP), che utilizza un indirizzo MAC generato.
Linux memorizza nella cache la voce ARP per un periodo di tempo, quindi potresti non essere in grado di inviare traffico al gateway predefinito fino al timeout della voce ARP per il gateway. Per sistemi molto importanti, questo risultato è indesiderabile. Fortunatamente, puoi eliminare manualmente una voce ARP, che forzerà un nuovo processo di rilevamento ARP:
# ip neighbor show
192.168.122.170 dev eth0 lladdr 52:54:00:04:2c:5d REACHABLE
192.168.122.1 dev eth0 lladdr 52:54:00:11:23:84 REACHABLE
# ip neighbor delete 192.168.122.170 dev eth0
# ip neighbor show
192.168.122.1 dev eth0 lladdr 52:54:00:11:23:84 REACHABLE
Nell'esempio sopra, vediamo una voce ARP popolata per 192.168.122.70 su eth0. Quindi eliminiamo la voce ARP e possiamo vedere che è stata rimossa dalla tabella.
Livello 3:il livello rete/internet
Il livello 3 prevede l'utilizzo di indirizzi IP, che dovrebbero essere familiari a qualsiasi amministratore di sistema. L'indirizzamento IP fornisce agli host un modo per raggiungere altri host che si trovano al di fuori della loro rete locale (sebbene li usiamo spesso anche su reti locali). Uno dei primi passaggi per la risoluzione dei problemi è il controllo dell'indirizzo IP locale di una macchina, che può essere eseguito con l'ip address comando, sempre utilizzando il -br flag per semplificare l'output:
# ip -br address show
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.135/24 fe80::184e:a34d:1d37:441a/64 fe80::c52f:d96e:a4a2:743/64
Possiamo vedere che la nostra interfaccia eth0 ha un indirizzo IPv4 di 192.168.122.135. Se non avessimo un indirizzo IP, vorremmo risolvere il problema. La mancanza di un indirizzo IP può essere causata da un'errata configurazione locale, come un file di configurazione dell'interfaccia di rete non corretto, oppure può essere causata da problemi con DHCP.
Lo strumento di prima linea più comune utilizzato dalla maggior parte degli amministratori di sistema per risolvere i problemi del livello 3 è il ping utilità. Ping invia un pacchetto ICMP Echo Request a un host remoto e si aspetta una risposta ICMP Echo in cambio. Se riscontri problemi di connettività con un host remoto, ping è un'utilità comune per iniziare la risoluzione dei problemi. L'esecuzione di un semplice ping dalla riga di comando invia echi ICMP all'host remoto indefinitamente; dovrai premere CTRL+C per terminare il ping o passare il -c <num pings> flag, in questo modo:
# ping www.google.com
PING www.google.com (172.217.165.4) 56(84) bytes of data.
64 bytes from yyz12s06-in-f4.1e100.net (172.217.165.4): icmp_seq=1 ttl=54 time=12.5 ms
64 bytes from yyz12s06-in-f4.1e100.net (172.217.165.4): icmp_seq=2 ttl=54 time=12.6 ms
64 bytes from yyz12s06-in-f4.1e100.net (172.217.165.4): icmp_seq=3 ttl=54 time=12.5 ms
^C
--- www.google.com ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2002ms
rtt min/avg/max/mdev = 12.527/12.567/12.615/0.036 ms
Si noti che ogni ping include la quantità di tempo necessaria per ricevere una risposta. Mentre ping può essere un modo semplice per capire se un host è vivo e risponde, non è affatto definitivo. Molti operatori di rete bloccano i pacchetti ICMP come precauzione di sicurezza, sebbene molti altri non siano d'accordo con questa pratica. Un altro trucco comune è fare affidamento sul campo del tempo come indicatore accurato della latenza di rete. I pacchetti ICMP possono essere limitati in termini di velocità da dispositivi di rete intermedi e non dovrebbero essere considerati affidabili per fornire rappresentazioni reali della latenza dell'applicazione.
Lo strumento successivo nella cintura degli strumenti per la risoluzione dei problemi di livello 3 è il traceroute comando. Traceroute sfrutta il campo Time to Live (TTL) nei pacchetti IP per determinare il percorso che il traffico intraprende verso la sua destinazione. Traceroute invierà un pacchetto alla volta, iniziando con un TTL di uno. Poiché il pacchetto scade durante il transito, il router upstream restituisce un pacchetto ICMP Time-to-Live Exceeded. Traceroute quindi incrementa il TTL per determinare il salto successivo. L'output risultante è un elenco di router intermedi che un pacchetto ha attraversato nel suo percorso verso la destinazione:
# traceroute www.google.com
traceroute to www.google.com (172.217.10.36), 30 hops max, 60 byte packets
1 acritelli-laptop (192.168.122.1) 0.103 ms 0.057 ms 0.027 ms
2 192.168.1.1 (192.168.1.1) 5.302 ms 8.024 ms 8.021 ms
3 142.254.218.133 (142.254.218.133) 20.754 ms 25.862 ms 25.826 ms
4 agg58.rochnyei01h.northeast.rr.com (24.58.233.117) 35.770 ms 35.772 ms 35.754 ms
5 agg62.hnrtnyaf02r.northeast.rr.com (24.58.52.46) 25.983 ms 32.833 ms 32.864 ms
6 be28.albynyyf01r.northeast.rr.com (24.58.32.70) 43.963 ms 43.067 ms 43.084 ms
7 bu-ether16.nycmny837aw-bcr00.tbone.rr.com (66.109.6.74) 47.566 ms 32.169 ms 32.995 ms
8 0.ae1.pr0.nyc20.tbone.rr.com (66.109.6.163) 27.277 ms * 0.ae4.pr0.nyc20.tbone.rr.com (66.109.1.35) 32.270 ms
9 ix-ae-6-0.tcore1.n75-new-york.as6453.net (66.110.96.53) 32.224 ms ix-ae-10-0.tcore1.n75-new-york.as6453.net (66.110.96.13) 36.775 ms 36.701 ms
10 72.14.195.232 (72.14.195.232) 32.041 ms 31.935 ms 31.843 ms
11 * * *
12 216.239.62.20 (216.239.62.20) 70.011 ms 172.253.69.220 (172.253.69.220) 83.370 ms lga34s13-in-f4.1e100.net (172.217.10.36) 38.067 ms
Traceroute sembra un ottimo strumento, ma è importante comprenderne i limiti. Come con ICMP, i router intermedi possono filtrare i pacchetti che traceroute si basa, come il messaggio ICMP Time-to-Live Exceeded. Ma soprattutto, il percorso che il traffico prende da e verso una destinazione non è necessariamente simmetrico e non è sempre lo stesso. Traceroute può indurti a pensare che il tuo traffico segua un percorso piacevole e lineare da e verso la sua destinazione. Tuttavia, questa situazione è raramente il caso. Il traffico può seguire un percorso di ritorno diverso e i percorsi possono cambiare dinamicamente per molte ragioni. Mentre traceroute può fornire rappresentazioni accurate del percorso nelle reti aziendali di piccole dimensioni, spesso non è accurato quando si tenta di tracciare su reti di grandi dimensioni o Internet.
Un altro problema comune in cui probabilmente ti imbatterai è la mancanza di un gateway a monte per un percorso particolare o la mancanza di un percorso predefinito. Quando un pacchetto IP viene inviato a una rete diversa, deve essere inviato a un gateway per un'ulteriore elaborazione. Il gateway dovrebbe sapere come instradare il pacchetto alla sua destinazione finale. L'elenco dei gateway per percorsi diversi è archiviato in una tabella di routing , che può essere ispezionato e manipolato utilizzando ip route comandi.
Possiamo stampare la tabella di routing utilizzando ip route show comando:
# ip route show
default via 192.168.122.1 dev eth0 proto dhcp metric 100
192.168.122.0/24 dev eth0 proto kernel scope link src 192.168.122.135 metric 100
Le topologie semplici spesso hanno solo un gateway predefinito configurato, rappresentato dalla voce "predefinito" nella parte superiore della tabella. Un gateway predefinito mancante o errato è un problema comune.
Se la nostra topologia è più complessa e richiediamo percorsi diversi per reti diverse, possiamo controllare il percorso per un prefisso specifico:
# ip route show 10.0.0.0/8
10.0.0.0/8 via 192.168.122.200 dev eth0
Nell'esempio sopra, stiamo inviando tutto il traffico destinato alla rete 10.0.0.0/8 a un gateway diverso (192.168.122.200).
Sebbene non sia un protocollo di livello 3, vale la pena menzionare il DNS mentre parliamo di indirizzamento IP. Tra le altre cose, il Domain Name System (DNS) traduce gli indirizzi IP in nomi leggibili dall'uomo, come www.redhat.com . I problemi DNS sono estremamente comuni e talvolta sono opachi per la risoluzione dei problemi. Molti libri e guide online sono stati scritti su DNS, ma qui ci concentreremo sulle basi.
Un segno rivelatore di problemi con il DNS è la possibilità di connettersi a un host remoto tramite l'indirizzo IP ma non il suo nome host. Esecuzione di un rapido nslookup sul nome host può dirci un bel po' (nslookup fa parte di bind-utils pacchetto su sistemi basati su Red Hat Enterprise Linux):
# nslookup www.google.com
Server: 192.168.122.1
Address: 192.168.122.1#53
Non-authoritative answer:
Name: www.google.com
Address: 172.217.3.100
L'output sopra mostra al server che la ricerca è stata eseguita su 192.168.122.1 e l'indirizzo IP risultante era 172.217.3.100.
Se esegui un nslookup per un host ma ping o traceroute prova a utilizzare un indirizzo IP diverso, probabilmente stai riscontrando un problema di immissione del file host. Di conseguenza, controlla se il file host presenta problemi:
# nslookup www.google.com
Server: 192.168.122.1
Address: 192.168.122.1#53
Non-authoritative answer:
Name: www.google.com
Address: 172.217.12.132
# ping -c 1 www.google.com
PING www.google.com (1.2.3.4) 56(84) bytes of data.
^C
--- www.google.com ping statistics ---
1 packets transmitted, 0 received, 100% packet loss, time 0ms
# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
1.2.3.4 www.google.com
Nota che nell'esempio sopra, l'indirizzo per www.google.com deliberato in 172.217.12.132. Tuttavia, quando abbiamo provato a eseguire il ping dell'host, il traffico veniva inviato a 1.2.3.4. Dai un'occhiata a /etc/hosts file, possiamo vedere un override che qualcuno deve aver aggiunto con noncuranza. I problemi di sostituzione del file host sono estremamente comune, soprattutto se lavori con sviluppatori di applicazioni che spesso devono eseguire queste sostituzioni per testare il loro codice durante lo sviluppo.
Livello 4:il livello di trasporto
Il livello di trasporto è costituito dai protocolli TCP e UDP, con TCP essendo un protocollo orientato alla connessione e UDP senza connessione. Le applicazioni sono in ascolto su prese , che consistono in un indirizzo IP e una porta. Il traffico destinato a un indirizzo IP su una porta specifica sarà indirizzato all'applicazione in ascolto dal kernel. Una discussione completa di questi protocolli va oltre lo scopo di questo articolo, quindi ci concentreremo su come risolvere i problemi di connettività a questi livelli.
La prima cosa che potresti voler fare è vedere quali porte sono in ascolto su localhost. Il risultato può essere utile se non riesci a connetterti a un particolare servizio sulla macchina, come un server Web o SSH. Un altro problema comune si verifica quando un demone o un servizio non si avvia a causa di qualcos'altro in ascolto su una porta. Il ss comando è prezioso per eseguire questi tipi di azioni:
# ss -tunlp4
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port
udp UNCONN 0 0 *:68 *:* users:(("dhclient",pid=3167,fd=6))
udp UNCONN 0 0 127.0.0.1:323 *:* users:(("chronyd",pid=2821,fd=1))
tcp LISTEN 0 128 *:22 *:* users:(("sshd",pid=3366,fd=3))
tcp LISTEN 0 100 127.0.0.1:25 *:* users:(("master",pid=3600,fd=13))
Analizziamo questi flag:
- -t - Mostra le porte TCP.
- -u - Mostra le porte UDP.
- -n - Non cercare di risolvere i nomi host.
- -l - Mostra solo le porte di ascolto.
- -p - Mostra i processi che stanno utilizzando un particolare socket.
- -4 - Mostra solo socket IPv4.
Dando un'occhiata all'output, possiamo vedere diversi servizi di ascolto. Il sshd l'applicazione è in ascolto sulla porta 22 su tutti gli indirizzi IP, indicati dal *:22 uscita.
Il ss command è uno strumento potente e una revisione della sua breve pagina man può aiutarti a individuare i flag e le opzioni per trovare quello che stai cercando.
Un altro scenario comune per la risoluzione dei problemi riguarda la connettività remota. Immagina che la tua macchina locale non possa connettersi a una porta remota, come MySQL sulla porta 3306. Uno strumento improbabile, ma comunemente installato, può essere tuo amico quando risolvi questi tipi di problemi:telnet . Il telnet Il comando tenta di stabilire una connessione TCP con qualsiasi host e porta gli venga fornita. Questa funzione è perfetta per testare la connettività TCP remota:
# telnet database.example.com 3306
Trying 192.168.1.10...
^C
Nell'output sopra, telnet si blocca finché non lo uccidiamo. Questo risultato ci dice che non possiamo raggiungere la porta 3306 sulla macchina remota. Forse l'applicazione non è in ascolto e dobbiamo utilizzare i precedenti passaggi per la risoluzione dei problemi utilizzando ss sull'host remoto, se abbiamo accesso. Un'altra possibilità è un host o un firewall intermedio che filtra il traffico. Potrebbe essere necessario collaborare con il team di rete per verificare la connettività di livello 4 lungo il percorso.
Telnet funziona bene per TCP, ma per quanto riguarda UDP? Il netcat strumento fornisce un modo semplice per controllare una porta UDP remota:
# nc 192.168.122.1 -u 80
test
Ncat: Connection refused.
Il netcat l'utilità può essere utilizzata per molte altre cose, incluso il test della connettività TCP. Nota che netcat potrebbe non essere installato sul tuo sistema ed è spesso considerato un rischio per la sicurezza lasciarlo in giro. Potresti prendere in considerazione la disinstallazione al termine della risoluzione dei problemi.
Gli esempi precedenti hanno discusso di utilità comuni e semplici. Tuttavia, uno strumento molto più potente è nmap . Interi libri sono stati dedicati a nmap funzionalità, quindi non lo tratteremo in questo articolo per principianti, ma dovresti conoscere alcune delle cose che è in grado di fare:
- Porta TCP e UDP che esegue la scansione di macchine remote.
- Impronte digitali del sistema operativo.
- Determinare se le porte remote sono chiuse o semplicemente filtrate.
Conclusione
In questo articolo abbiamo trattato molti argomenti di rete introduttivi, risalendo lo stack di rete da cavi e switch a indirizzi IP e porte. Gli strumenti discussi qui dovrebbero darti un buon punto di partenza per la risoluzione dei problemi di connettività di rete di base e dovrebbero rivelarsi utili quando si cerca di fornire quanti più dettagli possibili al team di rete.
Man mano che avanzi nel tuo percorso di risoluzione dei problemi di rete, ti imbatterai senza dubbio in flag di comando precedentemente sconosciuti, battute fantasiose e nuovi potenti strumenti (tcpdump e Wireshark sono i miei preferiti) per approfondire le cause dei tuoi problemi di rete. Divertiti e ricorda:i pacchetti non mentono!