Un utente Linux esperto sa esattamente che tipo di fastidiose righe vuote possono essere in un file processabile. Queste righe vuote/vuote non solo intralciano la corretta elaborazione di tali file, ma rendono anche difficile la lettura e la scrittura del file da parte di un programma in esecuzione.
In un ambiente con sistema operativo Linux, è possibile implementare diverse espressioni di manipolazione del testo per eliminare queste righe vuote/vuote da un file. In questo articolo, le righe vuote/vuote si riferiscono agli spazi bianchi.
Crea un file con righe vuote/vuote in Linux
Dobbiamo creare un file di riferimento con alcune righe vuote/vuote. Lo modificheremo in seguito nell'articolo attraverso diverse tecniche di cui parleremo. Dal tuo terminale, crea un file di testo a tua scelta con un nome come "i_have_blanks ” e popolalo con alcuni dati e alcuni spazi vuoti.
$ nano i_have_blanks.txt Or $ vi i_have_blanks.txt
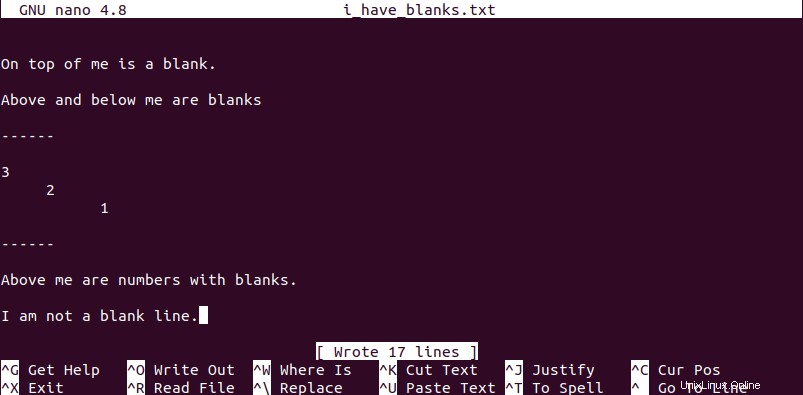
In tutto l'articolo, emetteremo il contenuto di un file sul nostro terminale usando il comando cat per un riferimento flessibile.
$ cat i_have_blanks.txt

I tre comandi Linux che ci spingeranno verso una soluzione ideale a questo problema di righe vuote/vuote sono grep, sed e awk .
Pertanto, crea tre copie del tuo i_have_blanks.txt file e salvali con nomi diversi in modo che ciascuno possa essere ospitato da uno dei tre comandi Linux indicati.
Attraverso regex (espressioni regolari ), possiamo identificare le righe vuote con il carattere standard POSIX “[:space:]” .
Come rimuovere le righe vuote/vuote nei file
Con questa affermazione del problema, stiamo considerando l'eliminazione di tutte le righe vuote/vuote esistenti da un dato file leggibile utilizzando i seguenti comandi.
1. Elimina le righe vuote usando il comando Grep
L'uso supportato delle classi di caratteri abbreviati può ridurre il comando grep a uno semplice come:
$ grep -v '^[[:space:]]*$' i_have_blanks.txt OR $ grep '\S' i_have_blanks.txt
Per correggere un file con righe vuote/vuote, l'output sopra deve passare attraverso un file temporaneo prima di sovrascrivere il file originale.
$ grep '\S' i_have_blanks.txt > tmp.txt $ mv tmp.txt i_have_blanks.txt $ cat i_have_blanks.txt

Come puoi vedere, tutte le righe vuote che distanziavano il contenuto di questo file di testo sono sparite.
2. Elimina le righe vuote usando il comando Sed
Il d action nel comando gli dice di eliminare qualsiasi spazio bianco esistente da un file. Il meccanismo di corrispondenza ed eliminazione delle righe vuote di questo comando può essere rappresentato nel modo seguente.
$ sed '/^[[:space:]]*$/d' i_have_blanks_too.txt
Il comando precedente esegue la scansione delle righe del file di testo per i caratteri non vuoti ed elimina tutti gli altri caratteri rimanenti. Attraverso il supporto della classe di caratteri non vuoti, il comando precedente può essere semplificato come segue:
$ sed '/\S/!d' i_have_blanks_too.txt
Inoltre, a causa del supporto di modifica sul posto del comando, non abbiamo bisogno di un file temporaneo per conservare temporaneamente il nostro file convertito prima di sovrascrivere il file di testo originale come nel caso del comando grep. Tuttavia, devi usare questo comando con un -i opzione come argomento.
$ sed -i '/\S/!d' i_have_blanks_too.txt i_have_blanks_too.txt $ cat i_have_blanks_too.txt
3. Elimina le righe vuote usando il comando Awk
Il comando awk esegue un controllo dei caratteri non bianchi su ogni riga di un file e li stampa solo se questa condizione è vera. La flessibilità di questo comando viene fornita con vari percorsi di implementazione. La sua soluzione semplice è la seguente:
$ awk '!/^[[:space:]]*$/' i_have_blanks_first.txt
L'interpretazione del comando precedente è semplice, vengono stampate solo le righe del file che non esistono come spazi bianchi. La versione più lunga del comando precedente sarà simile alla seguente:
$ awk '{ if($0 !~ /^[[:space:]]*$/) }' i_have_blanks_first.txt
Attraverso awk supporto della classe di caratteri non vuoti, il comando precedente può anche essere rappresentato nel modo seguente:
$ awk -d '/\S/' i_have_blanks_first.txt
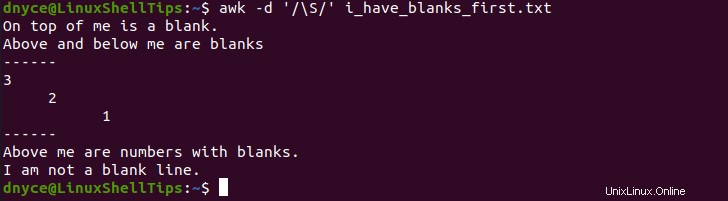
Il -d un'opzione consente di awk scaricare le righe di file finali sul terminale di sistema. Come puoi vedere, il file non ha più spazi bianchi.
Le tre soluzioni discusse e implementate per gestire le righe vuote dai file tramite grep , sed e ahk i comandi ci impiegheranno molto nell'implementazione di operazioni di lettura e scrittura di file stabili ed efficienti su un sistema Linux.