Alcune aziende non possono consentire che i propri servizi non siano disponibili. In caso di interruzione del server, un operatore cellulare potrebbe riscontrare tempi di inattività del sistema di fatturazione che causano la perdita della connessione per tutti i suoi client. L'ammissione del potenziale impatto di tali situazioni porta all'idea di avere sempre un piano B.
In questo articolo stiamo facendo luce su diversi modi di protezione contro i guasti del server, nonché sulle architetture utilizzate per l'implementazione di VMmanager Cloud, un pannello di controllo per la creazione di un cluster ad alta disponibilità.

Prefazione
La terminologia nell'area della tolleranza dei cluster varia da sito Web a sito Web. Per evitare di confondere termini e definizioni diversi, delineiamo quelli che verranno utilizzati nell'articolo indicato:
- La tolleranza ai guasti (FT) è la capacità di un sistema di continuare a funzionare dopo il guasto di uno dei suoi componenti.
- Il cluster è un gruppo di server (nodi cluster) collegati tramite canali di comunicazione.
- Fault Tolerant Cluster (FTC) è un cluster in cui il guasto di un server non comporta la completa indisponibilità dell'intero cluster. Le funzioni del nodo guasto vengono riassegnate automaticamente tra i nodi rimanenti.
- Disponibilità continua (CA) significa che un utente può utilizzare il servizio senza subire timeout. Non importa quanto tempo è passato da quando il nodo non è riuscito.
- Alta disponibilità (HA) significa che un utente potrebbe riscontrare timeout del servizio nel caso in cui uno dei nodi si interrompa; tuttavia, il sistema verrà ripristinato automaticamente con tempi di fermo minimi.
- Il cluster CA è un cluster a disponibilità continua.
- Il cluster HA è un cluster ad alta disponibilità.
Lascia che sia necessario distribuire un cluster composto da 10 nodi con macchine virtuali in esecuzione su ogni nodo. L'obiettivo è proteggere le macchine virtuali dopo l'errore del server. I server con doppia CPU vengono utilizzati per massimizzare la densità di calcolo dei rack.
A prima vista, l'opzione più interessante per un'azienda è distribuire un cluster di disponibilità continua quando un servizio è ancora fornito dopo che l'apparecchiatura si è guastata. In effetti, la disponibilità continua è un must se è necessario mantenere il funzionamento di un sistema di fatturazione o automatizzare un processo di produzione continuo. Tuttavia, questo approccio ha anche le sue trappole e insidie che sono trattate di seguito.
Disponibilità continua
La continuità di un servizio è possibile solo se viene creata una copia esatta di una macchina fisica o virtuale con questo servizio, disponibile in qualsiasi momento. Tale modello di ridondanza è chiamato 2N. La creazione di una copia del server dopo che l'apparecchiatura si era guastata richiedeva tempo, causando il timeout del servizio. Inoltre in questo caso non sarebbe possibile recuperare il dump della RAM dal server guasto, il che significa che tutte le informazioni in esso contenute sarebbero sparite.
Esistono due metodi utilizzati per fornire CA:a livello hardware e software. Concentriamoci su ciascuno di essi in modo più dettagliato.
Il metodo hardware rappresenta un doppio server in cui tutti i componenti sono duplicati e i calcoli vengono eseguiti simultaneamente e indipendentemente. La sincronizzazione si ottiene utilizzando un nodo dedicato che verifica i risultati provenienti da entrambe le parti. Se il nodo rileva una discrepanza, tenta di definire il problema e correggere gli errori. Se l'errore non può essere corretto, il sistema spegne il modulo guasto.
Stratus, un produttore di server CA, garantisce che il tempo di inattività complessivo del sistema non superi i 32 secondi all'anno. Tali risultati possono essere raggiunti utilizzando l'attrezzatura speciale. Secondo i rappresentanti di Stratus, il costo di un server CA con doppia CPU per ciascun modulo sincronizzato è di circa $ 160.000 a seconda delle specifiche. Il prezzo esteso per l'intero cluster CA in questo caso sarebbe di $ 1 600 000.
Il metodo software
Lo strumento software più diffuso per la distribuzione di un cluster a disponibilità continua al momento dell'articolo è VMware vSphere. La tecnologia di disponibilità continua di questo prodotto si chiama Fault Tolerance.
A differenza del metodo hardware, questa tecnologia ha determinati requisiti, come i seguenti:
- CPU sull'host fisico:
- Intel con architettura Sandy Bridge (o più recente). Avoton non è supportato.
- AMD Bulldozer (o più recente).
- Le macchine con Fault Tolerance devono essere collegate a una rete da 10 Gb con bassa latenza. VMware consiglia vivamente di utilizzare una rete dedicata.
- Non più di 4 CPU virtuali per VM.
- Non più di 8 CPU virtuali per host fisico.
- Non più di 4 macchine virtuali per host fisico.
- Gli snapshot della macchina virtuale non sono disponibili.
- Lo storage vMotion non è disponibile.
L'elenco completo delle limitazioni e delle incompatibilità è disponibile nella documentazione ufficiale.
La licenza di vSphere si basa su CPU fisiche. Il prezzo parte da $ 1750 per licenza + $ 550 per abbonamento annuale e supporto. L'automazione della gestione dei cluster richiede anche VMware vCenter Server che costa oltre $ 8000. Il modello 2N viene utilizzato per fornire la disponibilità continua, quindi è necessario acquistare 10 server replicati con licenze per ciascuno di essi al fine di costruire un cluster con 10 nodi con macchine virtuali.
Il costo complessivo del software sarebbe 2[Numero di CPU per server]*(10[Numero di nodi con macchine virtuali]+10[Numero di nodi replicati])*(1750+550)[Costo di licenza per ciascuna CPU]+8000 [Costo del server VMware vCenter]=$ 100 000. Tutti i prezzi sono arrotondati.
Le configurazioni dei nodi specifiche non sono descritte in questo articolo poiché i componenti del server differiscono sempre a seconda dello scopo del cluster. Anche le apparecchiature di rete non sono descritte poiché dovrebbero essere identiche in ogni caso. Questo articolo si concentra su quei componenti che potrebbero sicuramente variare, ovvero il costo della licenza.
È anche importante menzionare i prodotti che non sono più sviluppati e supportati.
Il prodotto chiamato Remus si basa sulla virtualizzazione Xen. È una soluzione open source gratuita che utilizza la tecnologia micro snapshot. Sfortunatamente la sua documentazione non è stata aggiornata per molto tempo:la guida all'installazione fornisce istruzioni per Ubuntu 12.10 la cui fine vita è stata annunciata nel 2014. Anche la ricerca su Google non ha trovato nessuna azienda che utilizzasse Remus per le proprie operazioni.
Sono stati fatti tentativi per modificare QEMU per creare cluster di disponibilità continua su questa tecnologia. Ci sono due progetti che hanno annunciato il loro lavoro in questa direzione.
Il primo è Kemari, un prodotto open source guidato da Yoshiaki Tamura. Questo progetto intendeva utilizzare la migrazione QEMU in tempo reale. L'ultimo impegno è stato effettuato nel febbraio 2011, il che suggerisce che lo sviluppo ha raggiunto un punto morto e non sarà continuato.
Il secondo prodotto è Micro Checkpointing, un progetto open source fondato da Michael Hines. Nessuna attività è stata trovata nel suo registro delle modifiche nell'ultimo anno, che ricorda il progetto Kemari.
Questi fatti ci consentono di trarre la conclusione che semplicemente non esiste alcuna possibilità di disponibilità continua sulla virtualizzazione KVM fino a questa data.
Nonostante tutti i vantaggi dei sistemi di disponibilità continua, ci sono molti ostacoli sul modo di implementare e utilizzare tali soluzioni. Tuttavia, in alcuni casi potrebbe essere richiesta la tolleranza ai guasti, ma senza la necessità di essere continuamente disponibile. Tali scenari consentono di utilizzare cluster con disponibilità elevata.
Alta disponibilità
Un cluster ad alta disponibilità fornisce la tolleranza ai guasti rilevando automaticamente se l'hardware è inattivo e successivamente avviando il servizio sul nodo disponibile.
High Availability non supporta la sincronizzazione delle CPU avviate sui nodi e non sempre consente di sincronizzare i dischi locali. Tenendo presente questo, si consiglia di individuare le unità utilizzate dai nodi in una memoria separata e indipendente come la memoria di rete.
Il motivo è chiaro:il nodo non può essere raggiunto dopo il suo errore e le informazioni dal suo dispositivo di archiviazione non possono essere recuperate. Anche il sistema di archiviazione dei dati dovrebbe essere a tolleranza di errore, altrimenti non vi è alcuna possibilità per l'alta disponibilità. Di conseguenza, il cluster High Availability è costituito da due sottocluster:
- Cluster di elaborazione costituito da nodi con macchine virtuali
- Cluster di archiviazione con dischi utilizzati dai nodi di calcolo.
Al momento esistono le seguenti soluzioni utilizzate per implementare cluster High Availability con macchine virtuali su nodi cluster:
- Battito cardiaco, versione 1.? con DRBD;
- Pacemaker;
- VMware vSphere;
- Proxmox VE;
- XenServer;
- OpenStack;
- oVirt;
- Red Hat Enterprise Virtualization;
- Gruppo di failover di Windows Server con ruolo del server Hyper-V;
- VMmanager Cloud.
Diamo uno sguardo più da vicino a VMmanager Cloud.
VMmanager Cloud
VMmanager Cloud è un prodotto che consente di distribuire cluster ad alta disponibilità e utilizza la virtualizzazione QEMU-KVM. Questa tecnologia è stata scelta perché attivamente sviluppata e supportata e permette di installare qualsiasi sistema operativo su una macchina virtuale. Il prodotto utilizza Corosync per rilevare la disponibilità del cluster. Se uno dei server è inattivo, VMmanager distribuisce le sue macchine virtuali tra i nodi rimanenti uno per uno.
Nella forma semplificata questo meccanismo funziona come segue:
- Il sistema identifica il nodo del cluster con il numero più basso di macchine virtuali.
- Verifica se c'è abbastanza RAM per localizzare la macchina.
- Se c'è memoria sufficiente su un nodo per la macchina pertinente, VMmanager crea una nuova macchina virtuale su questo nodo.
- Se non c'è memoria sufficiente, il sistema controlla gli altri nodi con più macchine virtuali.
Il test di alcune configurazioni hardware e la richiesta di molti utenti attuali di VMmanager Cloud hanno identificato che normalmente sono necessari 45-90 secondi per distribuire e ripristinare il funzionamento di tutte le VM dal nodo guasto, a seconda delle prestazioni dell'apparecchiatura.
Si consiglia di dedicare uno o più nodi come protezione contro le situazioni di emergenza e di non distribuire macchine virtuali su questi nodi durante il funzionamento di routine. Riduce al minimo le possibilità di mancanza di risorse sui nodi del cluster live per l'aggiunta di macchine virtuali dal nodo guasto. Nel caso in cui venga utilizzato un solo nodo di backup, tale modello di sicurezza viene chiamato N+1.
VMmanager Cloud supporta i seguenti tipi di storage:file system, LVM, Network LVM, iSCSI e Ceph [in particolare RBD (RADOS Block Device), una delle implementazioni Ceph]. Gli ultimi tre sono usati per l'alta disponibilità.
Una licenza a vita per dieci nodi operativi e un nodo di backup costano € 3520, o $ 3865 fino a questa data (una licenza costa € 320 per nodo indipendentemente dal numero di CPU). La licenza include un anno di aggiornamenti gratuiti; a partire dal secondo anno sono previsti aggiornamenti per modello di abbonamento al prezzo di 880€ annui per l'intero cluster.
Controlliamo come VMmanager Cloud è già stato utilizzato per l'implementazione di cluster ad alta disponibilità.
Primo Byte
FirstByte ha iniziato a fornire l'hosting cloud nel febbraio 2016. Inizialmente il loro cluster era basato su OpenStack; tuttavia la mancanza di specialisti per questo sistema sia in termini di disponibilità che di costo li ha spinti a cercare una soluzione alternativa. Il nuovo sistema per la creazione di un cluster ad alta disponibilità doveva soddisfare i seguenti requisiti:
- Possibilità di distribuire macchine virtuali KVM.
- Integrazione con Ceph.
- Integrazione con un sistema di fatturazione per l'offerta dei servizi esistenti.
- Costo della licenza accessibile.
- Supporto da parte dello sviluppatore del software.
VMmanager Cloud soddisfa tutti i requisiti.
Caratteristiche distintive del cluster FirstByte:
- Il trasferimento dei dati si basa sulla tecnologia Ethernet e su apparecchiature Cisco.
- Il routing viene eseguito utilizzando Cisco ASR9001. Il cluster utilizza circa 50000 indirizzi IPv6.
- La velocità di collegamento tra i nodi di elaborazione e gli switch è di 10 Gbps.
- La velocità di trasferimento dei dati tra switch e nodi di archiviazione è di 20 Gbps, con due canali combinati a 10 Gbps ciascuno.
- Un collegamento separato a 20 Gbps viene utilizzato tra i rack con nodi di archiviazione per la replica.
- I dischi SAS in combinazione con gli SSD sono installati su tutti i nodi di archiviazione.
- Il tipo di archiviazione è RBD.
Il layout del sistema è presentato di seguito:
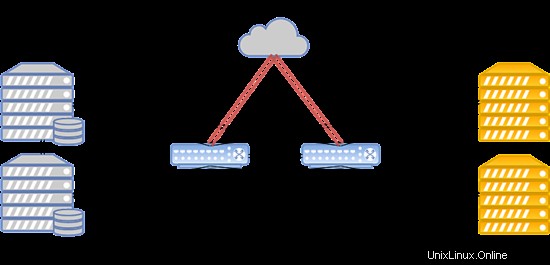
Tale configurazione funziona per ospitare siti Web, server di gioco e database popolari con un carico superiore alla media.
Primo VDS
FirstVDS fornisce i servizi del cluster fault-tolerant avviato a settembre 2015.
VMmanager Cloud è stato scelto per questo cluster a causa dei seguenti fattori:
- Esperienza solida nell'utilizzo dei pannelli di controllo ISPsystem.
- Integrazione con BILLmanager per impostazione predefinita.
- Alta qualità del supporto tecnico.
- Integrazione con Ceph.
Il loro cluster ha le seguenti caratteristiche:
- Il trasferimento dei dati è basato su rete Infiniband con velocità di connessione a 56 Gbps;
- La rete Infiniband è costruita su apparecchiature Mellanox;
- I nodi di archiviazione hanno unità SSD;
- Il tipo di archiviazione è RBD.
Il sistema può essere strutturato nel modo seguente:
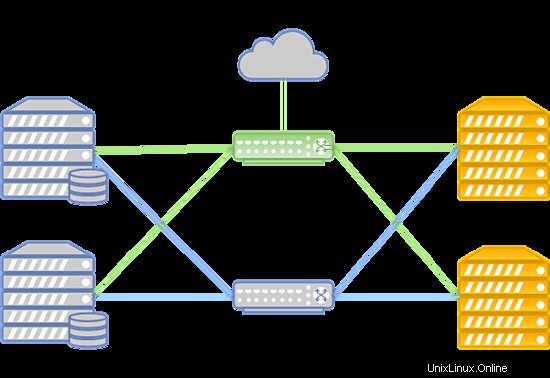
In caso di guasto della rete Infiniband, la connessione tra l'archiviazione su disco della VM e i server di elaborazione viene stabilita tramite la rete Ethernet distribuita su apparecchiature Juniper. La nuova connessione viene stabilita automaticamente.
Grazie all'elevata velocità di comunicazione con lo storage, questo cluster funziona perfettamente per ospitare siti Web con traffico elevatissimo, streaming di video e contenuti, nonché big data.
Conclusione
Riassumiamo i risultati chiave dell'articolo.
Il cluster di disponibilità continua è un must quando ogni secondo di inattività comporta perdite sostanziali. Se è consentita un'interruzione di 5 minuti mentre le macchine virtuali vengono distribuite su un nodo di backup, il cluster ad alta disponibilità può essere una buona opzione per ridurre i costi hardware e software.
È anche importante ricordare che l'unico modo per ottenere la tolleranza ai guasti è l'eccesso. Assicurati di replicare i tuoi server, apparecchiature di comunicazione dati e collegamenti, canali di accesso a Internet e alimentazione. Replica tutto quello che puoi. Tali misure consentono di eliminare colli di bottiglia e potenziali punti di guasto che possono causare tempi di fermo dell'intero sistema. Adottando le misure di cui sopra, puoi essere certo di disporre di un cluster a tolleranza di errore resistente ai guasti.
Se ritieni che il modello High Availability soddisfi le tue esigenze e VMmanager Cloud sia un buon strumento per realizzarlo, fai riferimento al manuale di installazione e alla documentazione per saperne di più sul sistema. io ti auguro operazioni continue e senza guasti!