Se lavori principalmente su riga di comando e gestisci molti file di testo ogni giorno, dovresti essere a conoscenza di Uniq comando.
Il comando Uniq ti aiuta a trovare facilmente righe ripetute e duplicate da un file. Uniq non serve solo per trovare duplicati, ma anche per rimuovere i duplicati, visualizzare il numero di occorrenze delle righe duplicate, visualizzare solo le righe ripetute e visualizzare solo le righe univoche ecc.
Si noti che il comando 'uniq' non rileverà righe ripetute a meno che non siano adiacenti. Quindi, potrebbe essere necessario ordinarli prima o combinare il comando sort con uniq per ottenere i risultati. Permettetemi di mostrarvi alcuni esempi.
Poiché il comando uniq fa parte del pacchetto coreutils di GNU, viene preinstallato nella maggior parte delle distribuzioni Linux. Quindi, non preoccupiamoci dell'installazione e vediamo alcuni esempi pratici di comandi Uniq.
Esempi di comandi Uniq
Per prima cosa, creiamo un file con alcune righe duplicate.
$ vi ostechnix.txt
welcome to ostechnix welcome to ostechnix Linus is the creator of Linux. Linux is secure by default Linus is the creator of Linux. Top 500 super computers are powered by Linux
Come puoi vedere nel file sopra, abbiamo poche righe ripetute (la prima, la seconda, la terza e la quinta riga sono duplicate).
1. Rimuovere le righe duplicate consecutive in un file utilizzando il comando Uniq
Se usi il comando 'uniq' senza argomenti, rimuoverà tutte le righe duplicate consecutive e visualizzerà solo le righe univoche.
$ uniq ostechnix.txt
Risultato di esempio:
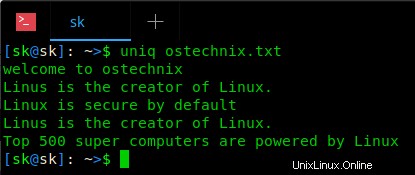
Come puoi vedere, il comando uniq ha rimosso tutte le righe duplicate consecutive nel file specificato. Potresti anche aver notato che l'output sopra ha ancora i duplicati nella seconda e nella quarta riga. È perché il comando uniq ometterà le righe ripetute solo se sono adiacenti. Ovviamente possiamo rimuovere anche quei duplicati non consecutivi. Guarda il secondo esempio qui sotto.
2. Rimuovi tutte le righe duplicate
$ sort ostechnix.txt | uniq
Risultato di esempio:
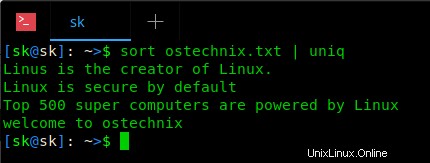
Vedere? Non ci sono duplicati o righe ripetute. In altre parole, il comando precedente visualizzerà ogni riga una volta dal file ostechnix.txt .
Nell'esempio sopra abbiamo usato il comando sort insieme a uniq, perché, come ho già detto, uniq non troverà le righe duplicate/ripetute a meno che non siano adiacenti.
3. Visualizza solo righe univoche da un file
Per visualizzare solo le righe univoche di un file, il comando sarebbe:
$ sort ostechnix.txt | uniq -u
Risultato di esempio:
Linux is secure by default Top 500 super computers are powered by Linux
Come puoi vedere, abbiamo solo due righe univoche nel file specificato.
4. Visualizza solo righe duplicate
Allo stesso modo, possiamo anche visualizzare righe duplicate da un file come di seguito.
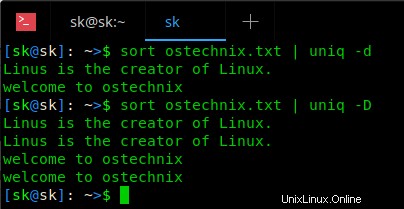
$ sort ostechnix.txt | uniq -d
Risultato di esempio:
Linus is the creator of Linux. welcome to ostechnix
Queste due sono le righe ripetute/duplicate nel file ostechnix.txt. Tieni presente che -d (d minuscola) stampa solo righe duplicate , uno per ogni gruppo . Per stampare tutte le righe duplicate , usa -D (d maiuscola) come di seguito.
$ sort ostechnix.txt | uniq -D
Guarda la differenza tra i due flag nello screenshot qui sotto.
5. Visualizza il numero di occorrenze di ogni riga in un file
Per qualche motivo, potresti voler controllare quante volte una riga viene ripetuta nel file specificato. Per farlo, usa -c segnala come sotto.
$ sort ostechnix.txt | uniq -c
Risultato di esempio:
2 Linus is the creator of Linux. 1 Linux is secure by default 1 Top 500 super computers are powered by Linux 2 welcome to ostechnix
Possiamo anche visualizzare il numero di occorrenze di ciascuna riga insieme a quella riga, ordinate in base al comando più frequente:
$ sort ostechnix.txt | uniq -c | sort -nr
Risultato di esempio:
2 welcome to ostechnix 2 Linus is the creator of Linux. 1 Top 500 super computers are powered by Linux 1 Linux is secure by default
6. Limita il confronto a 'N' caratteri
Il comando Uniq ci consente di limitare il confronto a un determinato numero di caratteri di righe in un file utilizzando -w bandiera. Ad esempio, limitiamo il confronto ai primi 4 caratteri di righe in un file e mostriamo le righe ripetute come mostrato di seguito.
$ uniq -d -w 4 ostechnix.txt
7. Evita il confronto con le prime 'N' caratteri
Come il confronto dei limiti a N caratteri di righe in un file, possiamo anche evitare di confrontare i primi N caratteri usando -s bandiera.
Il comando seguente eviterà il confronto con i primi 4 caratteri delle righe di un file:
$ uniq -d -s 4 ostechnix.txt
Per evitare di confrontare i primi N campi invece dei caratteri, usa il flag '-f' nel comando precedente.
Per maggiori dettagli, fare riferimento alla sezione della guida;
$ uniq --help
e pagine man.
$ man uniq
Leggi anche:
- Esercitazione sul comando piega con esempi per principianti