Voglio trovare i miei articoli all'interno del forum di letteratura deprecato (obsoleto) e-bane.net. Alcuni dei moduli del forum sono disabilitati e non riesco a ottenere un elenco di articoli dal loro autore. Inoltre il sito non è indicizzato dai motori di ricerca come Google, Yndex, ecc.
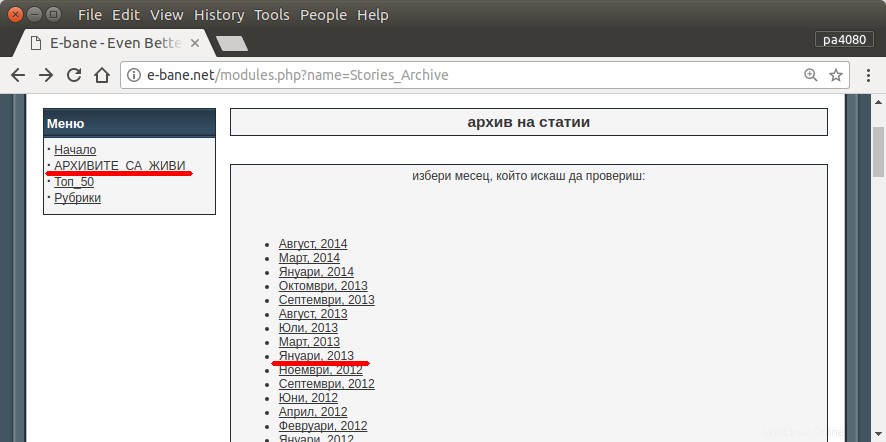
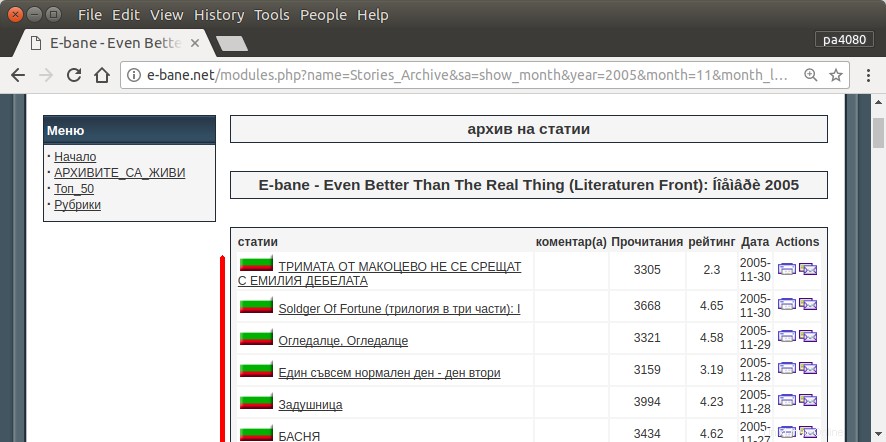
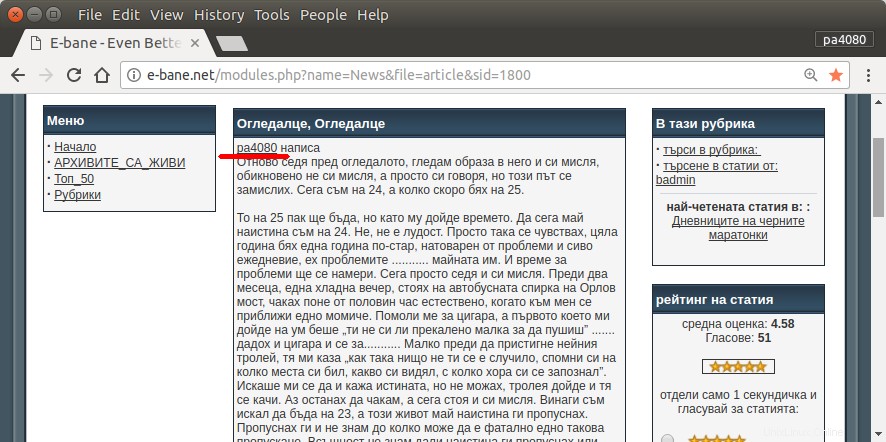
L'unico modo per trovare tutti i miei articoli è aprire la pagina archivio del sito (fig.1). Quindi devo selezionare un determinato anno e mese, ad es. Gennaio 2013 (fig.1). E poi devo controllare ogni articolo (fig.2) se all'inizio c'è scritto il mio nickname – pa4080 (fig.3). Ma ci sono poche migliaia di articoli.
Ho letto alcuni argomenti come segue, ma nessuna delle soluzioni si adatta alle mie esigenze:
- Ragno web per Ubuntu
- Come scrivere uno spider Web su un sistema Linux
- Ottieni un elenco di URL da un sito
Pubblicherò la mia soluzione. Ma per me è interessante:
C'è un modo più elegante per risolvere questo compito?
Risposta accettata:
script.py :
#!/usr/bin/python3
from urllib.parse import urljoin
import json
import bs4
import click
import aiohttp
import asyncio
import async_timeout
BASE_URL = 'http://e-bane.net'
async def fetch(session, url):
try:
with async_timeout.timeout(20):
async with session.get(url) as response:
return await response.text()
except asyncio.TimeoutError as e:
print('[{}]{}'.format('timeout error', url))
with async_timeout.timeout(20):
async with session.get(url) as response:
return await response.text()
async def get_result(user):
target_url = 'http://e-bane.net/modules.php?name=Stories_Archive'
res = []
async with aiohttp.ClientSession() as session:
html = await fetch(session, target_url)
html_soup = bs4.BeautifulSoup(html, 'html.parser')
date_module_links = parse_date_module_links(html_soup)
for dm_link in date_module_links:
html = await fetch(session, dm_link)
html_soup = bs4.BeautifulSoup(html, 'html.parser')
thread_links = parse_thread_links(html_soup)
print('[{}]{}'.format(len(thread_links), dm_link))
for t_link in thread_links:
thread_html = await fetch(session, t_link)
t_html_soup = bs4.BeautifulSoup(thread_html, 'html.parser')
if is_article_match(t_html_soup, user):
print('[v]{}'.format(t_link))
# to get main article, uncomment below code
# res.append(get_main_article(t_html_soup))
# code below is used to get thread link
res.append(t_link)
else:
print('[x]{}'.format(t_link))
return res
def parse_date_module_links(page):
a_tags = page.select('ul li a')
hrefs = a_tags = [x.get('href') for x in a_tags]
return [urljoin(BASE_URL, x) for x in hrefs]
def parse_thread_links(page):
a_tags = page.select('table table tr td > a')
hrefs = a_tags = [x.get('href') for x in a_tags]
# filter href with 'file=article'
valid_hrefs = [x for x in hrefs if 'file=article' in x]
return [urljoin(BASE_URL, x) for x in valid_hrefs]
def is_article_match(page, user):
main_article = get_main_article(page)
return main_article.text.startswith(user)
def get_main_article(page):
td_tags = page.select('table table td.row1')
td_tag = td_tags[4]
return td_tag
@click.command()
@click.argument('user')
@click.option('--output-filename', default='out.json', help='Output filename.')
def main(user, output_filename):
loop = asyncio.get_event_loop()
res = loop.run_until_complete(get_result(user))
# if you want to return main article, convert html soup into text
# text_res = [x.text for x in res]
# else just put res on text_res
text_res = res
with open(output_filename, 'w') as f:
json.dump(text_res, f)
if __name__ == '__main__':
main()
requirement.txt :
aiohttp>=2.3.7
beautifulsoup4>=4.6.0
click>=6.7
Ecco la versione python3 dello script (testato su python3.5 su Ubuntu 17.10 ).
Come usare:
- Per usarlo, inserisci entrambi i codici nei file. Ad esempio il file di codice è
script.pye il file del pacchetto èrequirement.txt. - Esegui
pip install -r requirement.txt. - Esegui lo script come esempio
python3 script.py pa4080
Utilizza diverse librerie:
- fai clic per il parser degli argomenti
- bella zuppa per parser html
- aiohttp per downloader html
Cose da sapere per sviluppare ulteriormente il programma (diverso dal documento del pacchetto richiesto):
- Libreria Python:asyncio, json e urllib.parse
- selettori CSS (mdn web docs), anche alcuni html. vedi anche come usare il selettore CSS sul tuo browser come questo articolo
Come funziona:
- Per prima cosa creo un semplice downloader html. È una versione modificata dell'esempio fornito su aiohttp doc.
- Dopo aver creato un semplice parser da riga di comando che accetta nome utente e nome file di output.
- Crea un parser per i collegamenti ai thread e l'articolo principale. L'uso di pdb e la semplice manipolazione dell'URL dovrebbe fare il lavoro.
- Combina la funzione e metti l'articolo principale su json, in modo che un altro programma possa elaborarlo in seguito.
Qualche idea per svilupparla ulteriormente
- Crea un altro sottocomando che accetti il collegamento del modulo data:può essere fatto separando il metodo per analizzare il modulo data alla sua funzione e combinarlo con il nuovo sottocomando.
- Memorizza nella cache il collegamento del modulo della data:crea il file json della cache dopo aver ottenuto il collegamento ai thread. quindi il programma non deve analizzare nuovamente il collegamento. o anche solo memorizzare nella cache l'intero articolo principale del thread anche se non corrisponde
Questa non è la risposta più elegante, ma penso che sia meglio che usare la risposta bash.
- Utilizza Python, il che significa che può essere utilizzato su più piattaforme.
- Installazione semplice, tutti i pacchetti richiesti possono essere installati utilizzando pip
- Può essere ulteriormente sviluppato, più leggibile il programma, più facile può essere sviluppato.
- Fa lo stesso lavoro dello script bash solo per 13 minuti .