Hai bisogno di una piattaforma di streaming per gestire grandi quantità di dati? Hai sicuramente sentito parlare di Apache Kafka su Linux. Apache Kafka è perfetto per l'elaborazione dei dati in tempo reale e sta diventando sempre più popolare. Installare Apache Kafka su Linux può essere un po' complicato, ma non preoccuparti, questo tutorial ti copre.
In questo tutorial imparerai a installare e configurare Apache Kafka, così potrai iniziare a elaborare i tuoi dati come un professionista, rendendo la tua azienda più efficiente e produttiva.
Continua a leggere e inizia subito lo streaming di dati con Apache Kafka!
Prerequisiti
Questo tutorial sarà una dimostrazione pratica. Se desideri seguire, assicurati di avere quanto segue.
- Una macchina Linux:questa demo utilizza Debian 10, ma qualsiasi distribuzione Linux funzionerà.
- Un account utente non root con privilegi sudo, necessario per eseguire Kafka, e denominato
kafkain questo tutorial. - Un utente sudo dedicato per Kafka:questo tutorial utilizza un utente sudo chiamato kafka.
- Java:Java è una parte integrante dell'installazione di Apache Kafka.
- Git:questo tutorial utilizza Git per scaricare i file Apache Kafka Unit.
Installazione di Apache Kafka
Prima di eseguire lo streaming dei dati, devi prima installare Apache Kafka sul tuo computer. Dato che hai un account dedicato per Kafka, puoi installare Kafka senza preoccuparti di rompere il tuo sistema.
1. Esegui mkdir comando seguente per creare /home/kafka/Downloads directory. Puoi nominare la directory come preferisci, ma la directory si chiama Download per questa demo. Questa directory memorizzerà i binari di Kafka. Questa azione garantisce che tutti i tuoi file per Kafka siano disponibili per kafka utente.
mkdir Downloads
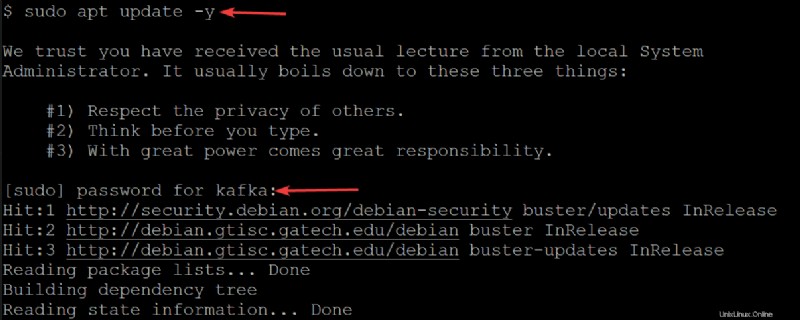
2. Quindi, esegui il seguente apt update comando per aggiornare l'indice del pacchetto del tuo sistema.
sudo apt update -yInserisci la password per il tuo utente kafka quando richiesto.
3. Esegui curl comando seguente per scaricare i binari di Kafka dal sito Web di Apache Foundation per l'output (-o ) in un file binario (kafka.tgz ) nel tuo ~/Downloads directory. Utilizzerai questo file binario per installare Kafka.
Assicurati di sostituire kafka/3.1.0/kafka_2.13-3.1.0.tgz con l'ultima versione dei binari Kafka. Al momento della stesura di questo articolo, l'attuale versione di Kafka è la 3.1.0.
curl "https://dlcdn.apache.org/kafka/3.1.0/kafka_2.13-3.1.0.tgz" -o ~/Downloads/kafka.tgz
4. Ora esegui tar comando seguente per estrarre (-x ) i binari di Kafka (~/Downloads/kafka.tgz ) nel kafka creato automaticamente directory. Le opzioni nel tar comando eseguire quanto segue:
Le opzioni nel tar comando eseguire quanto segue:
-v– Dice altarcomando per elencare tutti i file man mano che vengono estratti.
-z– Dice altarcomando per gzip l'archivio mentre viene decompresso. Questo comportamento non è richiesto in questo caso, ma è un'opzione eccellente, soprattutto se hai bisogno di un file compresso/zippato veloce per spostarti.
-f– Dice altarcomando quale file di archivio estrarre.
-strip 1-Istruisce iltarcomando per rimuovere il primo livello di directory dall'elenco dei nomi dei file. Di conseguenza, crea automaticamente una sottodirectory denominata kafka contenente tutti i file estratti dal~/Downloads/kafka.tgzfile.
tar -xvzf ~/Downloads/kafka.tgz --strip 1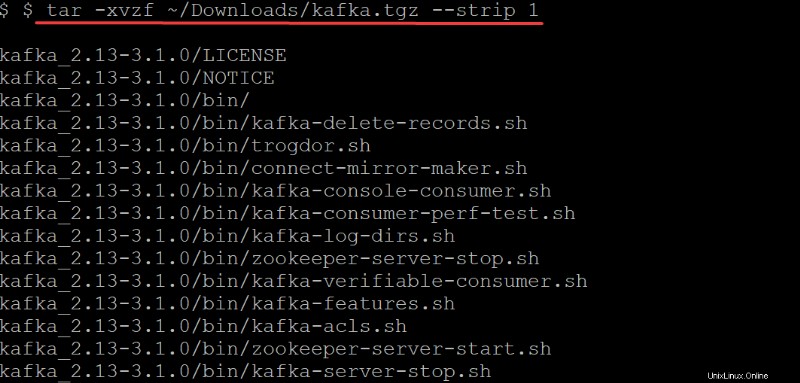
Configurazione del server Apache Kafka
A questo punto, hai scaricato e installato i binari di Kafka sul tuo ~/Downloads directory. Non puoi ancora utilizzare il server Kafka poiché, per impostazione predefinita, Kafka non ti consente di eliminare o modificare alcun argomento, una categoria necessaria per organizzare i messaggi di registro.
Per configurare il tuo server Kafka, dovrai modificare il file di configurazione di Kafka (/etc/kafka/server.properties).
1. Apri il file di configurazione di Kafka (/etc/kafka/server.properties ) nel tuo editor di testo preferito.
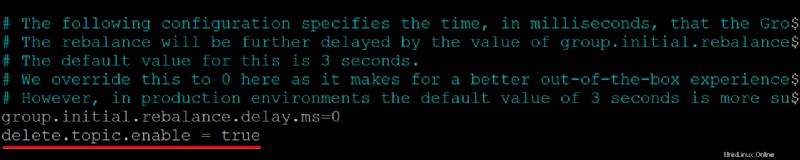
2. Successivamente, aggiungi delete.topic.enable =true riga in fondo a /kafka/config/server.properties contenuto del file, salvare le modifiche e chiudere l'editor.
Questa proprietà di configurazione ti dà il permesso di eliminare o modificare gli argomenti, quindi assicurati di sapere cosa stai facendo prima di eliminare gli argomenti. L'eliminazione di un argomento elimina anche le partizioni per quell'argomento. Tutti i dati archiviati in quelle partizioni non sono più accessibili una volta che sono spariti.
Assicurati che non ci siano spazi all'inizio di ogni riga, altrimenti il file non verrà riconosciuto e il tuo server Kafka non funzionerà.
3. Esegui git comando di seguito a clone il ata-kafka project sul computer locale in modo da poterlo modificare per utilizzarlo come file di unità per il servizio Kafka.
sudo git clone https://github.com/Adam-the-Automator/apache-kafka.git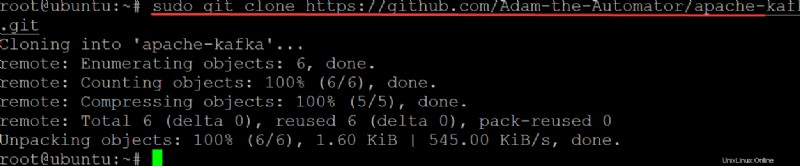
Ora, esegui i comandi seguenti per spostarti nel apache-kafka directory ed elenca i file all'interno.
cd apache-kafka
lsOra che sei in ata-kafka directory, puoi vedere che hai due file all'interno:kafka.service e zookeeper.service, come mostrato di seguito.

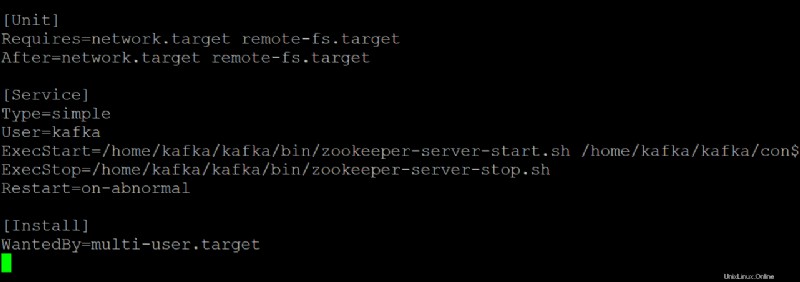
5. Apri zookeeper.service file nel tuo editor di testo preferito. Utilizzerai questo file come riferimento per creare il kafka.service file.
Personalizza ogni sezione di seguito in zookeeper.service file, se necessario. Ma questa demo usa questo file così com'è, senza modifiche.
- Il
[Unit]la sezione configura le proprietà di avvio per questa unità. Questa sezione dice al systemd cosa usare quando si avvia il servizio zookeeper.
- La sezione [Servizio] definisce come, quando e dove avviare il servizio Kafka utilizzando kafka-server-start.sh sceneggiatura. Questa sezione definisce anche le informazioni di base come nome, descrizione e argomenti della riga di comando (ciò che segue ExecStart=).
- Il
[Install]sezione imposta il runlevel per avviare il servizio quando si accede alla modalità multiutente.
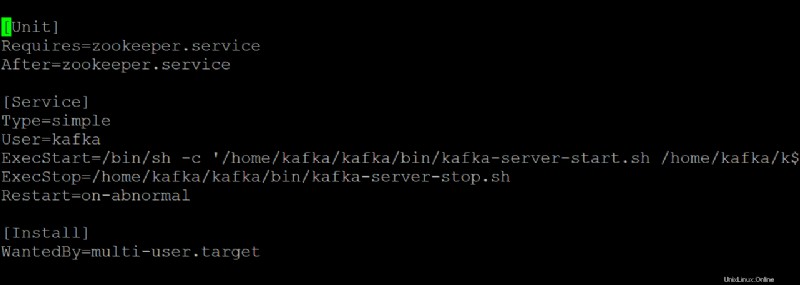
6. Apri kafka.service file nel tuo editor di testo preferito e configura l'aspetto del tuo server Kafka durante l'esecuzione come servizio systemd.
Questa demo utilizza i valori predefiniti presenti in kafka.service file, ma puoi personalizzare il file secondo necessità. Nota che questo file si riferisce a zookeeper.service file, che potresti modificare a un certo punto.
7. Esegui il comando seguente su start il kafka servizio.
sudo systemctl start kafkaRicordati di interrompere e avviare il tuo server Kafka come servizio. In caso contrario, il processo rimarrà in memoria e puoi interromperlo solo uccidendolo. Questo comportamento può portare alla perdita di dati se hai argomenti che vengono scritti o aggiornati quando il processo si interrompe.
Da quando hai creato kafka.service e zookeeper.service file, puoi anche eseguire uno dei comandi seguenti per arrestare o riavviare il server Kafka basato su systemd.
sudo systemctl stop kafka
sudo systemctl restart kafka
8. Ora esegui journalctl comando seguente per verificare che il servizio sia stato avviato correttamente.
Questo comando elenca tutti i log per il servizio kafka.
sudo journalctl -u kafkaSe hai configurato tutto correttamente, vedrai un messaggio che dice Started kafka.service, come mostrato di seguito. Congratulazioni! Ora hai un server Kafka completamente funzionante che verrà eseguito come servizi di sistema.

Limitazione dell'utente Kafka
A questo punto, il servizio Kafka viene eseguito come utente kafka. L'utente kafka è un utente a livello di sistema e non dovrebbe essere esposto agli utenti che si connettono a Kafka.
Qualsiasi client che si connette a Kafka tramite questo broker avrà effettivamente l'accesso a livello di root sulla macchina del broker, il che non è raccomandato. Per mitigare il rischio, rimuoverai l'utente kafka dal file sudoers e disabiliterai la password per l'utente kafka.
1. Esegui exit comando qui sotto per tornare al tuo normale account utente.
exit
2. Quindi, esegui sudo deluser kafka sudo e premi Invio per confermare che desideri rimuovere il kafka utente da sudoers.
sudo deluser kafka sudo
3. Eseguire il comando seguente per disabilitare la password per l'utente kafka. Ciò migliora ulteriormente la sicurezza della tua installazione Kafka.
sudo passwd kafka -l
4. Ora, esegui nuovamente il comando seguente per rimuovere l'utente kafka dall'elenco sudoers.
sudo deluser kafka sudo
5. Esegui il seguente su comando per impostare solo gli utenti autorizzati come gli utenti root possono eseguire comandi come kafka utente.
sudo su - kafka
6. Quindi, esegui il comando seguente per creare un nuovo argomento Kafka denominato ATA per verificare che il tuo server Kafka funzioni correttamente.
Gli argomenti Kafka sono feed di messaggi da/verso il server, il che aiuta a eliminare le complicazioni legate alla presenza di dati disordinati e disorganizzati nei server Kafka
cd /usr/local/kafka-server && bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic ATA
7. Esegui il comando seguente per creare un produttore Kafka utilizzando kafka-console-producer.sh sceneggiatura. I produttori di Kafka scrivono i dati sugli argomenti.
echo "Hello World, this sample provided by ATA" | bin/kafka-console-producer.sh --broker-list localhost:9092 --topic ATA > /dev/null
8. Infine, esegui il comando seguente per creare un consumatore kafka utilizzando il kafka-console-consumer.sh sceneggiatura. Questo comando consuma tutti i messaggi nell'argomento kafka (--topic ATA ) e quindi stampa il valore del messaggio.
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic ATA --from-beginningVedrai il messaggio nell'output di seguito perché i tuoi messaggi vengono stampati dal consumatore della console Kafka dall'argomento ATA Kafka, come mostrato di seguito. Lo script consumer continua a essere eseguito a questo punto, in attesa di altri messaggi.
Puoi aprire un altro terminale per aggiungere più messaggi al tuo argomento e premere Ctrl+C per interrompere lo script consumer una volta terminato il test.

Conclusione
Durante questo tutorial, hai imparato a configurare e configurare Apache Kafka sulla tua macchina. Hai anche accennato al consumo di messaggi da un argomento Kafka prodotto dal produttore Kafka, con conseguente gestione efficace del registro eventi.
Ora, perché non sfruttare questa nuova conoscenza installando Kafka con Flume per distribuire e gestire meglio i tuoi messaggi? Puoi anche esplorare l'API Streams di Kafka e creare applicazioni che leggono e scrivono dati su Kafka. In questo modo i dati vengono trasformati secondo necessità prima di scriverli su un altro sistema come HDFS, HBase o Elasticsearch.