Quando eseguiamo determinati comandi in Unix/Linux per leggere o modificare il testo da una stringa o un file, la maggior parte delle volte proviamo a filtrare l'output in una determinata sezione di interesse. È qui che torna utile usare le espressioni regolari.
Leggi anche: 10 utili operatori di concatenamento Linux con esempi pratici
Cosa sono le espressioni regolari?
Un'espressione regolare può essere definita come una stringa che rappresenta diverse sequenze di caratteri. Una delle cose più importanti delle espressioni regolari è che ti consentono di filtrare l'output di un comando o di un file, modificare una sezione di un testo o un file di configurazione e così via.
Caratteristiche dell'espressione regolare
Le espressioni regolari sono composte da:
- Caratteri ordinari come spazio, underscore(_), A-Z, a-z, 0-9.
- Meta caratteri che sono espansi ai caratteri ordinari, includono:
(.)corrisponde a qualsiasi singolo carattere tranne una nuova riga.(*)corrisponde a zero o più esistenze del carattere immediato che lo precede.[ character(s) ]corrisponde a uno qualsiasi dei caratteri specificati in carattere(i), si può anche usare un trattino(-)per indicare un intervallo di caratteri come[a-f],[1-5], e così via.^corrisponde all'inizio di una riga in un file.$corrisponde alla fine della riga in un file.\è un carattere di escape.
Per filtrare il testo, è necessario utilizzare uno strumento di filtraggio del testo come awk . Puoi pensare a awk come linguaggio di programmazione a sé stante. Ma per lo scopo di questa guida all'uso di awk , lo tratteremo come un semplice strumento di filtraggio della riga di comando.
La sintassi generale di awk è:
# awk 'script' filename
Dove 'script' è un insieme di comandi compresi da awk e vengono eseguiti su file, nomefile.
Funziona leggendo una determinata riga nel file, esegue una copia della riga e quindi esegue lo script sulla riga. Questo viene ripetuto su tutte le righe del file.
Il 'script' è nel formato '/pattern/ action' dove modello è un'espressione regolare e l'azione è ciò che farà awk quando trova il modello dato in una riga.
Come utilizzare lo strumento di filtraggio Awk in Linux
Nei seguenti esempi, ci concentreremo sui metacaratteri di cui abbiamo discusso sopra sotto le caratteristiche di awk.
Un semplice esempio di utilizzo di awk:
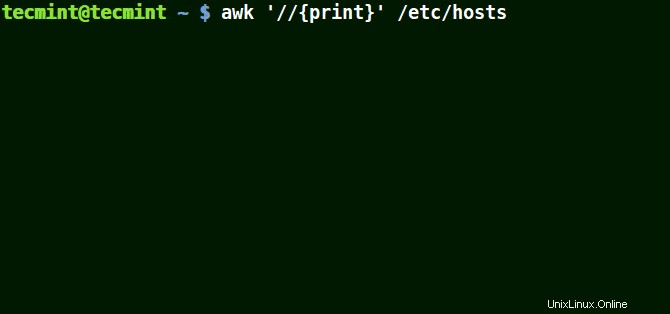
L'esempio seguente stampa tutte le righe nel file /etc/hosts poiché non viene fornito alcun modello.
# awk '//{print}'/etc/hosts

Usa Awk con Pattern:
Nell'esempio seguente, un pattern localhost è stato fornito, quindi awk corrisponderà alla riga con localhost nel /etc/hosts file.
# awk '/localhost/{print}' /etc/hosts

Utilizzare Awk con (.) jolly in un Pattern
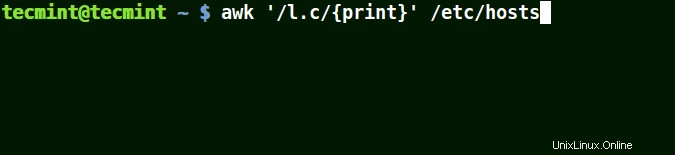
Il (.) corrisponderà a stringhe contenenti loc , host locale , rete locale nell'esempio seguente.
Vale a dire * l some_single_character c * .
# awk '/l.c/{print}' /etc/hosts
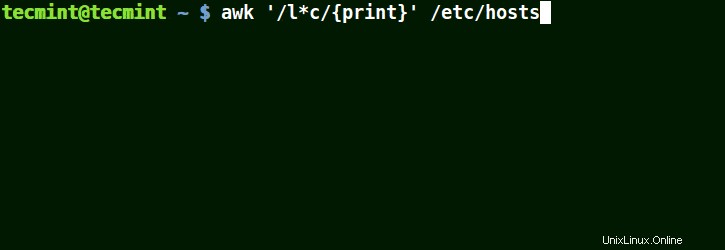
Utilizzo di Awk con (*) carattere in una sequenza
Corrisponderà alle stringhe contenenti localhost , rete locale , linee , capace , come nell'esempio seguente:
# awk '/l*c/{print}' /etc/localhost
Ti renderai anche conto che (*) cerca di ottenere la corrispondenza più lunga possibile che riesce a rilevare.
Diamo un'occhiata a un caso che lo dimostri, prendiamo l'espressione regolare t*t il che significa stringhe di corrispondenza che iniziano con la lettera t e termina con t nella riga sottostante:
this is tecmint, where you get the best good tutorials, how to's, guides, tecmint.
Avrai le seguenti possibilità quando usi il modello /t*t/ :
this is t this is tecmint this is tecmint, where you get t this is tecmint, where you get the best good t this is tecmint, where you get the best good tutorials, how t this is tecmint, where you get the best good tutorials, how tos, guides, t this is tecmint, where you get the best good tutorials, how tos, guides, tecmint
E (*) in /t*t/ il carattere jolly consente a awk di scegliere l'ultima opzione:
this is tecmint, where you get the best good tutorials, how to's, guides, tecmint
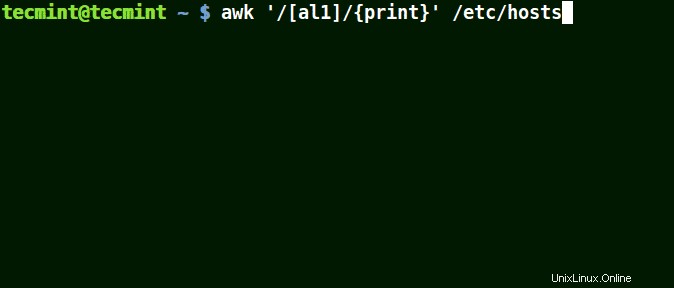
Utilizzo di Awk con set [caratteri]
Prendi ad esempio il set [al1] , qui awk corrisponderà a tutte le stringhe contenenti il carattere a o l o 1 in una riga nel file /etc/hosts .
# awk '/[al1]/{print}' /etc/hosts
L'esempio successivo corrisponde a stringhe che iniziano con K o k seguito da T :
# awk '/[Kk]T/{print}' /etc/hosts

Specificare i caratteri in un intervallo
Comprendi i caratteri con awk:
[0-9]indica un unico numero[a-z]significa abbinare una singola lettera minuscola[A-Z]significa abbinare una singola lettera maiuscola[a-zA-Z]significa abbinare una singola lettera[a-zA-Z 0-9]significa abbinare una singola lettera o numero
Diamo un'occhiata a un esempio qui sotto:
# awk '/[0-9]/{print}' /etc/hosts
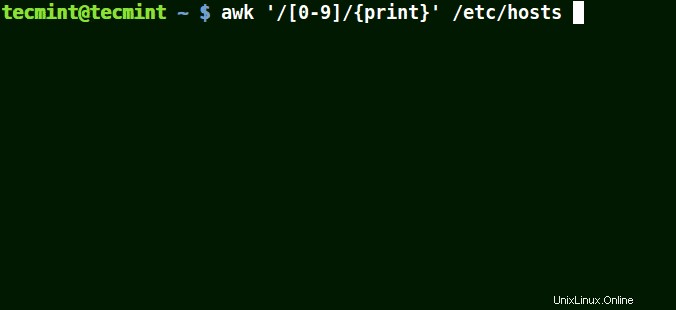
Tutta la riga dal file /etc/hosts contenere almeno un singolo numero [0-9] nell'esempio sopra.
Usa Awk con (^) Metacarattere
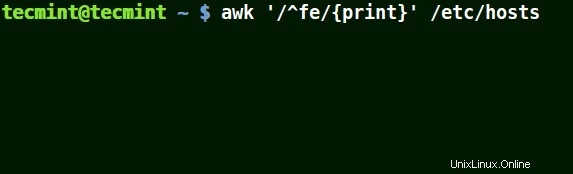
Corrisponde a tutte le righe che iniziano con il modello fornito come nell'esempio seguente:
# awk '/^fe/{print}' /etc/hosts
# awk '/^ff/{print}' /etc/hosts
Usa Awk con ($) Metacarattere
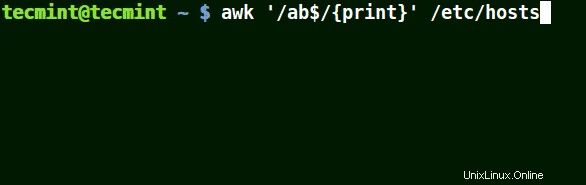
Corrisponde a tutte le linee che terminano con lo schema fornito:
# awk '/ab$/{print}' /etc/hosts
# awk '/ost$/{print}' /etc/hosts
# awk '/rs$/{print}' /etc/hosts
Usa Awk con (\) carattere Escape
Ti permette di prendere il personaggio che lo segue come un letterale, vale a dire consideralo così com'è.
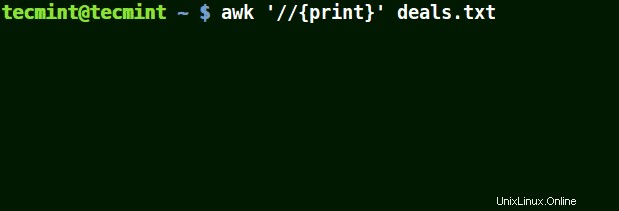
Nell'esempio seguente, il primo comando stampa tutta la riga nel file, il secondo comando non stampa nulla perché voglio abbinare una riga che ha $ 25,00 , ma non viene utilizzato alcun carattere di escape.
Il terzo comando è corretto poiché è stato utilizzato un carattere di escape per leggere $ così com'è.
# awk '//{print}' deals.txt
# awk '/$25.00/{print}' deals.txt
# awk '/\$25.00/{print}' deals.txt
Riepilogo
Non è tutto con awk strumento di filtraggio della riga di comando, gli esempi sopra e le operazioni di base di awk. Nelle prossime parti avanzeremo su come utilizzare le funzioni complesse di awk. Grazie per la lettura e per eventuali integrazioni o chiarimenti, posta un commento nella sezione commenti.