Nel nostro uso quotidiano dei sistemi Linux/Unix, utilizziamo molti strumenti da riga di comando per completare il nostro lavoro e per comprendere e gestire i nostri sistemi, strumenti come du per monitorare l'utilizzo del disco e top per mostrare le risorse di sistema. Alcuni di questi strumenti esistono da molto tempo. Ad esempio, top è stato rilasciato per la prima volta nel 1984, mentre du la prima uscita di 's risale al 1971.
Nel corso degli anni, questi strumenti sono stati modernizzati e portati su sistemi diversi, ma, in generale, seguono ancora l'idea, l'aspetto e la sensazione originali.
Questi sono ottimi strumenti ed essenziali per i flussi di lavoro di molti amministratori di sistema. Tuttavia, negli ultimi anni, la comunità open source ha sviluppato strumenti alternativi che offrono vantaggi aggiuntivi. Alcuni sono solo un piacere per gli occhi, ma altri migliorano notevolmente l'usabilità, rendendoli un'ottima scelta da utilizzare sui sistemi moderni. Questi includono le seguenti cinque alternative agli strumenti a riga di comando standard di Linux.
1. ncdu in sostituzione di du
L'utilizzo del disco di NCurses (ncdu ) fornisce risultati simili a du ma in un'interfaccia interattiva basata su curses che si concentra sulle directory che consumano la maggior parte dello spazio su disco.
ncdu dedica un po' di tempo all'analisi del disco, quindi visualizza i risultati ordinati in base alle directory o ai file più utilizzati, in questo modo:
ncdu 1.14.2 ~ Use the arrow keys to navigate, press ? for help
--- /home/rgerardi ------------------------------------------------------------
96.7 GiB [##########] /libvirt
33.9 GiB [### ] /.crc
7.0 GiB [ ] /Projects
. 4.7 GiB [ ] /Downloads
. 3.9 GiB [ ] /.local
2.5 GiB [ ] /.minishift
2.4 GiB [ ] /.vagrant.d
. 1.9 GiB [ ] /.config
. 1.8 GiB [ ] /.cache
1.7 GiB [ ] /Videos
1.1 GiB [ ] /go
692.6 MiB [ ] /Documents
. 591.5 MiB [ ] /tmp
139.2 MiB [ ] /.var
104.4 MiB [ ] /.oh-my-zsh
82.0 MiB [ ] /scripts
55.8 MiB [ ] /.mozilla
54.6 MiB [ ] /.kube
41.8 MiB [ ] /.vim
31.5 MiB [ ] /.ansible
31.3 MiB [ ] /.gem
26.5 MiB [ ] /.VIM_UNDO_FILES
15.3 MiB [ ] /Personal
2.6 MiB [ ] .ansible_module_generated
1.4 MiB [ ] /backgrounds
944.0 KiB [ ] /Pictures
644.0 KiB [ ] .zsh_history
536.0 KiB [ ] /.ansible_async
Total disk usage: 159.4 GiB Apparent size: 280.8 GiB Items: 561540
Passare a ciascuna voce utilizzando i tasti freccia. Se premi Invio su una voce della rubrica, ncdu visualizza il contenuto di quella directory:
--- /home/rgerardi/libvirt ----------------------------------------------------
/..
91.3 GiB [##########] /images
5.3 GiB [ ] /media
Puoi usarlo per approfondire le directory e trovare quali file stanno consumando più spazio su disco. Torna alla directory precedente utilizzando sinistra tasto freccia. Per impostazione predefinita, puoi eliminare i file con ncdu premendo la d chiave e chiede conferma prima di eliminare un file. Se vuoi disabilitare questo comportamento per evitare incidenti, usa il -r opzione per l'accesso in sola lettura:ncdu -r .
ncdu è disponibile per molte piattaforme e distribuzioni Linux. Ad esempio, puoi utilizzare dnf per installarlo su Fedora direttamente dai repository ufficiali:
$ sudo dnf install ncdu
Puoi trovare maggiori informazioni su questo strumento su ncdu pagina web.
2. htop in sostituzione di top
htop è un visualizzatore di processi interattivo simile a top ma ciò fornisce un'esperienza utente più piacevole fuori dagli schemi. Per impostazione predefinita, htop mostra le stesse metriche di top in un display piacevole e colorato.
Per impostazione predefinita, htop assomiglia a questo:
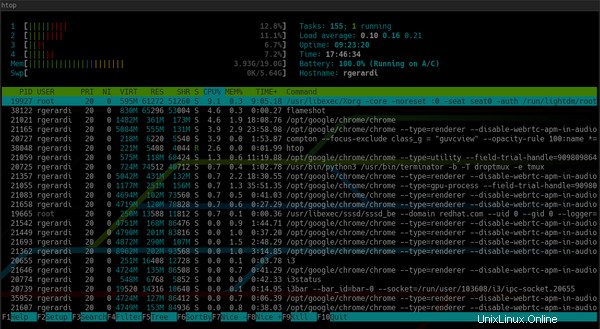
In contrasto con l'impostazione predefinita top :
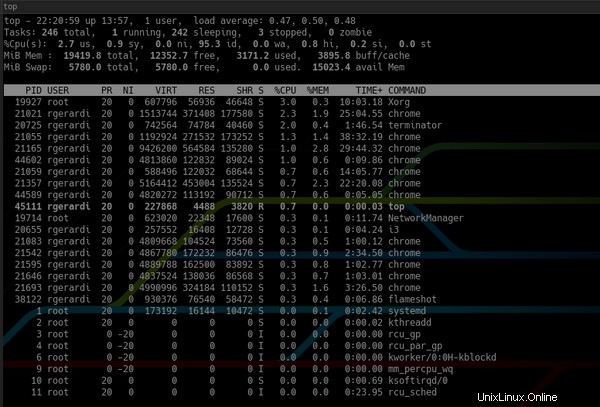
Inoltre, htop fornisce informazioni sulla panoramica del sistema in alto e una barra dei comandi in basso per attivare i comandi utilizzando i tasti funzione e puoi personalizzarlo premendo F2 per accedere alla schermata di configurazione. Durante la configurazione, puoi cambiarne i colori, aggiungere o rimuovere metriche o modificare le opzioni di visualizzazione per la barra di panoramica.
Più risorse Linux
- Comandi Linux cheat sheet
- Cheat sheet sui comandi avanzati di Linux
- Corso online gratuito:Panoramica tecnica RHEL
- Cheat sheet della rete Linux
- Cheat sheet di SELinux
- Cheat sheet dei comandi comuni di Linux
- Cosa sono i container Linux?
- I nostri ultimi articoli su Linux
Mentre puoi configurare le versioni recenti di top per ottenere risultati simili, htop fornisce configurazioni predefinite più sane, il che lo rende un visualizzatore di processi piacevole e facile da usare.
Per saperne di più su questo progetto, controlla htop pagina iniziale.
3. tldr in sostituzione di man
Il tldr lo strumento da riga di comando visualizza informazioni semplificate sull'utilizzo dei comandi, inclusi principalmente esempi. Funziona come client per il progetto delle pagine tldr della comunità.
Questo strumento non sostituisce man . Le pagine man sono ancora la fonte canonica e completa di informazioni per molti strumenti. Tuttavia, in alcuni casi, man è troppo. A volte non hai bisogno di tutte quelle informazioni su un comando; stai solo cercando di ricordare le opzioni di base. Ad esempio, la pagina man per curl comando ha quasi 3.000 righe. Al contrario, il tldr per curl è lungo 40 righe e si presenta così:
$ tldr curl
# curl
Transfers data from or to a server.
Supports most protocols, including HTTP, FTP, and POP3.
More information: <https://curl.haxx.se>.
- Download the contents of an URL to a file:
curl http://example.com -o filename
- Download a file, saving the output under the filename indicated by the URL:
curl -O http://example.com/filename
- Download a file, following [L]ocation redirects, and automatically [C]ontinuing (resuming) a previous file transfer:
curl -O -L -C - http://example.com/filename
- Send form-encoded data (POST request of type `application/x-www-form-urlencoded`):
curl -d 'name=bob' http://example.com/form
- Send a request with an extra header, using a custom HTTP method:
curl -H 'X-My-Header: 123' -X PUT http://example.com
- Send data in JSON format, specifying the appropriate content-type header:
curl -d '{"name":"bob"}' -H 'Content-Type: application/json' http://example.com/users/1234
... TRUNCATED OUTPUT
TLDR sta per "troppo lungo; non letto", che è il gergo di Internet per un riassunto di testo lungo. Il nome è appropriato per questo strumento perché le pagine man, sebbene utili, a volte sono semplicemente troppo lunghe.
In Fedora, il tldr client è stato scritto in Python. Puoi installarlo usando dnf . Per altre opzioni client, consulta il progetto tldr pages.
In generale, il tldr strumento richiede l'accesso a Internet per consultare le pagine tldr. Il client Python in Fedora ti consente di scaricare e memorizzare nella cache queste pagine per l'accesso offline.
Per ulteriori informazioni su tldr , puoi usare tldr tldr .
4. jq in sostituzione di sed/grep per JSON
jq è un processore JSON da riga di comando. È come sed o grep ma specificamente progettato per gestire i dati JSON. Se sei uno sviluppatore o un amministratore di sistema che utilizza JSON nelle tue attività quotidiane, questo è uno strumento essenziale nella tua cassetta degli attrezzi.
Il principale vantaggio di jq su strumenti generici di elaborazione del testo come grep e sed è che comprende la struttura dei dati JSON, consentendoti di creare query complesse con un'unica espressione.
Per illustrare, immagina di cercare il nome dei contenitori in questo file JSON:
{
"apiVersion": "v1",
"kind": "Pod",
"metadata": {
"labels": {
"app": "myapp"
},
"name": "myapp",
"namespace": "project1"
},
"spec": {
"containers": [
{
"command": [
"sleep",
"3000"
],
"image": "busybox",
"imagePullPolicy": "IfNotPresent",
"name": "busybox"
},
{
"name": "nginx",
"image": "nginx",
"resources": {},
"imagePullPolicy": "IfNotPresent"
}
],
"restartPolicy": "Never"
}
}
Se provi a grep direttamente per name , questo è il risultato:
$ grep name k8s-pod.json
"name": "myapp",
"namespace": "project1"
"name": "busybox"
"name": "nginx",
grep ha restituito tutte le righe che contengono la parola name . Puoi aggiungere qualche altra opzione a grep per restringerlo e, con qualche manipolazione di espressioni regolari, puoi trovare i nomi dei contenitori. Per ottenere il risultato che desideri con jq , usa un'espressione che simula la navigazione nella struttura dei dati, come questa:
$ jq '.spec.containers[].name' k8s-pod.json
"busybox"
"nginx"
Questo comando ti dà il nome di entrambi i contenitori. Se stai cercando solo il nome del secondo contenitore, aggiungi l'indice dell'elemento dell'array all'espressione:
$ jq '.spec.containers[1].name' k8s-pod.json
"nginx"
Perché jq è a conoscenza della struttura dei dati, fornisce gli stessi risultati anche se il formato del file cambia leggermente. grep e sed può fornire risultati diversi con piccole modifiche al formato.
jq ha molte caratteristiche e coprirle tutte richiederebbe un altro articolo. Per ulteriori informazioni, consultare il jq pagina del progetto, le pagine man o tldr jq .
5. fd in sostituzione di find
fd è un'alternativa semplice e veloce al find comando. Non mira a sostituire la funzionalità completa find fornisce; invece, fornisce alcune impostazioni predefinite sane che aiutano molto in determinati scenari.
Ad esempio, durante la ricerca di file di codice sorgente in una directory che contiene un repository Git, fd esclude automaticamente i file e le directory nascosti, incluso il .git directory, oltre a ignorare i modelli da .gitignore file. In generale, fornisce ricerche più veloci con risultati più pertinenti al primo tentativo.
Per impostazione predefinita, fd esegue una ricerca del modello senza distinzione tra maiuscole e minuscole nella directory corrente con output colorato. La stessa ricerca usando find richiede di fornire parametri aggiuntivi della riga di comando. Ad esempio, per cercare tutti i file markdown (.md o .MD ) nella directory corrente, il find il comando è questo:
$ find . -iname "*.md"
Ecco la stessa ricerca con fd :
$ fd .md
In alcuni casi, fd richiede opzioni aggiuntive; per esempio, se vuoi includere file e directory nascosti, devi usare l'opzione -H , mentre questo non è richiesto in find .
fd è disponibile per molte distribuzioni Linux. Installalo in Fedora usando i repository standard:
$ sudo dnf install fd-find
Per ulteriori informazioni, consultare il fd Archivio GitHub.
Grandi alternative insieme a utility comprovate
Anche se utilizzo regolarmente tutti i vecchi strumenti essenziali, specialmente quando mi connetto in remoto ai server, gli strumenti alternativi offrono alcuni vantaggi aggiuntivi che sono preziosi in molti scenari. Mi aiutano in particolare a gestire e lavorare sui miei computer desktop e laptop Linux.
Utilizzi altri strumenti che aiutano il tuo flusso di lavoro? Aggiungili nella sezione commenti qui sotto.