Lavoro part-time come data auditor. Pensa a me come a un correttore di bozze che lavora con tabelle di dati piuttosto che con pagine di prosa. Le tabelle vengono esportate da database relazionali e sono generalmente di dimensioni piuttosto modeste:da 100.000 a 1.000.000 di record e da 50 a 200 campi.
Non ho mai visto una tabella di dati priva di errori, mai. Il disordine non si limita, come si potrebbe pensare, alla duplicazione di record, errori di ortografia e formattazione e elementi di dati inseriti nel campo sbagliato. Trovo anche:
- record interrotti distribuiti su più righe perché gli elementi di dati avevano interruzioni di riga incorporate
- Elementi di dati in un campo in disaccordo con gli elementi di dati in un altro campo, nello stesso record
- record con elementi di dati troncati, spesso perché stringhe molto lunghe venivano inserite in campi con limiti di 50 o 100 caratteri
- Errori di codifica dei caratteri che producono il linguaggio senza senso noto come mojibake
- caratteri di controllo invisibili, alcuni dei quali possono causare errori di elaborazione dei dati
- caratteri sostitutivi e misteriosi punti interrogativi inseriti dall'ultimo programma che non è riuscito a capire la codifica dei caratteri dei dati
Ripulire questi problemi non è difficile, ma ci sono ostacoli non tecnici per trovarli. Il primo è la naturale riluttanza di tutti a gestire gli errori di dati. Prima di vedere una tabella, i proprietari o i gestori dei dati potrebbero aver attraversato tutte e cinque le fasi di Data Grief:
- Non ci sono errori nei nostri dati.
- Beh, forse ci sono alcuni errori, ma non sono così importanti.
- OK, ci sono molti errori; faremo in modo che il nostro personale interno si occupi di loro.
- Abbiamo iniziato a correggere alcuni errori, ma è dispendioso in termini di tempo; lo faremo quando migreremo al nuovo software di database.
- Non abbiamo avuto il tempo di pulire i dati durante il passaggio al nuovo database; potremmo aver bisogno di aiuto.
Il secondo atteggiamento di blocco del progresso è la convinzione che la pulizia dei dati richieda applicazioni dedicate, o programmi proprietari costosi o l'eccellente programma open source OpenRefine. Per affrontare problemi che le applicazioni dedicate non possono risolvere, i data manager potrebbero chiedere aiuto a un programmatore, qualcuno che sia bravo con Python o R.
Ma il controllo e la pulizia dei dati in genere non richiedono applicazioni dedicate. Le tabelle di dati in testo normale esistono da molti decenni, così come gli strumenti di elaborazione del testo. Apri una shell Bash e avrai una cassetta degli attrezzi caricata con potenti processori di testo come grep , cut , paste , sort , uniq , tr e awk . Sono veloci, affidabili e facili da usare.
Eseguo tutto il controllo dei dati sulla riga di comando e ho inserito molti dei miei trucchi di controllo dei dati su un sito Web "ricettario". Le operazioni che eseguo regolarmente vengono archiviate come funzioni e script di shell (vedere l'esempio seguente).
Sì, un approccio da riga di comando richiede che i dati da controllare siano stati esportati dal database. E sì, i risultati dell'audit devono essere modificati successivamente all'interno del database o (database permettendo) è necessario importare gli elementi di dati puliti in sostituzione di quelli disordinati.
Ma i vantaggi sono notevoli. awk elaborerà alcuni milioni di record in pochi secondi su un desktop o laptop di livello consumer. Le semplici espressioni regolari troveranno tutti gli errori di dati che puoi immaginare. E tutto questo avverrà in sicurezza fuori la struttura del database:il controllo della riga di comando non può influire sul database, perché funziona con i dati liberati dalla sua prigione del database.
I lettori che si sono formati su Unix sorrideranno compiaciuti a questo punto. Ricordano di aver manipolato i dati sulla riga di comando molti anni fa proprio in questi modi. Quello che è successo da allora è che la potenza di elaborazione e la RAM sono aumentate in modo spettacolare e gli strumenti standard da riga di comando sono stati resi sostanzialmente più efficienti. Il controllo dei dati non è mai stato così veloce o facile. E ora che Microsoft Windows 10 può eseguire programmi Bash e GNU/Linux, gli utenti Windows possono apprezzare il motto Unix e Linux per gestire i dati disordinati:mantieni la calma e apri un terminale.

Un esempio
Supponiamo di voler trovare l'elemento di dati più lungo in un campo particolare di una grande tabella. Non è davvero un'attività di controllo dei dati, ma mostrerà come funzionano gli strumenti della shell. A scopo dimostrativo, utilizzerò la tabella separata da tabulazioni full0 , che ha 1.122.023 record (più una riga di intestazione) e 49 campi, e cercherò nel campo numero 36. (Ricevo i numeri dei campi con una funzione spiegata sul mio sito di libri di cucina.)
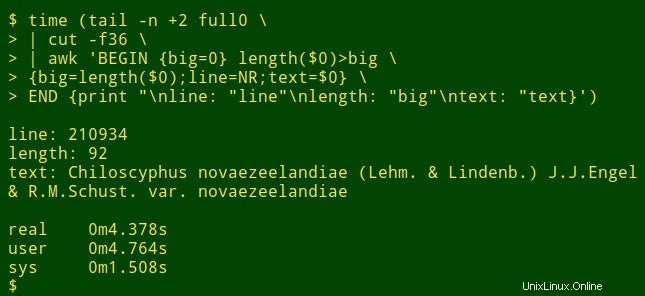
Il comando inizia usando tail per rimuovere la riga di intestazione da full0 . Il risultato viene inviato a cut , che estrae il campo decapitato 36. Il prossimo nella pipeline è awk . Qui la variabile big viene inizializzato al valore 0; quindi awk verifica la lunghezza dell'elemento di dati nel primo record. Se la lunghezza è maggiore di 0, awk reimposta big alla nuova lunghezza e memorizza il numero di riga (NR) nella variabile line e l'intero elemento di dati nella variabile text . awk quindi elabora ciascuno dei restanti 1.122.022 record a turno, reimpostando le tre variabili quando trova un elemento di dati più lungo. Infine, stampa un elenco ben separato di numeri di riga, lunghezza dell'elemento dati e testo completo dell'elemento dati più lungo. (Nel codice seguente, i comandi sono stati suddivisi per chiarezza su più righe.)
<code>tail -n +2 full0 \
> | cut -f36 \
> | awk 'BEGIN {big=0} length($0)>big \
> {big=length($0);line=NR;text=$0} \
> END {print "\nline: "line"\nlength: "big"\ntext: "text}' </code>
Quanto tempo ci vuole? Circa 4 secondi sul mio desktop (core i5, 8 GB di RAM):
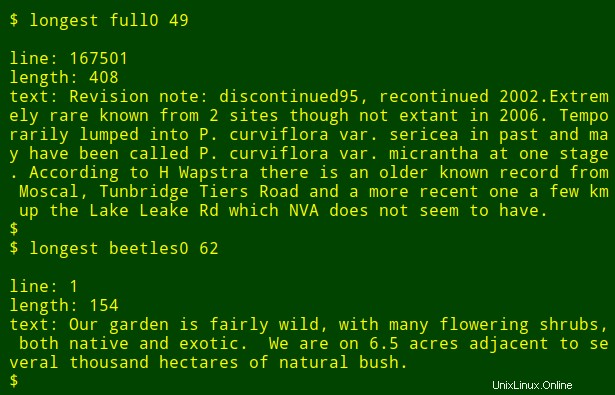
Ora per la parte più ordinata:posso inserire quel lungo comando in una funzione della shell, longest , che prende come argomenti il nome del file ($1) e il numero del campo ($2) :

Posso quindi eseguire nuovamente il comando come una funzione, trovando gli elementi di dati più lunghi in altri campi e in altri file senza dover ricordare come è scritto il comando:
Come ultima modifica, posso aggiungere all'output il nome del campo numerato che sto cercando. Per fare ciò, utilizzo head per estrarre la riga di intestazione della tabella, reindirizza quella riga a tr per convertire le tabulazioni in nuove righe e reindirizzare l'elenco risultante a tail e head per stampare il $2th nome del campo nell'elenco, dove $2 è l'argomento del numero di campo. Il nome del campo è memorizzato nella variabile shell field e passato a awk per la stampa come awk interno variabile fld .
<code>longest() { field=$(head -n 1 "$1" | tr '\t' '\n' | tail -n +"$2" | head -n 1); \
tail -n +2 "$1" \
| cut -f"$2" | \
awk -v fld="$field" 'BEGIN {big=0} length($0)>big \
{big=length($0);line=NR;text=$0}
END {print "\nfield: "fld"\nline: "line"\nlength: "big"\ntext: "text}'; }</code> 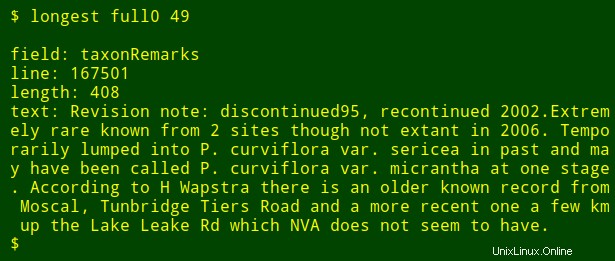
Nota che se sto cercando l'elemento di dati più lungo in un numero di campi diversi, tutto ciò che devo fare è premere il tasto Freccia su per ottenere l'ultimo longest comando, quindi tornare indietro con il numero del campo e inserirne uno nuovo.